

自分の13年間の気分の流れを俯瞰してみる
不要不急の外出は避けるようにと政府も呼びかけているので、ひさしぶりにプログラミングにいそしむことにした。ここ数日楽しんでいたのは、PythonやRubyでPCの操作ができる「SikuliX」というものだが(その話はあらためて)、昨日からはTwitterの過去ログをダンウロードして遊んでいる。
私は、2007年5月からのTwitterユーザーで、昨日まで38,099回もつぶやいているそうだ。それって、自分でも忘却のかなたにあるここ10年ほどの私の脳みそや気分の記録というべきもので、メールやLINEなどのメッセージよりも本音が隠れていると思う。
もちろん、Twitterのサイトやアプリで自分の過去のつぶやきはクリックしてたどっていくことができるし、アカウントとキーワードを組み合わせて検索することこもできる。年月を指定して見れる「Twilog」なんて便利なサービスもある。しかし、Twitterがせっかく「全ツイート履歴をダウンロードする方法」を用意してくれているのだ。
ということで、自分の全ツイート履歴をダウンロードしてみたのだが、これがやっぱり楽しい。つぶやきテキストはjson形式でドカッと落ちてくるのだが(jsonについては各自ググってください)、自分がつぶやきで添付した画像(5,936個もアップロードしていた)が一望できる。
全ツイート履歴の落とし方は、次のとおり。
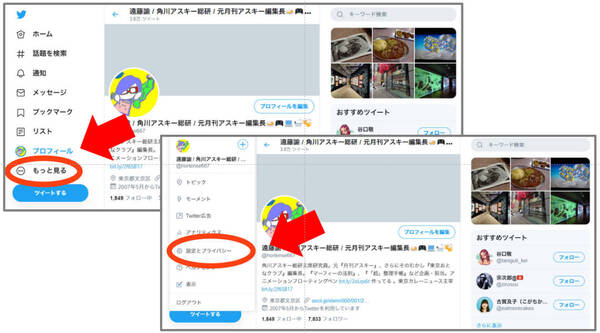
WebのTwitter画面なら「…もっとみる」を選び、「設定とプライバシー」を選択。
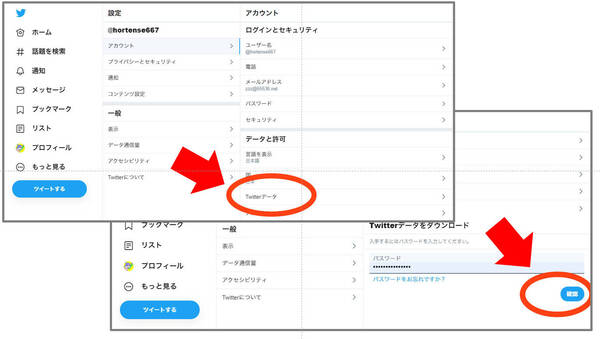
「Twitter」データを選んだら、「Twitterデータをダウンロード」をクリック、あとは画面の指示にしたがってアーカイブを依頼する。メールが到着したらダウンロード可能。
仕事にも生かせる(!)広告のインプレッションやコンバージョンまで分かる
ちなみに、1年ほど前は、このようにしてダウンロードするとhtml形式で落ちてきた。そのままウェブを使う感覚でオフラインで過去のつぶやきを見れたのだが、現在は、前述のとおりjson形式になっている。そこで、今回は、Pythonでそれを加工してエクセルに展開してみた。
ダウンロードしたzip形式ファイルを開くといろんなファイルが入っているのだが、まずはtweet.js(つぶやきデータ履歴)とdirect_messages.js(DMメッセージのやとりとり履歴)だろう。ほかにも、広告のインプレッションやコンバージョンの履歴も入っているので、そちら関係の人はサンプルになる人をある程度集めればTwitterの広告アルゴリズムを推定できたりするのかもしれない。ちなみに、角川アスキー総研では、Twitterのエンタメ全量解析というのをやっている(このコラムはその宣伝のためではないので念のため)。
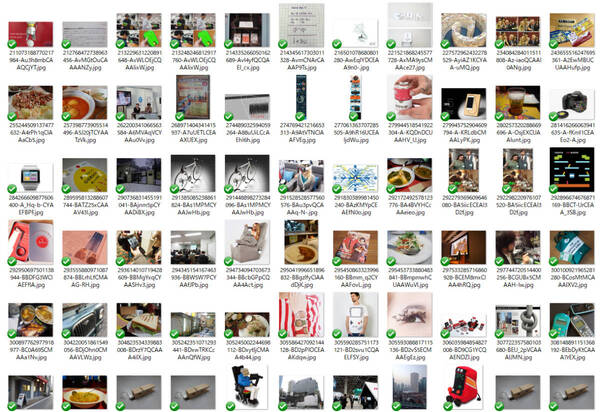
なんといっても5,000個以上ある画像が楽しい! 『ダンゴムシに心はあるのか』これ読んで森山徹先生を信州大学に訪ねた。腕時計のタトゥー、包帯柄のiPhoneケース、いま見ても自分は反応するものばかりだ。
pythonのプログラムは、次のようなものだ。これは、三重大学の奥村晴彦先生のスクリプトを参考にさせていただいている。今回は、先生のコードのときとjsonの構造が変わっているのと、文字コードエラー対策で書き換えさせていただいている(奥村先生のコードには「日本の子供は賢いがコンピューターが使えない」のときにもお世話になった=この場を借りてお礼申し上げたい)。
# -*- coding: utf-8 -*-
# エクセルを立ち上げておいてファイル読み込む
import json
from dateutil.parser import parse
from pytz import timezone
import re
import sys
import io
import codecs
# jasonファイルを開いて読み込む
with codecs.open('tweet.js', 'r' , 'utf-8', 'ignore') as f:
data = f.read()
tw = json.loads(data[data.find('['):])
# 書き出すファイルを開く
f = open('tweet.tsv', 'wb')
# 見たいデータを出力する
for t in tw:
s = t['tweet']['full_text']
e = t['tweet']['entities']
if 'urls' in e:
for u in e['urls']:
s = s.replace(u['url'], u['expanded_url'])
c = parse(t['tweet']['created_at']).astimezone(timezone('Asia/Tokyo')).strftime("%Y-%m-%d %H:%M:%S")
s = s.replace("\n", " ")
s = s.replace("\r", " ")
s = "https://twitter.com/hortense667/status/"+t['tweet']['id']+"\t"+c+"\t"+t['tweet']['retweet_count']+"\t"+t['tweet']['favorite_count']+"\t"+s+'\n'
f.write(s.encode('utf-8'))
f.close()
これを、tweet_log.pyなどの名前を付けて実行するとtweet.tsvというファイルが生成されるので、エクセルから読み込む。ファイルを開くのダイアログで右下の「すべてのExcelファイル~」を「すべてのファイル(*.*)」に書き換え、生成されたファイルを選んでウィザードはそのまま完了してやればよい(ふつうにエクスプローラからダブルクリックで開くと文字化けします)。
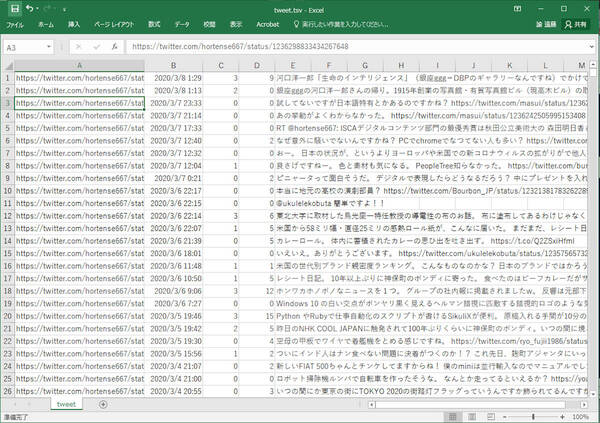
エクセルに取り込んだところ。左から当該ツイートのURL、ツイート日付、リツイート数、いいね数、ツイートの本文。
たった4項目しか書き出していないのでやれることは限られている。それでも、たとえば、私のつぶやきでいちばんリツイートの多かったつぶやきなんかが瞬時で分かる。私は、雑誌編集長の経験から「情報はたくさん発信した人のところにたくさん返ってくる」という信条の持ち主だ。さらに、海外ニュースをいまも積極的に見ているので「これ知ってる?」とつぶやくことが多い。いちばん多かったのはレゴのイボイボ互換の粘着テープのindie GOGOのプロジェクトがはじまったよというものだった。RTが、20,998件、いいねは、22,225件だった。つぶやきを確認するとインプレッションは約300万、エンゲージメントは約51万となっていた。
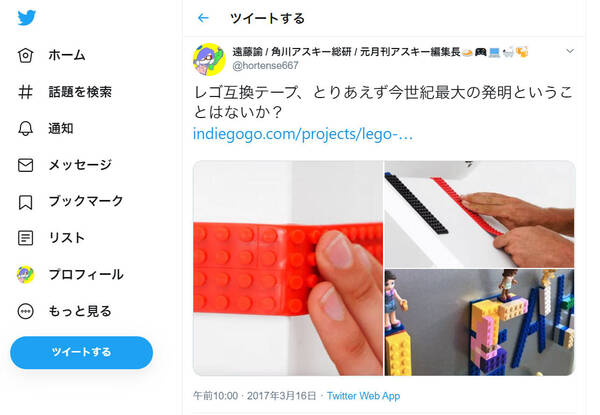
このLEGOのイボイボ互換テープもちろん入手しました。ここでいうほどのブームにならなかった。
Pythonでjsonをあつかうのはとてもラクなので、エクセルに取り込むだけよりも凝った分析も可能だろう。しばしば話題になる「何時頃のつぶやきがRTされやすいか?」のパーソナル版の集計なんかすぐにできそうである。ということで、もう2ミリほど作業をすすめて、ウェブやアプリではできないこととして、DM(ダイレクトメッセージ)を検索(一覧)できるようにした。
メッセージを検索したいときはこれしかない?
現状、Twitterのアプリやサイトで公式に提供されている「メッセージ」の検索機能ではアカウントとグループを洗い出すことまでしかできない。「こんなことメッセージでやりとりしたのは誰だっけ?」というようなときに、まったく役に立たない状態である。そこで、ダウンロードしたデータの中の「direct-messages.js」をやはり変換してエクセルに取り込んでみることにした。やり方は、Tweet.jsに対するスクリプトとほぼ同じである。
# -*- coding: utf-8 -*-
# エクセルを立ち上げておいてファイル読み込む
import json
import re
import sys
import io
import codecs
from dateutil.parser import parse
from pytz import timezone
# jasonファイルを開いて読み込む
with codecs.open('direct-messages.js', 'r' , 'utf-8', 'ignore') as f:
data = f.read()
tw = json.loads(data[data.find('['):])
# 書き出すファイルを開く
f = open('direct-messages.tsv', 'wb')
# 見たいデータを出力する
for t in tw:
for m in t['dmConversation']['messages']:
s = m['messageCreate']['text']
c = parse(m['messageCreate']['createdAt']).astimezone(timezone('Asia/Tokyo')).strftime("%Y-%m-%d %H:%M:%S")
s = s.replace("\n", " ")
s = s.replace("\r", " ")
s = "https://twitter.com/messages/"+t['dmConversation']['conversationId']+"\t"+c+"\t"+s+'\n'
f.write(s.encode('utf-8'))
f.close()
これを、direct_messages.pyなどというファイルにして実行すればよい。さすがに私信なので画像も貼らないが、これで13年間のこまかなやりとりが見える。ただし、現状ではメールの相手の名前までは表示していない。follower.jsというファイルをもとにTwitter APIで求めて表示できるのかもしれないが、ここでもDMのスレッドのURLを生成している。なので、それをひらけば誰とどんなメッセージの流れだったのかはすぐに確認できる。
ところで、この2つのデータを見ていくといまさら確認できることもある。たとえば、東日本大震災の起きた2011年3月11日の14時46分から12日の深夜まで、私は、52回もつぶやいていることが分かった。しかし、DMは1通もやりとりしていなかった。
その日、私は六本木のミッドタウンタワーにあるYahoo JAPANさんにおじゃましてプレゼンしていた。ビルの揺れがかなりの時間止まらない。ようやく揺れが止まると「1階で火災発生」という館内放送があり、階段をゾロゾロと降りて外にでる(後で火災は誤報と判明)。同僚と近くのカフェで休んだあと私は西新宿の会社まで歩いて帰ることにした。ようやく地震から2時間後の16時43分に「とりあえず歩いて会社にもどる。」とつぶやく。
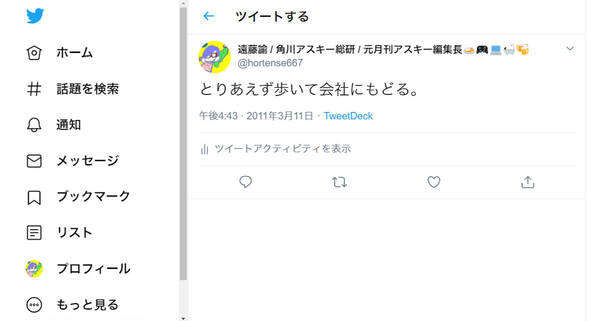
最初のつぶやきはミッドタウン近くのカフェで休んでいたにもかかわらず地震から2時間後だった。
いま、グーグルマップで見ると5.3キロで1時間9分の距離だが、途中千駄ヶ谷の「Good Morning Cafe」というところで休憩したとつぶやいており、「とりあえず歩いて~」とつぶやいてから「もうすぐ会社」とつぶやいくまで2時間経過していた。
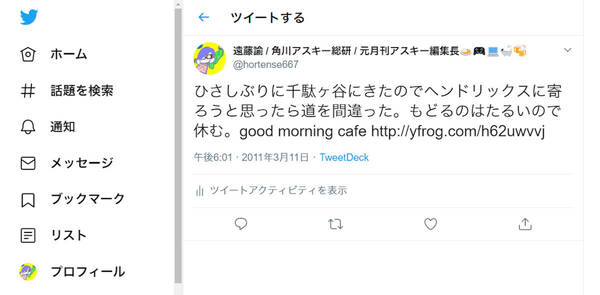
千駄ヶ谷を経由してだがこの事態でカレー店を気にしている。
それから、これまた大江戸線都庁前駅が大混雑で苦労して家に着いたのは真夜中。テレビを見てあらためてことの重大さを知った。震災にあわれた方々のことを思うとなんとものんきな話で申し訳ないのだが。
Twitterには、メールでもメッセンジャーでもない無意識の自分があると書いたが、あらためてTwitterというメディアのふしぎさを味わった。今回は、週末プログラマとして本当にデータを右から左に移して眺めてみたわけなのであるが。Twitterに関しては、2010年1月に、その利用実態調査というものを行い「Twitterはコミュニケーション革命なんかじゃない?」というコラムを書かせてもらった。そこで書いたことなんかはデータで検証可能だと思うし、本当にそうだと思う。
次回は、冒頭で少しふれた「SikuliX」で仕事をラクにする方法について紹介したいと思っている。
遠藤諭(えんどうさとし)
株式会社角川アスキー総合研究所 主席研究員。月刊アスキー編集長などを経て、2013年より現職。角川アスキー総研では、スマートフォンとネットの時代の人々のライフスタイルに関して、調査・コンサルティングを行っている。平成最後の日、NHK『ゆく時代くる時代』にガジェット鑑定士として出演。著書に、『近代プログラマの夕』(ホーテンス・S・エンドウ名義、アスキー)、『計算機屋かく戦えり』など。
Twitter:@hortense667 Facebook:https://www.facebook.com/satoshi.endo.773本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第210回
プログラミング+
ナポレオン一世とコンピューター -
第209回
プログラミング+
鉄腕アトムー科学+魔法=AI on NVIDIA DGX Sparkが出した答えとは? -
第208回
プログラミング+
“合成音声”はかくも機械的なのに心を揺さぶるのか? -
第207回
プログラミング+
秋葉原は「アキバノハラ」だったのか、「アキハノハラ」だったのか? -
第206回
プログラミング+
“宿題でAIを使いはじめる前”に、“AI的ゾンビ”(a-zombie)にならないための方法 -
第205回
プログラミング+
「電脳秘宝館・マイコン展」──Intel 4004“ナゾ基板”の正体と、日本最初の野球ビデオゲーム「ラスト・イニング」 -
第204回
プログラミング+
Geminiにタイ移住を命じられた――100日チャレンジからAI駆動生活へ、大塚あみさんインタビュー -
第203回
プログラミング+
「DGX Spark」は現代の「Apple II」である -
第202回
プログラミング+
マイコン誕生50周年の最後に「Apple 1」と『Yoのけそうぶみ』がやって来た! -
第201回
プログラミング+
秋葉原・万世書房と薄い本のお話 -
第200回
プログラミング+
11/2(日)ガジェットフリマと豪華ゲストによる変態ガジェットアワードが東京ポートシティ竹芝で開催 - この連載の一覧へ


とBTO PCならではの特注PCパーツに大興奮")
























ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")
