




配線に新材料eCuを採用し
エレクトロマイグレーションを軽減
次が懸案事項だった配線層である。インテルが10nmの当初プロセスでエレクトロマイグレーション(配線金属の欠陥)が大問題になり、これの対策としてコバルトを配線層の一番下側(M0/M1)に採用した、という話は連載464回で紹介した通りである。
コバルトはエレクトロマイグレーションには強い(平均自由工程が短い)半面、抵抗値そのものは銅の6倍にもおよぶため、実装密度は上げられても動作周波数向上や消費電力削減にはあまり適していない、という特性がある。
したがって相当注意しないと大変なのだが、Intel 4ではここにeCu(Enhanced Cu)という新しい材料を投入した。このeCuは次に示すとして、まず配線総数が17層(Contacted Gateも含む)から18層に1層増えた。またIntel 7に比べると全体的に配線がやや細めになっている。
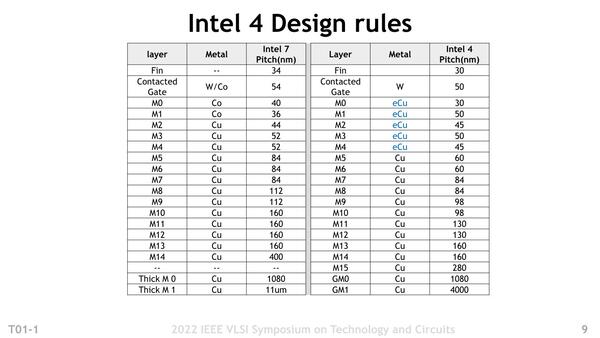
連載483回でも紹介したが、2017年のIDMで10nmは13層になっており、これがIntel 7では17層と4層増えた格好だ。また配線ピッチも微妙に異なっており、このあたりだいぶ変更があったようだ
扱い的にも、今まではM0/M1がLocal Interconnect(1つのゲート内、あるいは近隣のゲート間の配線用)、M2以降がGlobal Interconnect(やや距離のある配線用)と位置付けられていたのが、Intel 4ではM0~M4がこれに充てられているように思われる。
ついでに書いておけば、Intel 4ではトランジスタ層およびContacted Gateに加え、eCuでの配線となるM0~M4にEUV露光を利用するようだ。
eCuの詳細が下の画像だ。Intel 4ではタンタルの配線内側にコバルトのインナーを設け、その内側に銅配線を置く構造になったとしている。
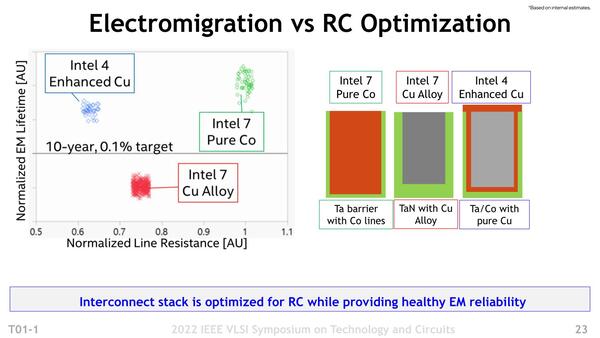
eCuの詳細。抵抗を低くできれば、それだけ消費電力が下がるのみならず、寄生抵抗に起因する配線遅延の影響を下げられることになる。ただ実際に下がるかどうか? はこのeCUの誘電率が明確に示されていないので、断言はしにくいところ
この構造は2017年にIEDMでGlobalfoundriesが提案した、という話は連載464回でも触れたが、その論文によればコバルトの配線で銅をカバーすると、より高電圧まで耐えることが示されている。
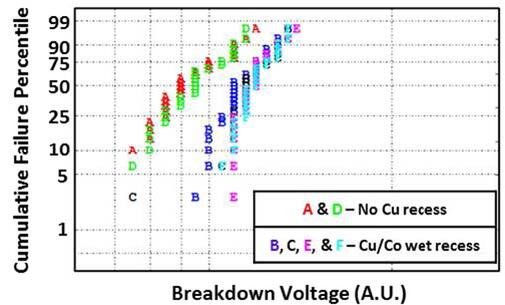
コバルト配線なら高い電圧まで耐えられる。肝心のGlobalfoundriesが7nmを放棄してしまった関係で、この研究を生かしていないのが残念である
“Fully Aligned Via Integration for Extendibility of Interconnects to Beyond the 7 nm Node”より抜粋
ちなみにこの図は横軸が掛ける電圧、横軸が累積故障率で、どちらも対数軸である。AとDが銅のみの配線、B/C/E/Fがコバルト配線を追加したもので、どの程度の厚みの配線なのかなどでパラメーターが変わるが、実際に故障が発生するまでの電圧をより高くとれるとしている。要するにエレクトロマイグレーションがより起きにくくなるわけだ。
前掲したeCuの詳細画像に戻ると、左側に抵抗値とエレクトロマイグレーションの発生頻度を表した結果が示されている。縦軸の“10-year, 0.1% target”というのは、10年間の間に0.1%の確率でエレクトロマイグレーションを発生する故障率であって、Intel 7のコバルト配線とIntel 4のeCUはどちらもこれを下回る。つまり10年の間の故障率が0.1%未満、あるいは0.1%の故障率となる期間が10年をずっと超えている。
Intel 7の銅配線では故障率がもっと高いことになる。その一方で、配線抵抗そのものはIntel 7のコバルト配線を1とするとIntel 7の銅配線は0.75程度、Intel 4のeCUは0.65程度まで引き下げられているとする。
ちなみにGlobalfoundriesの論文を読む限りは、別にコバルトのインナーを構築するのにEUVが必要と言う話は見当たらない。単に配線を微細化するのにEUVが必要であり、かつそうした微細化した配線でエレクトロマイグレーションを起こさないためにコバルトのインナーが必要だったということと思われる。
次がその露光の話。インテルが利用していたSAQPという技法は連載483回で解説しているが、なにしろ4本1組なので配線の自由度が限られるし、パターン生成→2回転写で露光が3回。その前後にはCMPを含む前処理/後処理が必要なうえ、転写をかけている関係でどうしてもパターンがガタガタしやすいことになる。
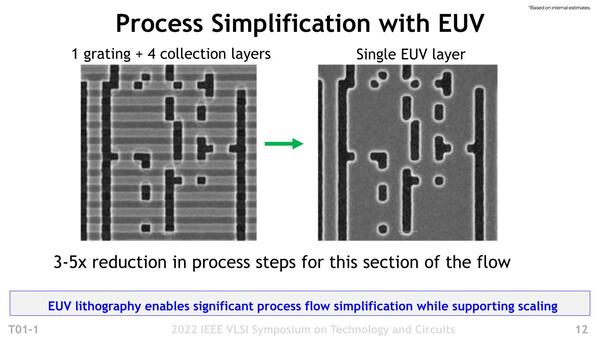
これは実際の配線というよりも、EUVのトレーニング用に作ったマスクだと思われる
ガタガタしやすい、ということは配線をギリギリまで詰めるとエラー(ショートしたとか、つながるべき配線がつながらなかったとか)が起きやすいので、どうしてもマージンを大き目に取らないといけない。それはそのままエリアサイズの増大につながることになる。
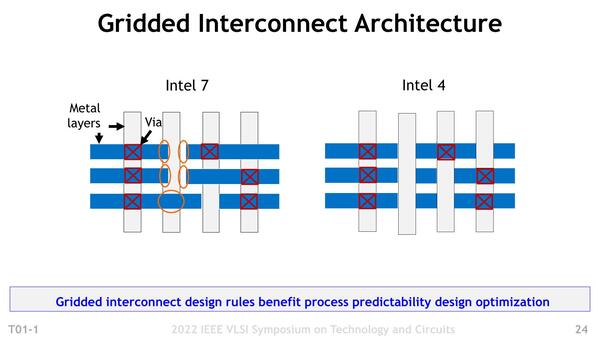
この図は前掲の画像を90度回転した形になる。縦方向がFin、横方向が配線である
Intel 7では横方向、つまりDiffution Breakに関してはすでにシングルになっているが、縦方向のDiffusion Gridに関しては2 Finを余儀なくされていた、というのはこの微妙なずれを考慮すると1 Finでは厳しいケースがあるということの裏返しだったと考えられる。これがEUVを使ったIntel 4ではかなり配線誤差が減った結果、1 Finでも十分になった。
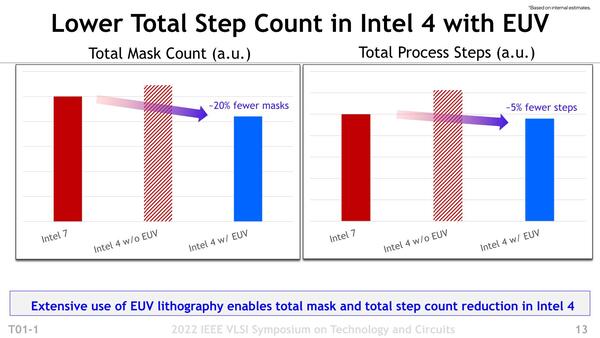
また生産性という意味でも、EUVを利用することで大幅に改善したというのが下の画像だ。半導体製造の初期コストで馬鹿にならないのがマスクの製造コストで、これがIntel 7比で2割減、また露光の前後まで含めた総処理ステップ数は5%減とされる。ちなみにEUVを使わないと、マスク枚数はIntel 7比で10%増、処理ステップ数は2割増なので効果は確かにある。
EUVを使うと露光が現時点ならほぼ1回で済むのは事実(正確に言えば、1つの露光ステップを1回の露光だけで完了できる。ArF+液浸のSADPでは1つの露光ステップが2回、SAQPなら3回必要になり、それぞれ別のマスクが必要になる)
もっとも価格が下がるか? というとこれはまた別の話で、ArF向けのマスクに比べてEUVのマスクは高価だし、ArF露光機に比べてEUV露光機は消費電力も大きい(例えばASMLの場合、250WのEUV出力に必要な消費電力は21.5KWにも達する)から、マスクコストと生産コストの両方でArF+液浸を下回るのは相当先になる。
加えて現状はまだEUV露光機のコストも償却できていないので、コストそのものまで下げられるのは相当先になると思われる。そのあたりも加味して“マスク枚数と総処理ステップ数が削減できる”という表現なのだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























