
スループット2倍、クロックも2つ
RX 7000シリーズのダイは、画面描画をはじめディスプレーへの表示や動画関係の処理を行う機能だけを抽出した「GCD(Graphics Compute Die)に加え、メモリーコントローラーと第2世代Infinity Cacheだけで構成される「MCD(Memory Cache Die)」の2つで構成される、ということは前回解説した。
MCDは1基あたり64bit幅のメモリーコントローラーと16MBの第2世代Infinity Cacheで構成される“チップレット”であり、MCDの数を6基備えるのがRX 7900 XTX、5基で構成されるのがRX 7900 XTとなる。前世代であるRadeon RX 6950 XT(RX 6950 XT)のInfinity Cacheは全体で128MBだったのに対し、RX 7900 XTXでは96MBに減っている。
Infinity Cacheを多量に抱えることで高解像度における描画処理のキャッシュヒット率を高め、狭いメモリーバス幅の欠点を補ってくれるというのがRadeon RX 6000シリーズの上位モデルにおける戦略だが、RX 7000シリーズはより少ないInfinity Cacheで従来は厳しかった4Kや8Kのゲームプレイを狙っている。
ただGCD-MCDを何らかのインターフェースで接続するということは、そこが足枷になる危険性もある。どんな上手い手を使ってそれを克服したのかは、まだ明らかにされていない。

RX 7900 XTXのチップ。中央に見えるのがMCD+GCDで構成されるダイだ

GCDは高価な5nmプロセスで製造されているが、MCDは比較的安価な6nmで作る。全部5nmで製造していたら、とても1000ドル以下で提供できるGPUにはならなかっただろう
なぜInfinity Cacheを減らしたかといえば、第2世代Infinity Cacheのもたらす帯域幅は、初代Infinity Cacheよりも極めて高いからだ。RX 7000シリーズにもっと多量のInfinity Cacheを搭載することもできたが、コストのためにあえてそうしなかった、という筆者の想像はあながち間違っていないだろう。

RX 7900 XTX(上段)とRX 6950 XTでGDDR6+Infinity Cacheの帯域幅(最大値)を比べると、RX 7000シリーズはRX 6000シリーズの2.7倍も帯域幅があるとAMDは主張する。2.7倍の大半は第2世代Infinity Cacheが稼ぎ出しているとAMDは主張している。無論この差はGPUコア設計の違いや各部クロックの向上込みの値となる
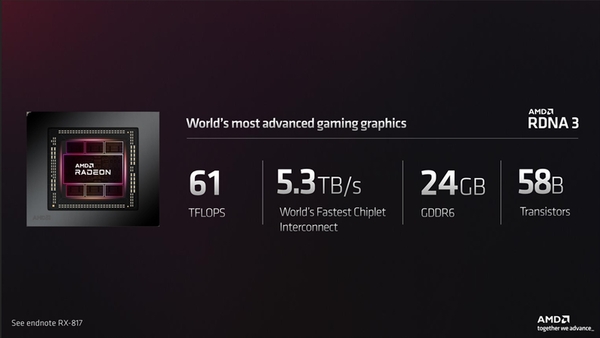
GCD-MCD間のインターコネクトに何が使われているのかまだ言うことはできないが、最大5.3TB/secという転送速度は世界一であるとAMDは主張している
Radeonにおける描画機能の要となるShader Engineの構造も大きく変化した。AMD曰く“ゲーミングに最適化した”設計にすべく従来よの1.65倍のトランジスターが詰め込まれている。FP32等の演算を行うCU(Compute Unit)は1基あたり64SP(Shader Processor)のままだが、1回で2命令実行が可能になったため、1CUあたりのSPは従来の2倍になった。
この辺のアーキテクチャーに関する深い話は、後日情報解禁となる大原氏の連載のDeep-Dive記事で明らかにされるはずだ。

RDNA 3世代のCUはDual Issue、つまり2命令を1回で実行できるようになったことでスループットも2倍。無論命令や条件次第では2命令同時にはできないパターンはあるだろうが、ゲームグラフィックスの世界では2倍と考えてよいだろう
Radeonにおけるレイトレーシング処理の要といえるRay Acceleratorも第2世代に更新された。1.5倍のレイを飛ばす機能や、新命令の追加、レイのヒットを検出するためのBVH(Bounding Volume Hierarchy)探索の効率化に関係する機能等が新要素だが、具体的にどう違うかまでは語られていない。
ともあれ、RDNA 2世代のRX 6000シリーズはライバルに比してレイトレーシング性能が弱いという弱点を抱えていたが、RDNA 3で果たしてAda Lovelace世代のGeForceに並ぶのかどうかに注目が集まる。

Ray Acceleratorも第2世代となり、いろいろと強化された
RDNA 3ではCU1基に対し、2基の「AI Accelerator」が新設された。これは文字通りAI処理(行列演算)に特化した回路で、NVIDIAのTensorコアやインテルのXMXに相当する要素だ。
ただ非常に面白いかつ不可解なのは、AMDはこのAI Acceleratorを何に使うのか具体案を示していないことだ。Tensorコアでは最初からDLSSによる超解像処理、後にWebカメラの背景除去や音声の背景ノイズ除去処理等といった実用的な機能を提案してきた点と対照的だ。とりあえず現状では何故あるのか分からない機能になっているが、今後どう転ぶかは分からない。

RDNA 3ではCU内にAIによる推論処理を高速化する回路、AI Acceleratorが組み込まれたが、これをどう活用するかはAMD自体も手探りのようだ

AMDはAI Acceleratorをどう使うかハッキリと決めていないが、こういう使い方もある、というデモを見せてくれていた。写真は「Stable Diffusion」からAI Acceleratorを叩いているというデモだが、どうやってAI Acceleratorにアクセスしているのかまでの情報は明かされなかった。著作権的にヤバいので出力はボカしているが、国民的電気ネズミが料理の皿を前にした絵を描くようなパラメーターが左上に入力されている
プロセスのシュリンクといえば動作クロックの引き上げも外すことはできないが、今回RX 7900 XTXのブーストクロックが2.5GHzに設定されているが、RX 6950 XT(2.25GHz)からほとんど上昇していないように見える。ただこれは見せかけであって、実際ゲームをプレイしている時に安定するゲームクロックはRX 7900 XTXが2.3GHz、RX 6950 XTが2.02GHzであるので、ここの部分では相応に上がっているように見える。
ここでAMDはさらにひと工夫している。GCDのフロントエンド部分(命令の発行などを担当する前段部分)と、実際の描画(シェーダー)部分のクロックを分割したのだ。具体的にはRX 7900 XTXではフロントエンド部分が2.5GHz、シェーダーが2.3GHzとなる。
一見面倒臭くしただけのような工夫に見えるが、超高フレームレート環境ではCPUからの描画命令を効率良く捌く必要がある。そして、CPU側もGPUパワーを最大限に活かせるように高速に処理する必要がある。
描画命令を受け取る部分を高クロック化することで、よりスムースな連携がとりやすくなると判断したのかもしれない。シェーダークロックを分離したのは、全体を上げてしまうと消費電力という問題が立ちはだかる。クロックの分離は妥協の産物というよりも、発想の転換といえそうだ。
ちなみに電力や熱に余裕のある時はシェーダーも2.5GHzで動くとのことだが、電力に対するインパクトの大きいシェーダーのクロックを下げたことで、25%の消費電力削減を果たしたとAMDは説明している。

フロントエンド部分を高クロック化することは、CPUのパワーをより良く活かせることに繋がる。シェーダーも一緒にクロックを上げられればよいが、消費電力という問題が出てくる。性能と消費電力のバランス取りの結果、こういう一見不可解な仕様になったのではないだろうか
本記事はアフィリエイトプログラムによる収益を得ている場合があります












