



最新パーツ性能チェック 第381回
購入前に押さえておきたいRTX 40シリーズの新機能も解説
GeForce RTX 4090基本ベンチ&解説編!Fire Strike UltraはRTX 3090から93%アップ!?
2022年10月11日 22時00分更新

補助電源ケーブル構成によりOC限界が変わる
RTX 4090 FEの補助電源コネクターにはRTX 3090 Tiで初採用された16ピンの“12VHPWR”が採用されている。これはRTX 4090 FEのTGPが450Wと高く設定されているためだが、RTX 4090 FEに同梱される変換ケーブルはなぜか8ピン×4を12VHPWERに変換する。8ピン補助電源1本で150Wだから、この変換ケーブルで600Wの電力供給に対応できる。これはどういう理由によるものなのだろうか?
その答えはシンプルで、RTX 4090 FEの場合、8ピンケーブルを3本しか接続しなくても普通に動作する。だが4本接続した場合に限り、「MSI Afterburner」などのOCユーティリティー上でPower Limitを定格の33%増、即ち600Wまで引き上げることができる。ただ、この仕様はビデオカードメーカーの味付け次第でもっと低い値、例えば500W程度に絞られている場合もある点に注意したい。RTX 4090 FEならではの欲張り仕様といえるかもしれない。

RTX 4090 FEに同梱されていた12VHPWRケーブル。TGP 450Wのカードなら8ピン×3から変換が自然だが、実機では8ピン×4となっている
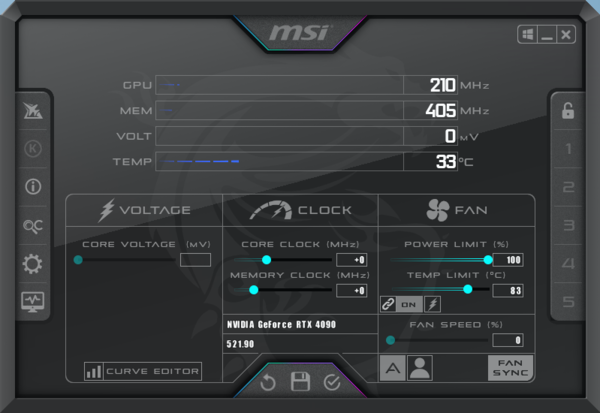
RTX 4090 FE同梱の12VHPWRケーブルに、8ピンケーブルを3本だけ接続した状態でMSI Afterburnerを起動した。するとPower Limitのスライダーが最初から右端になっており、100%から上に動かせなくなる
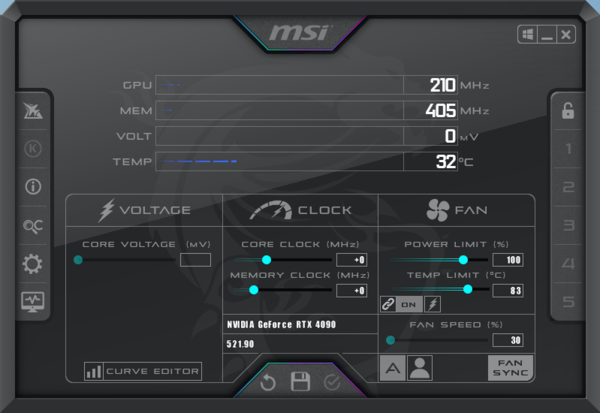
今度は8ピンケーブル4本接続した状態でMSI Afterburnerを起動すると、Power Limitが100%でもまだ右にスライダーを動かせる。一番右まで動かすと133%になるが、その場合のTGPは450W×1.33≒600Wという計算になる
この挙動は同梱の12VHPWRケーブルの設計にある。現在流通している12VHPWR対応電源や変換ケーブルの中には、4本の制御用ピンのうちSense0と1をGNDに接続することで、決め打ちで600W供給を可能にしている製品があるが、RTX 4090 FE同梱の12VHPWRケーブルはもう少し賢い。このケーブルには補助電源ケーブルが何本接続されているか判定する回路が組み込まれており、これに応じて制御用4ピンをGNDに接続する/しないを決定している。RTX 4090 FEはこれを読み取って、Power Limitの設定レンジを決定する。
何度も繰り返すようだが、ここで解説した内容はあくまでRTX 4090 FEの場合であり、国内で流通するAICパートナー製RTX 4090カードでは異なる可能性がある点に注意されたい。筆者はファクトリーOCモデルにもこのケーブルが供給されるのではないかと考えているが、TGPを450Wより上に設定して出荷されるファクトリーOCモデルでは8ピンケーブル4本接続が必須になる可能性も十分に考えられる。

12VHPWRケーブルの先端。制御用4ピンの接続先をテスターで探ってみたが、通電していない状態ではどのピンも導通しない。NVIDIAによれば内部に専用の回路が仕込まれているとのこと
RTコアの進化とSERでレイトレーシングをより快適に
Ada LovelaceではCUDAコアそのものに手をいれず、RTコアとTensorコアの強化が主眼になっている。この辺はGTCでの発表を解説した記事で述べているが、本稿はその内容を補完するとともに、RTX 40シリーズの新要素をもう少し深く解説しておきたい。

RTX 40シリーズのSMの構造。FP32/INT32共用のCUDAコアのほかに、FP32専用のCUDAコアが搭載されている点はAmpereと共通だが、TensorコアとRTコアがそれぞれ1世代新しくなっている
①SER(Shader Execution Reordering)
GeForceではCUDAコアのクラスターであるSMが基本単位となり、ここに搭載されている命令ユニットがCUDAコアに命令を発行する。RTX 40シリーズのSMでは、この部分に命令の事項順序を動的に並び替え、処理効率を向上させることが可能となった。それがSERだ。
レイトレーシングでピクセルの色を決定する処理において、光線(レイ)があちこちに飛べば、飛んだ先ごとに異なったシェーディング処理が走ることになる。飛び先が多いほど異なる処理が走るため、処理の切り替えやメモリー管理などの負荷が増大する。SERで似た処理を連続するように並び替えることにより、処理効率を向上させることが可能になる。
「Cyberpunk 2077」に搭載予定の「Overdrive」モードでは、レイトレーシングの中でも特に負荷の重いパストレーシングが実装される予定だ。しかしこうした処理ではSERの存在が必要不可欠となる。NVIDIAによれば、Cyberpunk 2077のオーバードライブモードにおいて最大44%の性能向上が観測されたという。
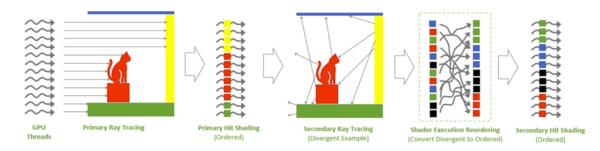
レイトレーシングの処理において、最初のレイが衝突する際は似たような処理(図では赤/緑等の色で示している)がある程度まとまっている。だがレイの反射する先が散るとてんでバラバラな処理が並ぶことになる。これをSM内で並び替え、効率を上げるのがSERの目的だ

Cyberpunk 2077には、新たなレイトレーシングの処理としてオーバードライブモードが近日実装される。平たくいえばより濃厚でリアルな反射を表現できる技法だが、1ピクセルあたり635回のレイトレーシング処理が必要になる
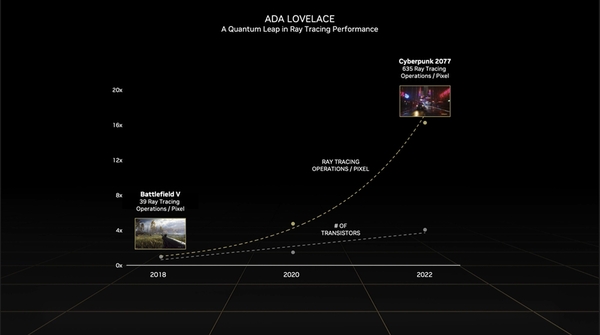
2018年の「Battlefield V」では1ピクセルあたり39回のレイトレーシング処理で済んでいたものが、2022年のCyberpunk 2077では635回へ。15倍以上増加している。GPUのトランジスター数増加は到底これに追い付けない。この辺がジェンスン・ファン氏をして「ムーアの法則は死んだ」と言わしめる理由の1つだ
②RTコアに新機能を追加
レイトレーシング処理の命といえるRTコアは、第3世代に進化。前世代に比較してレイ-トライアングルの衝突判定速度が2倍になったほか、「Opacity Micromap Engine」と「Displaced Micro-Mesh Engine」が新たに追加された。
Opacity Micromapは部分的に透明度を持つオブジェクト(植物の葉や炎、煙など)の処理を効率化する機能だ。下図のように葉のテクスチャーを持つオブジェクトにレイが衝突した場合を考えてみよう。葉のテクスチャーの外周は透明になっており、こうした表現は実ゲームでもよく使われる。このオブジェクトにレイが衝突した際、衝突地点が透明(外側)ならレイはヒットしていないと判定されるが、葉の内側や境界ならヒットしたと見なして別の処理に続く。
従来のRTコアでは、オブジェクトにヒットした判定はできるが、そこが透明な部分か、そうでないかの判定に複数の処理(下図ではShader Work)が使われる。画面上に葉が1枚や2枚で済む訳はないので、この判定処理がボトルネックを生む。
そこで予め透明度のマップ、即ちOpacity Micromapを保持しておき、それを参照して葉の外か中か、あるいは境界かを判断できる。透明度を持ったオブジェクトを多数配置して表現するシーンでは、Opacity Micromapでシェーダーの負荷を劇的に下げられるわけだ。
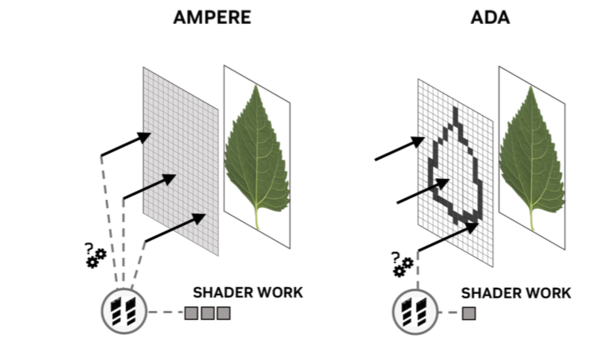
従来のRTコア(左)ではレイの着地した地点(矢印の先)が葉のテクスチャーの内か外か判定するための処理が複数必要だが、新しいRTコア(右)では透明度のマップを利用してより効率良く判定を行うことができる
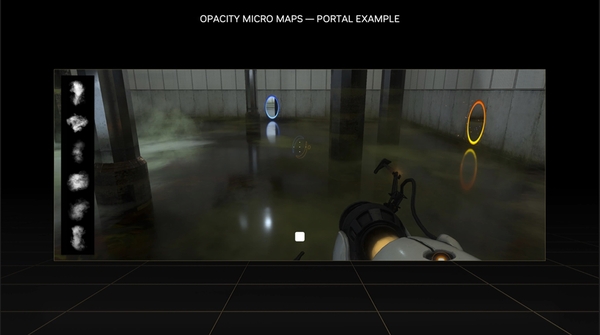
部屋の中にフォグが漂うシーンを考えてみよう(画面は開発中のレイトレーシング対応「Portal」)。この表現は図中左側、縦一直線に並んでいるような透明度を持ったテクスチャーを備えたオブジェクトを配置して実装する
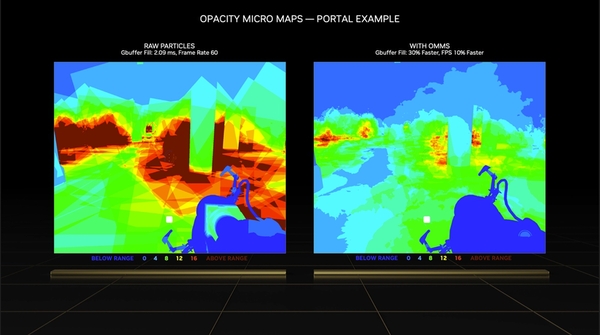
Opacity Micromapの有無による計算量をヒートマップ化した図。従来の手法(左)では計算量の多い部分(黄色〜赤部分)が広範囲に拡がっているが、Opacity Micromapを採り入れた場合(右)は計算量を劇的に下げることができる。これでフレームレートは10%向上するという
もう1つの追加要素であるDisplaced Micro-Mesh Engineは、レイとポリゴンの衝突判定を行うために必要不可欠なBVH(Bounding Volume Hierarchy)構築の速度とBVHのデータ量を劇的に小さくできる機能だ。オブジェクトのジオメトリーが100倍複雑になっても、レイをトレースする処理はそれほど増えないが、ジオメトリーが100倍になればBVHの構築時間も100倍になるし、メモリー消費量も増える。これも大きなボトルネックになり得る。
RTX 40シリーズの第3世代RTコアでは、BVHを適度に粗い三角形の集合レベルで構築し、その三角形ごとに本来の形状を再現する情報(Displacement Map)を組み合わせることが可能になる。こうすれば複雑なジオメトリーを少ないデータ量で表現できるのだ。

3つの複雑なオブジェクトをDisplaced Micro-Meshを使った時の効果をまとめた図。例えば中央の水瓶は、従来手法からBVHの構築時間は15倍以上高速に、BVHのサイズも20分の1になったという
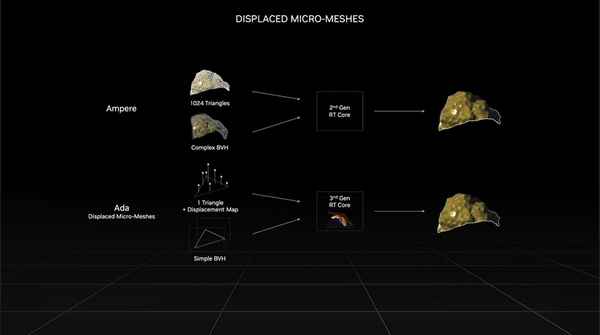
従来のRTコアでは複雑なオブジェクトをそのまま処理していたのに対し、RTX 40シリーズのRTコアではシンプルな三角形+変位マップの情報をRTコアで合体させることで同じ結果が得られる
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第475回
自作PC
Core Ultra 7 270K Plusは定格運用で285K超え!Core Ultra 5 250K Plusは265Kにほど近い性能 -
第474回
自作PC
Core Ultra X9 388H搭載ゲーミングPCの真価はバッテリー駆動時にアリ Ryzen AI 9 HX 370を圧倒した驚異の性能をご覧あれ -
第473回
デジタル
Ryzen 7 9800X3Dと9700Xはどっちが良いの?! WQHDゲーミングに最適なRadeon RX 9060 XT搭載PCの最強CPUはこれだ! -
第473回
自作PC
「Ryzen 7 9850X3D」速攻検証:クロックが400MHz上がった以上の価値を見いだせるか? -
第472回
sponsored
触ってわかった! Radeon RX 9070 XT最新ドライバーでFPSゲームが爆速&高画質に進化、ストレスフリーな快適体験へ -
第472回
自作PC
Core Ultraシリーズ3の最上位Core Ultra X9 388H搭載PCの性能やいかに?内蔵GPUのArc B390はマルチフレーム生成に対応 -
第471回
デジタル
8TBの大容量に爆速性能! Samsung「9100 PRO 8TB」で圧倒的なデータ処理能力を体感 -
第470回
デジタル
HEDTの王者Ryzen Threadripper 9980X/9970X、ついにゲーミング性能も大幅進化 -
第469回
デジタル
ワットパフォーマンスの大幅改善でHEDTの王者が完全体に、Zen 5世代CPU「Ryzen Threadripper 9000」シリーズをレビュー -
第468回
自作PC
こんなゲーミングPCを気楽に買える人生が欲しかった Core Ultra 9 285HX&RTX 5090 LTで約100万円のロマンに浸る -
第467回
デジタル
Radeon RX 9060 XT 16GB、コスパの一点突破でRTX 5060 Tiに勝つ - この連載の一覧へ









の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")







