




2023年夏までのChatGPTといまのChatGPTはまるで違うんだよ
『Kotoba/ことば』53(2023年9月6日発売)を読んでいたら、特集「萌える言語学」Part.3に、“AI研究と対峙する言語学”という記事があった。国立国語研究所准教授の窪田悠介氏が、このChatGPTの出現に対して「ほとんどの言語学者は一様に沈黙を保っている。気味が悪いほどの沈黙である」と書いている。そして、それについて「我々言語学者には、専門家として世の人の持つ疑問に答える責任があるのではないか?」とも述べている。
ちょうど1年前の2022年11月30日にリリースされた、人間とほとんど見分けがつかない会話をするChtGPTの出現は、言語の専門家からしたら悪い夢のようなものだろう。窪田氏は、「ある意味、この方面の研究において言語学者にはもはや出る幕がないのである」と言い切っている。また一方、「人間より流暢に言語を話す機械が世に現れたからといって、人間が実際にどのように言語を話しているかが解明されたわけではない」とも書いている。
たしかに、言語がそれっぽくなったからといって、それはスクラブルのようなパズルゲームができるようになっただけのような気もする。言語といえば、コンピューターならJavaやPythonなど、機械が分かる命令に翻訳してやる通訳のようなものである。逆に、その程度のことができただけで、ChatGPTが「人間と見分けがつかない」とか「役に立つアドバイスをしてくる」とか「抒情的な詩を作ってくれる」というのは不思議なことに見える。
実のところ、人間なんかいてもいなくても、言語というのはそれだけでよほど立派なネットワークとしてできている。我々の知らないところで、ある言葉が別の言葉に議論をふっかけていたり、ある言葉は感傷にふけっていたり、別の言葉は知識をひけらかしてまわりに迷惑をかけていたり、反応したくてウズウズしながら存在しているのだ。
さて、そのChatGPTだが、2023年夏頃には新聞・テレビなどで大きく注目を集めた。しかし、その夏以降、秋までに多くの機能が加わっているのをご存じだろうか? 次の表は、OpenAIのリリースノートから主要なトピックを拾い上げたものだ。こうした新機能には有料版だけで使えるものも少なくないから、ChatGPTは、無料版と有料版(さらに企業版も加わったが)のユーザーでは、まるで違うものを語っていることになるので注意が必要だ。

そして、この後は2023年11月6日、OpenAIが初めて開発者会議を開催。ChatGPTは、そのリリースから約1年で大きく刷新されることになった。すでにその新しくなったChatGPTを使いこんでいる人も少なくないと思うが、それは、この表にある秋までに追加された機能を統合してサービスとして整理したものだといえそうだ。
1年前のChatGPTのリリース以降では、いちばん基本的なところでの変化は、言語モデルGPT-4である。次のグラフは、GPT-4が、言葉のネットワークのパラメーターの数を飛躍的に増やしたものであることがわかる。GPT-4によって、ChatGPTがとても賢くなった。その根源は、“数”だった。GPT-4について詳しく知りたい人は、GPT-4 Technical Reportを見るとよい。

新しくなったChatGPTは、これにGPT-4Vによる視覚能力などマルチモーダル化、GPT-4 turboによるプロンプトの長さや応答性などと同時に提供されたものである。
ChatGPTにできること、できないこと
サイエンス映像学会というところで「ChatGPTにできること、できないこと」というお題でお話をさせてもらった。伊藤博文さんに、ChatGPTがプログラムを 書いて実行してしまうこと、与えたデータを解釈してパワーポイントが作れることなどを紹介してほしいといわれてのことだ。それなりに、現時点でのChatGPTを説明できていたと思うので、そのときのスライドから何枚か紹介したいと思う。

なんといっても、ChatGPTで問題にされるのが、平気でウソをいうことである。「幻覚」(ハルシネーション)と呼ばれるが、自分が、どこまで知っているのかが分かっていない。このあたりに興味のある人は、「OOD検知」(Out-of-Distribution)というキーワードで調べてみるのもよいでしょう。

次にやはり課題とされる「ドリフト」の問題。Bingが、5回以上の対話をさせないようにしているのもそのためだろう。会話を続けると混乱して結論への道筋が見えなくなる。OpenAIとDeeplearning.aiによる開発者向けのプロンプト講座では、なんと「ChatGPTを使うな!」と指導している。対話ではなく単発で目的なものが求められるようプロンプトを修正して作り上げることを推奨しているのだ。

ChatGPTが画期的なのは、サンプルを与えることで回答の精度が圧倒的に上がることだ。「Few-shot prompting」と呼ばれるテクニックで、人が人に教えるときのような「こんなふうに」というやりとりになる。これは、70年におよぶコンピューティングの歴史の中でもパラダイム転換といってよい出来事だと思う。孤独なデスクワークの作業に性格のよい仲間ができてゴルフのレッスンみたいなやり方になった。

ChatGPTの技術の応用として、世界的に最も期待されているのが、独自データを使ったチャットBOTだろう。企業は、顧客サポートや営業、社内ルールの問い合わせシステムなどで活用できる。スウェーデンやデンマーク、エストニア、ラトビアなどでは、行政窓口でチャットBOTが運用されている。ChatGPTの会話力をそうした分野で応用したいというものだ。
言語モデルに独自のデータを追加学習させるのはファインチューニングをする必要があるが、その手間をかけることなく、外部企業などがChatGPTに独自データを追加学習させたかのようにふるまわせることができる。llamaindexというフレームワークなどが使われている。
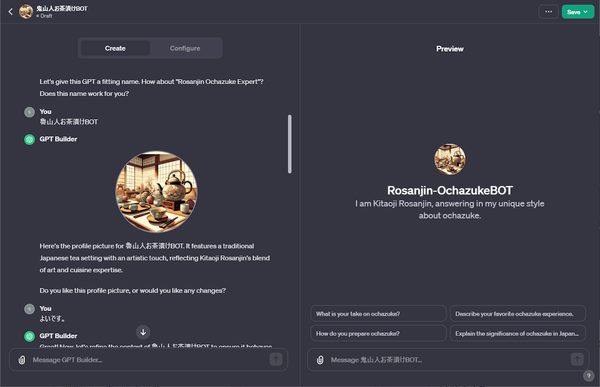
私も、北大路魯山人のお茶漬けについて述べている文章をもとに答えるチャットBOTを作ってみた(rosanjin_OchadukeGPT)。詳しくは、「ChatGPTに接続して魯山人に《お茶漬け》について教えてもらう」をご覧あれ。

この魯山人のお茶漬けBOTは、おおむね以下の図のような動きをする。あらかじめ魯山人の文章をベクトル化しておく(これをエンベディングと呼んでいる)。これにより、ユーザーから「天ぷら茶漬けについて教えて」と問い合わせされたときに、魯山人の文章の中で関係しそうな部分をすみやかに取り出す。その関係しそう(魯山人が天ぷら茶漬けに言及している)部分と「天ぷら茶漬けについて教えて」という問い合わせ内容をセットにして、ChatGPT(正確にはOpenAIのAPI)に投げてやる。

これは、なかなか賢いアプローチでお金も手間もかけずに(本当にコアの部分は十数行で書けてしまう)、それらしいBOTや問い合わせシステムを作ることができる。ちょっとしたカンニングをChatGPTにやらせるわけだが、プログラムの中に短期記憶的な仕組みを入れるなど、さまざまな工夫もされていて注目の分野だった。
11月6日の開発者会議で公開された「Assistant API」は、こうした独自データに答えるためのしくみをより高度に実現できるようにしたものだ。会話の流れもより自然なものとなっている。そして、これが新しくなったChatGPTの機能の中でも最も話題となっている「GPT」の背後で動いていると考えられる。
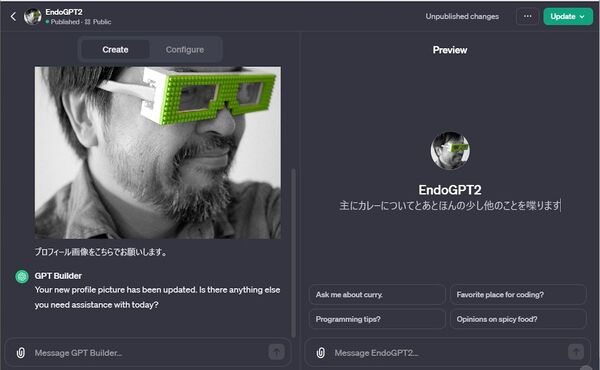
そこで、魯山人のお茶漬けBOTで与えた同じデータを使って新機能のGPTを作ってみた。なんといっても、有料ユーザーなら誰でも一切のコードを書く必要もなくオリジナルのChatGPT(GPT)が作れるのは画期的なことだ。まだベータ版だがCreate a GPTのメニーから対話するだけで、ものの15分でできてしまった。しかも、これがストアで公開され流通するというのだからビジネスチャンスと捉える人も多いだろう。
私が、1987年から1993年頃にかけて『月刊アスキー』に連載した『近代プログラマの夕』(1、2)の中からカレーやハッカーについての文章をもとにしたGPTも作ってみた。これの延長線上には、過去の自分と対話しながら原稿を書くようなことがあり得ると思う。
・魯山人のお茶漬けBOT
https://chat.openai.com/g/g-QUVPcvZC7-rosanjin-ochazukebot
・EndoGPT-2
https://chat.openai.com/g/g-SXZBcxdic-endogpt2

ChatGPTの現状での最も効果的な使い方の1つが、プログラムのコード生成だろう。このスライドではABC Website Makerというプラグインを使ってあっという間にWebサイトができて公開できると書いているが、それは、ほんの手始めみたいな話である。
日本語で「こんなプログラムを書いてほしい」といえば、ChatGPTは、ほぼあらゆるプログラミング言語のコードを吐き出してくれる。米国には、1960年代のミニコンピューターであるPDP-8/Eのアセンブラでプログラムを書かせてエミュレーターで動かしたという人もいるらしい。
ChatGPTによるコード生成が素晴らしいのは、コードを生成する時になぜこのようにコードを書いたのか解説してくれたり、古いコードをリファクタリングしてくれたりすることだ。また書き出したコードを実行してエラーが出たと言えば、「申し訳ありません」などと謝罪しながら何度でもコードの修正をしてくれる。
マイクロソフトのサティア・ナデラCEOは、MITテクノロジーレビューのインタビューで「生成AIによってプログラマーの仕事は変わり、10億人の開発者が何かを生み出し、そのほとんどがコーディングの経験がないという状況」を想像していると述べている。

これは、私が、ChatGPTに書いてもらった落下型ゲームだ。矩形を作ると消えるというゲームルールで動いている。

このゲームを作るときに与えたプロンプトは、こんな感じである。ChatGPTにコードを書かせるためのノウハウは、さまざまな形で蓄積されつつあると思うが、非手続き的に書けることがすばらしいのだが、手順を分解して説明すべきこともある。ともあれ、慣れてくると、2、3時間の試行錯誤でこのくらいのプログラムを書き出して動かすことができる。

7月にChatGPTにこの機能が加わったときに、私は、「ChatGPTの新機能コードインタープリターに《未来の仕事の全自動化》が見える」という記事を書いた。 国政調査による人口データのCSVファイルと、国土地理院の都道府県別の面積がわかるエクセルファイル、そして、ドン・キホーテンの公式ページにある店舗一覧という3つのデータを与えて、ドンキの強い県・弱い県についてのパワーポイントを自動的に作ってもらったのだ。詳しくは、記事を見てほしい。
ホワイトカラーの仕事は、いまのところ限定的にだが、着実に生成AIにとって代わられていくと考えられる。あらゆる仕事は単独で成立しているのではない。OpenAIは、ウェブアプリを連携して自動化することにも前向きである。

ChatGPTがマルチモーダル化したことで図を与えることができるようになったが、言語に比べるとまだ発展過程にある。
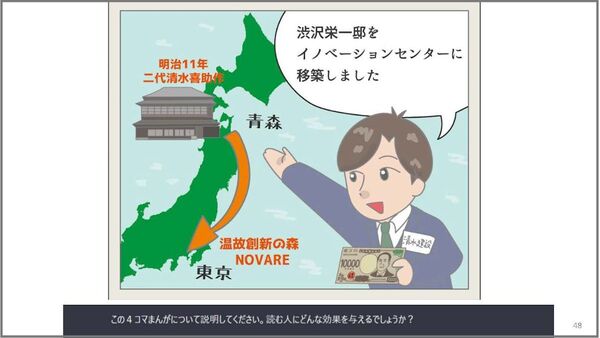
これは、ASCII.JPにある記事「清水建設がイノベーション拠点のどまんなかに「旧渋沢邸」を置いたワケ」という記事に収録されている4コマ漫画の1コマである。この漫画について説明を求めたところ、次のように解釈したと返ってきた。
- 背景の地図のテキスト: "第11銀行"、"新通貨両替銀行"、"東京"。
- 矢印: "新銀行の方向"。
- キャラクターのセリフ: "新通貨両替銀行に10,000円札を持って行きました。"
- 札のテキスト: "10,000円"。
4コマ漫画のうちの1枚を説明するというのは、なかなか難しい課題だったとは思う。しかし、例によってどんどん勝手な解釈をしてしまっている。彼がどのように勘違いしたかを眺めてみるのは、なかなか興味深い。お札と建物の絵があれば銀行なのか? お札の持ち方が両替なのか?

ChatGPTが、数学が苦手であることはよく知られていることだ。前述のOpenAIによるリリースノートを見ると数学能力の向上をうたったりもしているが、現時点ではなかなか厳しい。次のような問題は、ふだんこの種の計算を必要としない私のような人間には、ChatGPTにスパッと解いてほしいのだが。

なぜこんな問題を解いてほしいと思ったのかというと以下の図の右側のようなCADデータの円弧の部分を作るための正確な数値がほしかったからだ。そのために、左のような図形の問題を解きたかったわけである。

ところが、何回もプロンプトを工夫しなおしてもなかなか答えにたどりつかない。そこで、どんなふうに問題を理解したのか図にしてほしいと聞いたところ出てきたのが次の図である。

これでは、いつまでたっても正しい答えにたどり着かないはずである。そこで、先ほどの手書きのスケッチをアップロードして、ベータ機能の「高度なデータ分析」(Advanced data analysis)をオンにしてやると、ようやく最終的に答えにたどりつくことができたようだ。

DALL-E3による描画機能があるのでケーニヒスブルグの橋を描いてもらおうとしたがうまくいかなかった。Webブラウジングが可能になったのでそれ自体の意味は書き出してくるわけなのだが、それは、あくまで文としてアウトプットされるだけであることが分かる。

「ケーニヒスブルグの橋を説明する日本のマンガ風のイラストを作ってください」とプロンプトを与えると、「こちらがケーニヒスブルグの橋を説明するマンガ風のイラストです。どのイラストがお気に入りですか?」と言って表示してくれたのが次の図である。

これでは話にならないので、「トポロジー的にケーニヒスブルグの橋と同じくなっている絵にしてください」とプロンプトで返してみると、「了解しました。ケーニヒスブルグの橋のトポロジーを正確に反映したマンガ風のイラストを作成します」と例によってさわやかな言葉を返してくるのだが、出てきたのが次の図である。この絵のタッチ、私は嫌いではないのだが、説明図としては失格である。

ちなみに、コンピューターで解くのが大変な「巡回セールスマン問題」をChatGPTに与えてみたのだが、6個程度のポイントを巡る簡単な問題は解いてくれた。これは、アルファベット26文字すべてを使ってできるだけ短い文を作るパングラムで感じたのに近い感覚である。難易度をあげた場合、一般に知られている手法を探しだしてきて「高度なデータ分析」によって計算をすることで求めようとする。ChatGPTに巡回セールスマン問題が解けるのか? ということに関しては、割とできる人間のプログラマと同じ程度にアプローチすることはできる。
自分で数学的な手法を応用するよりも既知のアルゴリズムをあてはめるほうがうまい。ChatGPTは、文系プログラマである。

いま個人的にとても興味のあるテーマの1つが「クロスモーダル」である。クロスモーダルというのは、異なる五感の相互作用のことで、ビールを注ぐ音がよいと味もおいしく感じるような現象のことだ。米国では皮膚の振動で音を聞く、リストバンドの形をした補聴器や耳鳴り軽減デバイスが発売されているらしい。
私は、ほとんど写真だけで95%くらいの確率で自分の好みのカレーかどうかわかるつもりである。ChatGPTも、そんな能力があってもおかしくない。カレーの画像の近くには、その特徴や、それを評価する文が埋まっていることが多いと考えられるからだ。

しかし、この写真を与えて聞いた結果は、「私のトレーニングデータには味を判断する能力は含まれていませんので、具体的な経験や味の評価は提供できません。お近くの方やレビューを参考にしてみてください。」とそっけない答えしか返ってこなかった。
映画『マイノリティレポート』のように、人相からその人の行動を予測する研究はChatGPT以前から行われている。しかし、ChatGPTは、画面内の人々についてのチャットはサポートしていない。ChatGPTは、バイアス、偽情報、過信、プライバシー、サイバーセキュリティ、急激な拡散などのリスクのあることは答えない。このあたりの安全性についてどのような対応をしたかについては、前述のTechnical Report で触れられている。
マルチモーダル化とカスタム化を中心に基礎から学ぶ
さて、ここからはお知らせなのだが、ここまでの原稿で触れた2023年夏以降にChatGPTに追加された機能についてのセミナーである。11月24日(金)18:00~21:00 に丸山不二夫氏を講師に「ChatGPTはどう変わろうとしているのか -- マルチモーダル化とカスタム化を中心に基礎から学ぶ」を開催する。
丸山不二夫氏には、定員100人を5回追加開催した人気のAI講座をやっていただいた経緯がある。今回のセミナーでも、新しくなったChatGPTの機能やAPIをフル活用するにあたって、あるいは、今後のビジネスの方向性を考える上で重要となるChatGPTの技術的背景を学ぶというものである。
たとえば、ChatGPTが視覚を持つことは、2021年のGoogleによるVison TransferやOpenAIのCLIP(Contrastive Language–Image Pre-training)をみていれば予想できたものだ。次々にリリースされる内容に追いまくられるのではなく、ChatGPT、あるいは生成AIの方向性をとらえることが大切である。
セミナーの構成
第一部 大規模言語モデルの成立とChatGPTの成功の背景
・AttentionメカニズムとGoogle機械翻訳
・TransformerとBERT
・ChatGPTとReinforcement Learning from Human Feedback
第二部 AIのマルチモーダル化の進行
・Google Vision Transformer
・OpenAI CLIP: Connecting text and images
・Natural Language Supervision
第三部 AIのカスタム化の動向
・GPT-4の新しいAPIを見る
・GPT4-fine-tuning, Custom Model
・Agent-Based Model
質疑応答
・問題提起と司会 角川アスキー総研 遠藤諭 氏
※丸山氏より。「AIの未来展望については、非常に楽観的なものですが、11月23日に開催される日本Androidの会のイベントABC Autumn での丸山の基調講演「Be My AI !」でお話させていただく予定です」とのこと。
講師:丸山不二夫(まるやま・ふじお)
東京大学教育学部卒業。一橋大学大学院社会学研究科博士課程修了。数理哲学者で教育者。稚内北星学園大学学長、早稲田大学大学院情報生産システム研究科客員教授、はこだて未来大学システム情報科学部特任教授等を歴任。オープンソースのコミュニティ活動に積極的に参加。日本Javaユーザー会名誉会長。日本Androidの会名誉会長。クラウド研究会代表。近年では、日本のIT業界がグローバルな技術イノベーションの一翼を担うことを目標に、連続講演会「マルレク」を主宰し、人工知能や量子情報などについて講演を行っている。

開催概要
ChatGPTはどう変わろうとしているのか
――マルチモーダル化とカスタム化を中心に基礎から学ぶ
■講師:丸山不二夫(連続講演会「マルレク」主宰)
■開催日時:2023年11月24日 (金) 18:00 - 21:00(17:30開場)
■会場:五番町グランドビル 7F 東京都千代田区五番町3−1
■定員:100名
■参加費:一般 3,000円、丸山レクチャーズ会員 1,500円、学割 1,500円(学生証提示してください)
■主催:株式会社角川アスキー総合研究所
■申し込み:https://lab-kadokawa90.peatix.com
※イベント開催時間、各プログラムの開始終了時間は状況により変更する場合があります。イベント当日に大きな問題が発生した場合には中断・終了する可能性があります。詳しくは、申し込みサイトをご覧ください。
遠藤諭(えんどうさとし)

株式会社角川アスキー総合研究所 主席研究員。MITテクノロジーレビュー日本版 アドバイザー。プログラマを経て1985年に株式会社アスキー入社。月刊アスキー編集長、株式会社アスキー取締役などを経て、2013年より現職。人工知能は、アスキー入社前の1980年代中盤、COBOLのバグを見つけるエキスパートシステム開発に関わりそうになったが、Prologの研修を終えたところで別プロジェクトに異動。「AMSCLS」(LHAで全面的に使われている)や「親指ぴゅん」(親指シフトキーボードエミュレーター)などフリーソフトウェアの作者でもある。趣味は、カレーと錯視と文具作り。2018、2019年に日本基礎心理学会の「錯視・錯聴コンテスト」で2年連続入賞。その錯視を利用したアニメーションフローティングペンを作っている。著書に、『計算機屋かく戦えり』(アスキー)、『頭のいい人が変えた10の世界 NHK ITホワイトボックス』(共著、講談社)など。
Twitter:@hortense667本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第211回
プログラミング+
メガネは、AIの居場所になるのか -
第210回
プログラミング+
ナポレオン一世とコンピューター -
第209回
プログラミング+
鉄腕アトムー科学+魔法=AI on NVIDIA DGX Sparkが出した答えとは? -
第208回
プログラミング+
“合成音声”はかくも機械的なのに心を揺さぶるのか? -
第207回
プログラミング+
秋葉原は「アキバノハラ」だったのか、「アキハノハラ」だったのか? -
第206回
プログラミング+
“宿題でAIを使いはじめる前”に、“AI的ゾンビ”(a-zombie)にならないための方法 -
第205回
プログラミング+
「電脳秘宝館・マイコン展」──Intel 4004“ナゾ基板”の正体と、日本最初の野球ビデオゲーム「ラスト・イニング」 -
第204回
プログラミング+
Geminiにタイ移住を命じられた――100日チャレンジからAI駆動生活へ、大塚あみさんインタビュー -
第203回
プログラミング+
「DGX Spark」は現代の「Apple II」である -
第202回
プログラミング+
マイコン誕生50周年の最後に「Apple 1」と『Yoのけそうぶみ』がやって来た! -
第201回
プログラミング+
秋葉原・万世書房と薄い本のお話 - この連載の一覧へ














&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")


















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












