ロードマップでわかる!当世プロセッサー事情 第674回
Zen 5に搭載するAIエンジンのベースとなったXilinxの「Everest」 AIプロセッサーの昨今
2022年07月04日 12時00分更新

SW PEの内部構造はMIMD
ではそのSW PEはどんな構造か? というのが下の画像だ。ラフに言えば1つのSW PEのエレメント(ここではTileという表現になっている)は、演算器とローカルメモリーを組み合わせた構成である。で、これが格子状に多数、メッシュ構造で接続されているという格好である。
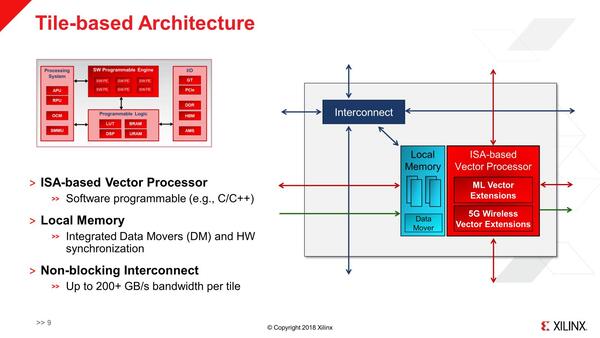
SW PEの構造。この頃はまだ5Gなどに向けたアクセラレーターも前面に打ち出していた関係で、1つのISAの下にAI向けの拡張とワイヤレス向け拡張があるような構造として説明されていた
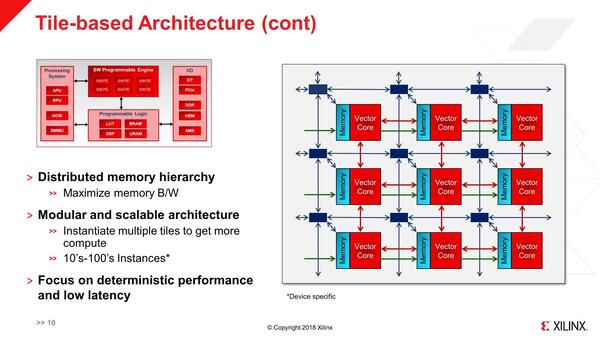
ちなみに最初の搭載製品であるVersal AI Coreの場合、最大でこのSW PEを400個搭載していた
メッシュ構造にした上で、それぞれのSW PEを連結することで、処理のパイプラインを構築することもできる。
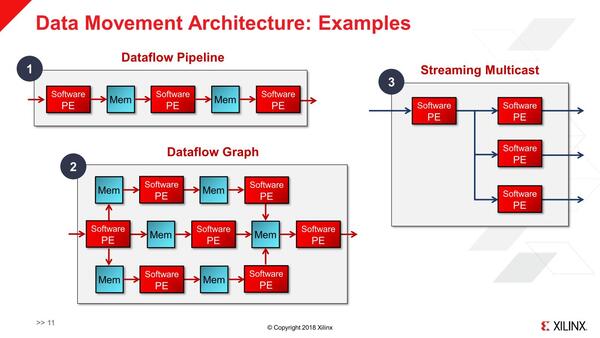
これはいわゆるデータフロー式の処理のやり方、と見なすこともできる
要するにこのSW PEはMIMD構成になっているわけだ。おのおののSW PEは別々の命令を実行可能であり、処理の内容に応じて複数のPEを組み合わせて最適な形で実行可能である。もちろん同一の命令を実行することもできるが、その場合はそれぞれのSW PEに同じプログラムをロードして、同時に実行させるという話であって、その意味ではSIMDとは異なる。
ちなみにこの割り振りはプログラマブルであり(つまり自動では行なわれない)、プログラマー側で考える必要があるが、結果から言えばこれはVitis AIと呼ばれるツールで割り振りを管理できるので、実はそれほど難しいことではない。
これまでの画像は2018年8月に開催されたHotChipsでの説明であり、この時はまだSW PEの中身の詳しいところは未公開だったが、同年10月に開催されたXDF(Xilinx Developer Forum) 2018の開催に合わせてホワイトペーパーがリリースされ、これでもう少し細かい話が見えてきた。
まずSW PEあらためAI Engineという名前になったブロックの内部構造が下の画像だ。RISC風の32bit演算ユニットに、Fixed Pointの512bit SIMDエンジンとFloating Pointの512bit SIMDエンジンを組み合わせるという独特の構造である。プログラムメモリーは16KB、データメモリ-は32KBと決して大きくないが、これは逆に言えば1つのAI Engineであまり複雑な処理をさせるつもりがない、という裏返しでもある。
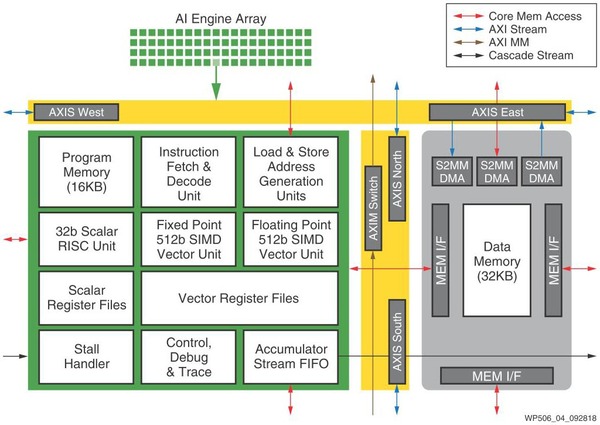
AI Engineの内部構造。外部入出力がかなり豊富なのも特徴である。2次元メッシュなので、東西(AXIS East/West)と南北(AXIS North/South)方向のルーターが用意され、中央にAXIM Switchという形でこの2次元メッシュとのI/Fが搭載されている(黄色の部分)
さて、SIMDエンジンは、別にRISCユニットから呼び出されるわけではない。というのは、このAI Engineの命令フォーマットは下の画像ようにVLIWになっている。
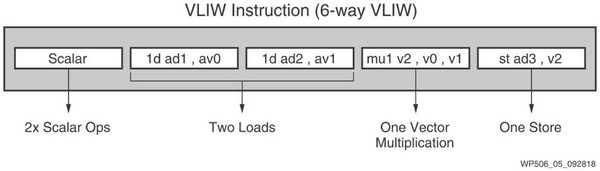
ここでは“One Vector Multiplication”とあるが、別にベクトル乗算だけでなく、他の演算も可能。あくまでVector Operationの一例、というだけである
RISCユニットは同時2命令実行の構成で、他にロード×2、ベクトル演算×1、ストアー×1で同時6命令が実行可能、ということになっている。ただここで言う“Instruction”と、いわゆるOpsとはまた別らしい。というのは、2019年のHotChipsでは、下の画像が公開されている。
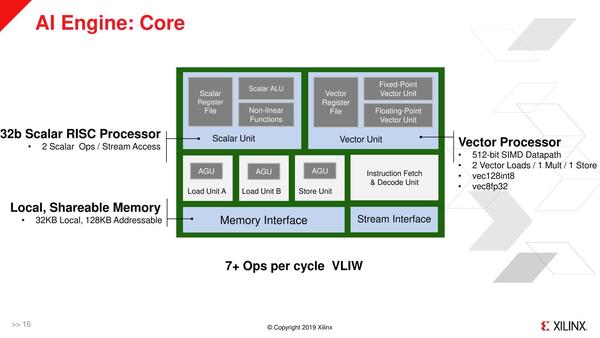
2019年のHotChipsで公開された内部構造。そもそもこの図で、Load/Store UnitがVector Registerに対してだけしか動かないのか、Scalar/Vector両対応なのかがよくわからないのだが、あるいはVector Load/StoreとScalar Load/Storeは別に数えているのかもしれない
このことから、以下のどちらか(あるいはこれ以外のなにか)の数え方をしているのではないかと思われる。
- 実はRISCプロセッサーの中で命令変換がかかっており、2つのRISC命令が実際には3~4個の内部命令(Ops)に分解されて実施されている
- Vectorプロセッサーでは、型変換(vec128int8/vec8fp32)が自動的に行なわれ、これを加味すると7~8命令相当になる
ここでVectorユニットは浮動小数点と固定小数点の両方が同時に動くことは基本的に考慮されていないと思われる。というのはAI/機械学習向けは浮動小数点を使うことがほとんどで、一方5Gを始めとする無線向けでは以前からDSPなどで固定小数点が利用されており、これに向けた格好である。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ








