



遠藤諭のプログラミング+日記 第151回
大規模言語AIの実力と大規模SNS《Twitter》の憂鬱
超話題の人工知能ChatGPTに“小説”や“詩”を書いてもらい、“プログラム”は実行してみた
2022年12月07日 10時30分更新

Twitterが失われた場合の社会へのダメージははかり知れない
イーロン・マスク氏によるTwitter買収が2022年10月28日に完了。従業員の半数をただちに解雇、凍結アカウントを解除、残った社員にも激務に耐えるかやめるかを36時間以内に答えよとせまった。Twitterのこれからを心配する人も多い。
アラブの春に象徴されるように、ソーシャルメディアが、いままで声なき声といわれていたものを伝えるようになった。Twitterに関していえば、個人のささやかな気分から、世界規模の産業や文化、政治の行方までも左右するくらいの重要な役割を果たしているからだ。
英国BBCを見ていたらTwitterユーザーの一部が、Twitterに似た分散型マイクロブログ《Mastodon》というオタクなサービスへ引っ越していると伝えていた。私も、2019年11月に最後のポストをしてから使っていなかったアカウント(https://mstdn.jp/web/@hortense667)を復活させた。
非集中というものに意味があることをマスク氏のTwitter買収はあらためて教えてくれたのだ。2017年にインプレスから刊行された『iNTERNET magazine Reboot』で、そのあたりについて少し踏み込んで書かせてもらった(ココ参照)。非集中という意味で、《Web3.0》についても触れている。
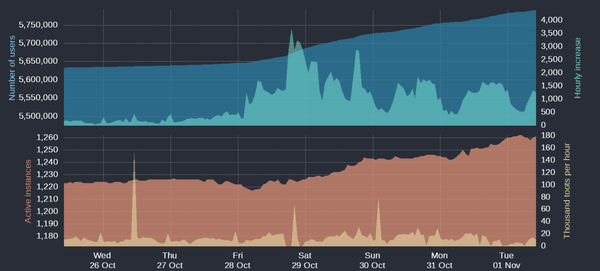
2022年10月28日、イーロン・マスク氏によるTwitter買収が完了すると同時にMastodonユーザーが増え始めた(@mastodonusercount@bitcoinhackers.orgより)
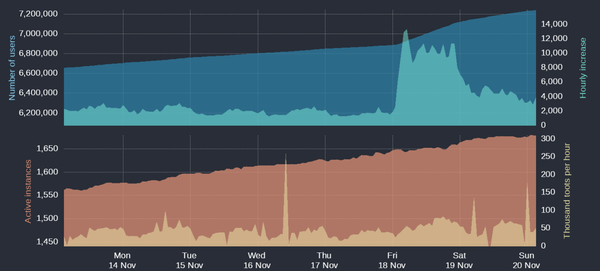
2022年11月18日、Twitter従業員に対するメールのあとMastodonユーザーが増加。その後もTwitterを揺るがすできごとのたびにMastodonユーザーは増加している。
Twitterもそう簡単にはサービスを停止しないだろう。Mastodonへの引越しも全体からすれば微々たるものだろう(100分の1とかそんな数字だ)。角川アスキー総研のTwitter全量解析の担当者によると、彼らが扱っている流入データはとくに増えても減ってもいないそうだ。
しかし、ヘイトグループが戻ってきているという指摘もあり内容は変質する可能性は十分ある。そこで、もしものときのために自分のTwitterのつぶやきの全記録を保存しておくのは意味がありそうだ。Twitterには、自分のアカウントをまとめてアーカイブとしてダウンロードする機能がある。
Twitterのアーカイブをダウンロードすると、《Your archive.html》というファイルができてローカルな環境でちょうど自分だけのTwitterみたいな使い方ができる。しかし、過去のつぶやきをエクセル形式で見れるようにしておくと一覧性の点でもとても便利だ。
そのためのプログラムを紹介したいと思う。
いま最も注目すべきテックワード《プロンプトエンジニアリング》
そこで、話題の人工知能であるChatGPTにプログラムを書いてもらえないかと考えた。1週間ほど前、OpenAI(人工知能の研究・推進のための非営利団体)が、ほぼ同時に2つの大規模言語モデル、《text-davinci-003》と《ChatGPT》を公開したのだ。
OpenAIといえば、人間と見分けがつかないレベルの発言を出力する《GPT-2》、《GPT-3》で注目を集めた。GPT-3に関しては、MITテクノロジーレビューが「GPT-3で号砲、大規模化に明け暮れた2021年のAIシーン」とまとめているとおりだ。
この記事のとおり、2021年が大規模言語モデルの年だったとすると、2022年は、テキストによる画像生成がクリエイティブ分野の未来に大きな変化を感じさせた年と締めくくってよい。OpenAIは、その世間を騒がせている自然言語による画像生成の先鞭をつけたシステムの1つ《DALL-E2》の提供元である(GPT-3を応用)。
私も画像生成はめちゃめちゃ興味があって、DALL-E 2の利用を申し込んだのだが、待機リストに入ったままだった(一説には100万人まで行列ができていたらしいから無理もない)。それが、今回の言語モデルは《ことば》の世界に新たな衝撃を与えていると話題だ。しかも、文章を生成したり、翻訳したり、必要な事柄をリストアップして示したりする。いわば、私が35年ほどそれで商売をしてきた編集者の仕事そのものではないか!
というわけで、今回の2つの言語モデルを触ってみることにした。
やり方は、割とハードルが低くてOpenAIのサイトにアクセスしてExampleというメニューをたたくと、49個ほどのベータ版アプリケーションがずらりと並んでいる。同社の言語モデルを使ったアプリを試せるようになっていて、だいたい学習モデルとして《text-davinci-003》が設定されている(ほかの学習モデルも選べるようになっている)。
OpenAIのサイトにならぶサンプルアプリケーションたち。同社の言語モデルを使って実にさまざまなことができる。
しかし、今回とくに試してみたいのはChatGPTのほうだ。ネットを見ているとすでにたくさんの人たちがChatGPTに触っていて、さまざまなことをAIとの会話によってやっている。
ChatGPTについては、それを試すためのページが用意されている。画面をみると、使用例として「量子コンピューティングをやさしく説明する」、「10 歳の誕生日にクリエイティブなアイデアはありますか?」、「Javascript で HTTP リクエストを作成するにはどうすればよいですか?」があげられている。

ChatGPTのお試し画面。中央に、使用例、機能、制限事項が書かれていて、いちばん下の入力欄からチャットに入る。
ためしに「Web3についてやさしい言葉で説明してください」と聞いたところ次のように返ってきた。
Web3とは、インターネットの新しいバージョンのことです。Web3は、以前のWeb1やWeb2と違い、より安全でプライベートな通信を実現する技術を採用しています。
Web3は、ブロックチェーン技術を活用しているため、ユーザー同士の通信やデータのやり取りが分散型で行われるため、より安全でプライベートな通信を実現しています。
また、Web3は、ユーザーがより自由にインターネット上の情報を利用したり、分散型アプリケーションを作成したりすることができるようになっています。
Web3はまだまだ発展途上の新しい技術ですが、将来的には、より安全でプライベートなインターネット環境を実現することが期待されています。
一説には、OpenAIが学習に使用しているデータにおける日本語の含有率は数パーセントだと言う。そこで、ほぼ日本語でしか議論されていないと思われるトピックとして、「昭和レトロとはなんですか?」と聞いてみる。
昭和レトロとは、昭和時代の文化や風景、そして物やものを意味します。「レトロ」とは、昔のものや、古いものを指す言葉です。
昭和時代は、1926年から1989年までの63年間で、日本が近代化を進め、経済が急速に発展した時期です。そのため、昭和時代は、今とは異なる文化や風景、物やものがたくさん残されています。
昭和レトロは、そうした昭和時代の文化や風景、物やものを、現代に残すことや再現することを指します。例えば、昭和時代のレトロな建物や街並み、昭和時代の物やものなどが、昭和レトロの代表的なものです。
昭和レトロは、今でも多くの人々に愛される文化や風景であり、今後もその魅力が残されることが期待されます。
なかなかのアウトプットではなかろうか? しかし、このように質問しているだけでは辞書を引いているのとあまり変わらないようにも思える。今夏注目を集めたテキストによる画像生成のようにクリエイティブなこともやらせてみたい。絵が描けるならオリジナルの文章も書けるはずである。
そこで、「パソコンとスマートフォンを擬人化してラブストーリーを書いてください」と言ってみた。すると、「このようなリクエストを受けたのは初めてですがやってみます」といったメッセージを出したあと、次のような小説を吐き出した。
ある日、パソコンはスマートフォンに出会った。パソコンはスマートフォンの色鮮やかな画面に一目ぼれし、スマートフォンもパソコンの大きな画面に惹かれた。
二人はすぐに恋に落ち、以後、よく一緒に過ごした。パソコンはスマートフォンに大切な情報を保存して、スマートフォンはパソコンにそれをアクセスさせることで、二人はより一層親密になった。
ところが、ある日、二人は別れをすることになった。その理由は、パソコンが大きすぎて、スマートフォンが持ち歩きにくかったことだった。
二人は悲しみに暮れる日々を過ごしたが、その後、二人は再び出会い、新たな愛を見つけることができた。今度は、二人は同じサイズのデバイスになり、お互いを信頼し合いながら、幸せな日々を過ごすことができるようになった。
なかなかシュールなお話で楽しいのだが、「二人は同じサイズのデバイスになる」という部分がいささか無理があるように思う。そこで、「パソコンとスマートフォンが同じサイズのデバイスになることはないと思うのですが」と返してみた結果は次のようなものだった。
実際には、パソコンとスマートフォンは同じサイズのデバイスになることはありません。パソコンは通常、デスクトップ型やノート型の大型デバイスであり、スマートフォンは携帯型のコンパクトなデバイスです。
ただし、この擬人化したラブストーリーはフィクションであり、現実世界ではそういったことはありません。このような擬人化は、物事を人間の感情や行動で理解しやすくするための一種の表現方法です。
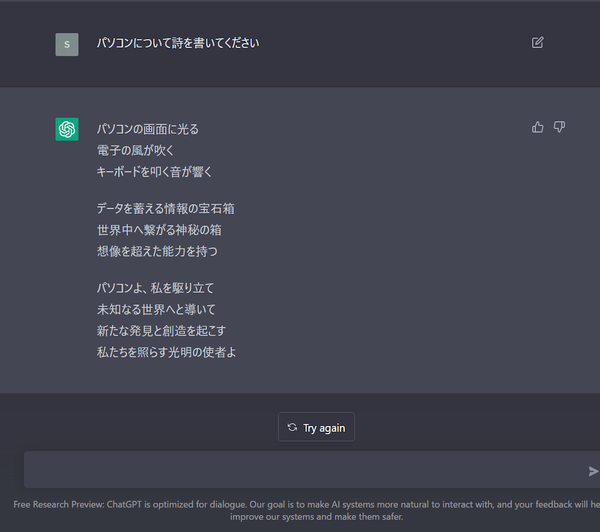
ストーリーが書けるなら詩も書けるはず。ということで、「南インドカレーのすばらしさを表現する詩を書いてください」と聞いてみると次のように返してきた。
南インドのカレーには
色鮮やかな香りが漂い
味わい深いスパイスが効いて
口の中で舌が楽しむ
その優しさと辛さが
心を満たしてくれる
南インドのカレーには
その生き生きとした風土が
詰まっているから
それはまるで私たちの国
インドの心を食べているよう
そして、私たちは
南インドカレーに惚れ惚れ
また食べたくなる
そんな美味しさなのです。
実は、こうしたチャットのやりとりでは、ちょっとした言い方の違いやタミングによって、その結果が大きく変わってきたりする。人工知能からの情報の引き出し方のことを《プロンプトエンジニアリング》と呼んでいる。やってみると、ちょっとしたゲームみたいな感覚だし、彼らが吐き出した結果を見るのは楽しい。
この詩では「南インドカレーに《惚れ惚れ》」というくだりが、なんとも人工知能とは思えない人間くささがあっていいと思う。そこで、そんなに《惚れ惚れ》ならというわけで、「日本でいちばん美味しいカレーはどのお店のカレーでしょうか?」と聞いてみた。それに対する答えは、次のようなものだった。
日本でいちばん美味しいカレーはどのお店のカレーでしょうか?そのようなランキングはありませんので、おすすめのカレー店は人それぞれです。カレーの好みは人によって異なりますから、一概には言えません。また、カレーのおいしさは、お店や料理人の技術だけではなく、食材や調味料、作り方などさまざまな要素が関係しています。お店を選ぶ際は、口コミやお店の雰囲気なども参考にしてみてください。
なんでも答えてくれるのかと思ったら、なんと回答を拒否されてしまった!
実は、しばしばChatGPTでこんなことができるよと紹介されていることの多くは、先ほど紹介したサンプルアプリケーションのtext-davinci-003を使ったチャットでもできる。会話だけでなく、メモから読みやすいレストランレビューを書いたり、プログラムのコードに関することもなども含めてだ。
それでは、ChatGPTは、どこに特徴があるのかというと返答のグレードが高いことももちろんあるのだが、今回使っているページに「性能」(Capabilities)としてあげられていることだ。つまり、「ユーザーが以前の発言を覚えている」、「ユーザーがフォローアップ修正を提供できる」、「不適切な要求を拒否する」の3つである。
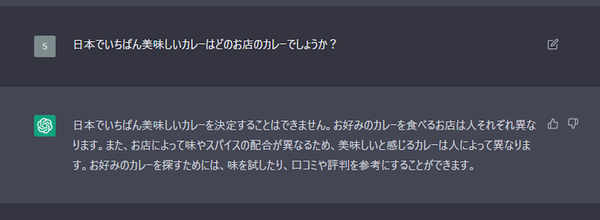
なんでも答えてくれると思ったChatGPTに回答を拒否されてしまった! 実は、ChatGPTの紹介に出てくるたいていの事例はこれ以前の言語モデルでも可能で、この制限事項がChatGPTの大きな特徴らしい。
これらは、チャットのために特化したというChatGPTが、さまざまリスクを回避したいからだろう。大規模言語モデルを使った人工知能では、それが男性偏重であるとか差別を助長すると指摘される。最近の事例では、メタが2022年11月15日に公開した大規模言語モデル《Galactica》が、偏見や虚偽が多いと批判され、わずか3日で公開中止となっている。
Twitterのアーカイブをtsv形式で吐き出してエクセルで読む
さて、今回の本題であるChatGPTによるプログラムのソースコードに関することだ。GPT-3で、すでに十分に注目されていてこれも先ほどのサンプルアプリケーションでも、「JavaScriptからPythonへの変換」、「PythonにDocstring(説明文)をつける」、それから「コードを生成する」といったことなどが行えた。
しかし、text-davinci-003などをもとにさらに進化させたChatGPTではどんなプログラミングができるのか? 試しに「Twitterのアーカイブを読んでtsv形式で書き出すプログラムを書いて」と頼んでみた(Twitterのアーカイブとは1つのアカウントの過去の全つぶやきデータ)。
最初、ChatGPTは、「残念ながら、具体的な方法はわかりませんが、Pythonを使用してTwitterアーカイブデータをtsv形式で書き出すことは可能です。」とプログラムを書くことをシブってきた。しかし、ちょっとしたヒントを与えてやると、プログラムを書いてくれた。それは次のようなものである。
import json
import csv
with open('twitter_archive.json', 'r') as f:
archive_data = json.load(f)
with open('output.tsv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f, delimiter='\t')
for tweet in archive_data:
# ツイートのテキストを書き出す
writer.writerow([tweet['text']])
このコードと同時に「上記のプログラムでは、json形式のアーカイブデータを読み込んで、そのデータをtsv形式のファイルに書き出すものです。必要に応じて、書き出すデータを変更することができます。」という説明文も書き出してきた。
プログラマーの方ならご存じのとおり、json形式のデータ(Twitterのアーカイブがまさにこの形式である)を読み込んで、tsv形式として吐き出すコードは誰が書いてもこんなものになる。
私は、一昨年まさにこれを実行するプログラムを書いて記事で紹介した。「Twitter自分の全ツイート履歴をダウンロード――オンラインではできないDM検索もやってみた」である。それは、次のようなコードだった(アーカイブのファイル名のみ変更してある)。これと、ChatGPTが吐き出したコードをよく比べてみてほしい。少し複雑になっているが、ほぼ同じ構造をしている。
import json
from dateutil.parser import parse
from pytz import timezone
import re
import sys
import io
import codecs
with codecs.open('tweets.js', 'r' , 'utf-8', 'ignore') as f:
data = f.read()
tw = json.loads(data[data.find('['):])
f = open('tweet.tsv', 'w', encoding="utf_8_sig")
for t in tw:
s = t['tweet']['full_text']
e = t['tweet']['entities']
if 'urls' in e:
for u in e['urls']:
s = s.replace(u['url'], u['expanded_url'])
c = parse(t['tweet']['created_at']).astimezone(timezone('Asia/Tokyo')).strftime("%Y-%m-%d %H:%M:%S")
s = s.replace("\n", " ")
s = s.replace("\r", " ")
s = "https://twitter.com/hortense667/status/"+t['tweet']['id']+"\t"+c+"\t"+t['tweet']['retweet_count']+"\t"+t['tweet']['favorite_count']+"\t"+s+"\t\n"
f.write(s)
f.close()
しかし、ChatGPTが吐き出したコードがそのまま動くのかというとそうではない。Twitterのアーカイブデータの構造にきちんと対応していないからだ。そこで、「Twitterのアーカイブデータの構造を調べてプログラムを修正してくれませんか?」とお願いしてみたのだが、「Twitterのアーカイブデータは、ツイートごとに1つのデータとして格納されています。1つのツイートデータは次のような構造になっています。」というメッセージとともに、具体的なjson形式のサンプルデータを表示してきた。
なんだデータ構造を知っているではないか? ということで、「Twitterのアーカイブのデータ構造がわかるんなら、それを反映してTwitterのアーカイブデータをtsv形式にして書き出すプログラムを書いて」と言ったところ、次のようなコードを書き出してきた。
import json
import csv
with open('twitter_archive.json', 'r') as f:
archive_data = json.load(f)
with open('output.tsv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f, delimiter='\t')
for tweet in archive_data:
# ツイートデータを取得する
created_at = tweet['created_at']
id_str = tweet['id_str']
text = tweet['text']
truncated = tweet['truncated']
source = tweet['source']
in_reply_to_status_id_str = tweet['in_reply_to_status_id_str']
in_reply_to_user_id_str = tweet['in_reply_to_user_id_str']
in_reply_to_screen_name = tweet['in_reply_to_screen_name']
user = tweet['user']
user_id = user['id']
user_id_str = user['id_str']
user_name = user['name']
user_screen_name = user['screen_name']
user_location = user['location']
user_description = user['description']
user_protected = user['protected']
user_followers_count = user['followers_count']
user_friends_count = user['friends_count']
user_listed_count = user['listed_count']
user_created_at = user['created_at']
user_favourites_count = user['favourites_count']
user_statuses_count = user['statuses_count']
user_lang = user['lang']
# tsv形式で書き出す
writer.writerow([created_at, id_str, text, truncated, source, in_reply_to_status_id_str, in_reply_to_user_id_str, in_reply_to_screen_name, user_id, user_id_str, user_name, user_screen_name, user_location, user_description, user_protected, user_followers_count, user_friends_count, user_listed_count, user_created_at, user_favourites_count, user_statuses_count, user_lang])
今回も説明文がついていて「必要に応じて、書き出すデータを変更することができます。」と書かれている。ということで、これをひとまずChatGPTが書いてくれたプログラムということした。というのは、どうしてもいくつかこちらで手を入れないといけない部分があると思ったからだ。
人工知能がコードを吐き出してくれると、まるで友だちや同僚のような親近感を覚えるようになる。なので、人工知能の吐き出したコードを評価してしまいたくなるのだが、それを差し引いても、ここまでやってくれたら助かることは多いと思う。このコードに、私が手を加えたのは次のようなことだ。
まず、Twitterは、アーカイブデータのjsonの構造を定期的に変更していて、これは少し古い形式のようである。ChatGPTは、学習モデルが作られた以前の情報は対応できないと制限事項でうたっている。必ずしもそのためではないが、このままでは動かない。そのために、現在のデータ構造にあわせて若干修正。
次に、アーカイブデータを読み込んでリストに展開する部分を書き換えさせてもらった(アーカイブの先頭についている不要な文字をカットする必要があるなどの理由だ)。そして、自分が欲しい項目、「つぶやいた日時」、「ツイートID」、「つぶやき内容」、「リツーイトされた件数」、「いいねされた件数」と「参照しているURL」を出力することにする。
ChatGPTが書き出したPythonプログラムに、以上の3点の修正を加えたプログラムが以下だ。
import json
import csv
import codecs
with codecs.open('tweets.js', 'r', 'utf-8', 'ignore') as f:
data = f.read()
archive_data = json.loads(data[data.find('['):])
with open('output.tsv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f, delimiter='\t')
for tweet in archive_data:
# ツイートデータを取得する
created_at = tweet['tweet']['created_at']
id_str = tweet['tweet']['id_str']
text = tweet['tweet']['full_text']
# 参照しているURLを追加
e = tweet['tweet']['entities']
if 'urls' in e:
for u in e['urls']:
text = text.replace(u['url'], u['expanded_url'])
retweet_count = tweet['tweet']['retweet_count']
favorite_count = tweet['tweet']['favorite_count']
# tsv形式で書き出す
writer.writerow([created_at, id_str, text, retweet_count, favorite_count])
このプログラムを走らせると、私の2007年5月10日の最初のポストからダウンロードした2022年11月21日までの全ツイート、48,263件をtsv形式で出力することができた。ちなみに、プログラムの修正にかかったのは本当に10分かそこらである(似たようなプログラムを書いたことがあるのはたしかだが)。
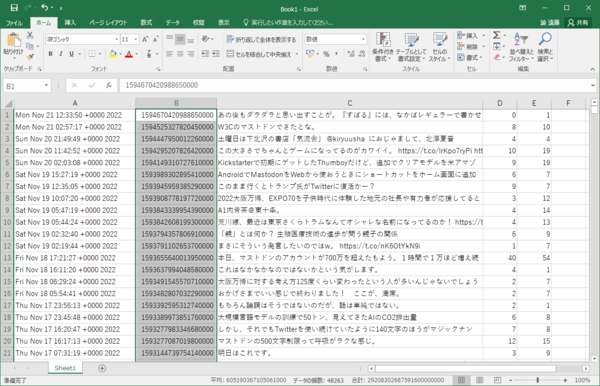
私の全ツイートのアーカイブをChatGPTが書いたプログラムを若干手直ししたものの実行。結果を目的どおりExcelに読み込んだところ。なお、Twitterアーカイブは、必ずしもポストされた日付どおりに並んでいない。
プログラマーの方ならここまでのやりとりは既視感のあるものだろう。仕事の先輩に「こんなときどうするんですか?」と質問すると、「しょうがないなぁ」なんて言いながら「こんなふうにやるんだよ」と親切に教えてくれる。いわゆる《ペアプログラミング》の世界だともいえる。逆にいえば、先輩や同僚は、自分が書くべきコードをすべて書いてくれるわけではない。間違いが含まれることもあるだろう。

人工知能のチャット画面が「~をするPythonコードは次のようになります」とスルスルと語るようすはなかなかSFだ。実際のChatGPTとのやりとりはこのように進んだ。
どんなときにChatGPTにコードを書いてもらうといいのか? ひとことでいうと、自分でも書けそうなものを手間をかけずに書くというような使い方だ。たとえば、デジカメ画像の撮影日付やカメラ機種を書き出すプログラムを書くとき、いままでならExif情報のフォーマットを調べる必要があった。
このくらいのことなら、ChatGPTはさらりとコードを出力してくれる。「引数で渡されたパス以下のすべてのデジカメ画像について、ファイル名、撮影日時、カメラの機種を一覧出力するプログラムを書いて」とお願いした結果は、以下のコードを出してきた。これに、エラー処理を盛り込んでほしいなど希望を出していくことも可能だ。
from PIL import Image
import os
import sys
root_dir_path = sys.argv[1]
for dir_path, dir_names, file_names in os.walk(root_dir_path):
for file_name in file_names:
# 画像ファイルのフルパス
file_path = os.path.join(dir_path, file_name)
# 画像ファイルを読み込む
img = Image.open(file_path)
# 画像からExifデータを取得する
exif_data = img.getexif()
# 撮影日付を取得する
date_time = exif_data.get(0x9003)
# カメラの機種を取得する
camera_model = exif_data.get(0x0110)
# 画像ファイル名、撮影日付、カメラの機種を表示する
print(img.filename)
print(date_time)
print(camera_model)
人工知能は、我々のふだんの生活にとって必要不可欠になる
いままでヒトという唯一の種が独占してきた《ことば》というものが、必ずしも独占物ではなくなってきたのだといえる。その人工知能と呼ばれるものが、本当にモノを理解しているかとか意識を持ちうるかという議論はさしおくとして、《ことば》は、機械をとおしてわれわれをより豊にするものになりそうだ。
これは、《ことば》にとって、印刷に匹敵する一大イノベーションなのではなかろうか?
GPT-3がやっているのは、ひたすらいま手にしている文章の次にはどんな文章がくるのかを予測するということだそうだ。それをやっていたら、なんとなく本当に知能ができたように錯覚しはじめたのがいまだと思う。そしてそれは、知能の本質なのではないかという気さえしてくる。
ただし、OpenAIのGPT-3で注意深くみておくべき点は、その言語能力もさることながら、それがどのようにして成り立っているかだ。それは、Googleとトロント大学が2017年に開発した《Transformer》と呼ばれるニューラル・ネットワークをもとにしており(そもそも、GPTとは“Generative Pre-trained Transformer”の意味だ)、ひたすら《大規模化》によってなしとげられている。
説明するまでもなく、ヒトは、そこまで大量のデータを読み込むことなしに知識や言語能力をみにつけている。
それでも、こうした人工知能がいま我々が手にしているスマートフォンや検索エンジンと同じように、我々の生活にとって必要不可欠になるのは確実だと思う。彼らは、ふだん我々のまわりにいる家族や友人や同僚のような存在になるかもしれない。
遠藤諭(えんどうさとし)

株式会社角川アスキー総合研究所 主席研究員。プログラマを経て1985年に株式会社アスキー入社。月刊アスキー編集長、株式会社アスキー取締役などを経て、2013年より現職。角川アスキー総研では、スマートフォンとネットの時代の人々のライフスタイルに関して、調査・コンサルティングを行っている。「AMSCLS」(LHAで全面的に使われている)や「親指ぴゅん」(親指シフトキーボードエミュレーター)などフリーソフトウェアの作者でもある。趣味は、カレーと錯視と文具作り。2018、2019年に日本基礎心理学会の「錯視・錯聴コンテスト」で2年連続入賞。その錯視を利用したアニメーションフローティングペンを作っている。著書に、『計算機屋かく戦えり』(アスキー)、『頭のいい人が変えた10の世界 NHK ITホワイトボックス』(共著、講談社)など。
Twitter:@hortense667この連載の記事
-
第168回
トピックス
オープン直前の新「マイコン博物館」におじゃまして展示品や施設を案内してもらった! -
第167回
トピックス
Googleの始め方――スタートアップをいちばん知っている人物が語る3つの条件とは? -
第166回
トピックス
女子大生が100日連続で生成AIで100本のプログラムを書いたらどうなったか? -
第165回
トピックス
生成AIも体験して学ぶ「AIのアイ」展がはじまった! -
第164回
トピックス
新しくなったChatGPTにできること、できないこと -
第163回
トピックス
日本にはコンピューター博物館が必要だ! 青梅の新「マイコン博物館」のクラファンがスタート -
第162回
トピックス
遊べるWebサイトを240秒で作る方法――DeployScriptを試そう -
第161回
トピックス
情報理論の父クロード・シャノンとChatGPTによる完全パングラムの生成 -
第160回
トピックス
アルファベット26文字をすべて使ってできるだけ短い文を作る with ChatGPT -
第159回
トピックス
最短15分! ChatGPTに自分の過去原稿を合体して“自分GPT”を作る -
第158回
トピックス
ChatGPTの新機能コードインタープリターに《未来の仕事の全自動化》が見える - この連載の一覧へ











が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")













