




記憶容量をSRAMの数倍にできるFeRAM
ここからはプロセッサー内部に積層するメモリー素子の話である。プロセッサー内部で一番高速なメモリーはもちろんSRAMであるが、これは面積効率が悪い(なにせ1bit分で通常6トランジスタ、場合によっては8トランジスタのケースもある)。
もっと高効率で、しかも高速なメモリーが特にL2やL3に期待されているという話はご存じのとおり。これにはいくつかの候補となるデバイスがあるが、今回はここにFeRAM(強誘電体メモリー)を使う話である。
このFeRAMをLLC(要するにL3)に使えば大容量の3次キャッシュが実現できる、という話は以前からあったことであり、実際トランジスタが6~8個必要なSRAMに比べると、FeRAMは1つ溝と1個のキャパシタで構成できるので、面積あたりの記憶容量をSRAMの数倍にできる。
アクセス時間は10ns未満程度と少し遅いので、1次キャッシュやレジスターには不適当だが、LLCにはちょうど良い。ただ、Ramtronなどが実用化したFeRAM(こちらはFRAMという商標で販売されている)はプロセスが一般的ではなく、通常のCMOSプロセスとの親和性が低い。
なのでCypressや富士通はこれを外付け部品として販売しているし、MSP430というマイコンと組み合わせているTIは、がんばってこのFRAM用のプロセスでマイコン回路を実装するかたちで対処しているが、どちらもCMOSプロセスで製造するプロセッサーのLLCに使える技術ではない。
これに関しては、ハフニウム酸化物ベースの薄いフィルムをCMOSプロセスに組み合わせるという技法がすでに発表されており、こちらで実用に向けての研究が行なわれているが、今回の発表はこのFeRAMを3D積層することで、面積当たりの容量を大幅に増やすというものだ。

これは2018年の発表だが、他にも同様の発表がいくつも存在する。だからといって今すぐ量産CMOSプロセスで利用できるわけではない
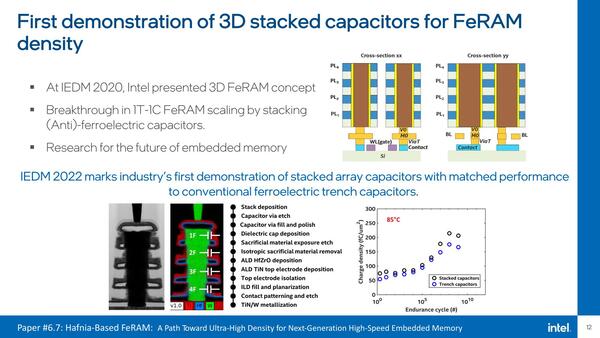
イメージ的には3D NAND Flashにやや近い(作り方や動作原理は少し違うが)
論文の中では試作した4bit/cellのFeRAMが、シングルセルのFeRAMと変わらない特性であることが示され、3D積層しても特性を悪化させずに容量増加を享受できることが示された。
次の13.1だが、こちらはそのハフニウム酸化物の薄いフィルムそのものの話である。
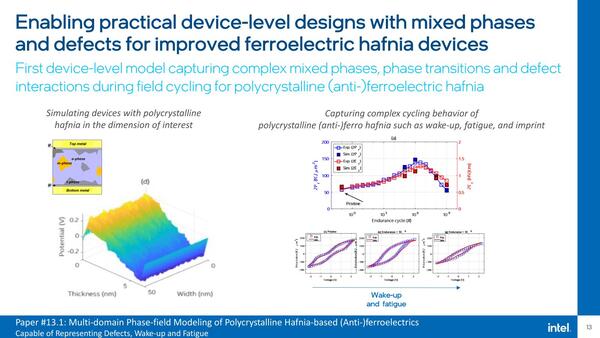
左の3Dモデルは、ハフニウム酸化物フィルムを利用したキャパシタのポテンシャル分布のシミュレーション。これは50nm幅のコンデンサの厚みを変えながら実験結果とシミュレーションを突き合わせ、結果が良い精度で合致したことを示す。右は電圧と分極の関係のシミュレーションと実験結果の突き合わせで、これも良い精度で合致したとしている
こちらはこれを使ってなにかを作ったという話ではなく、そのハフニウム酸化膜のモデルの構築と、そのモデルを利用した場合の計算が実際の測定結果と良く合うことを示し、デバイスのシミュレーションのための基礎を提供できるというもので、これも実際にFeRAMをプロセッサーに組み込む際には必要となるものである。
この連載の記事
-
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 - この連載の一覧へ



















の1台が今ならオトク!")


























")













