




前回のTetraMemのPIMが意外に反響が大きかったのだが、PIM(Processor-In-Memory)というコンセプトそのものはかなり古くからあるし、実装もいろいろ試みられている。というより、チャレンジして敗れ去っていったメーカーが多数あるジャンルで、半ば死屍累々という感じではある。
ただ死屍累々というからには、そうした先人の敗退をモノともせずにチャレンジするメーカーがたくさんある、という裏返しでもある。実際今年のISSCCにおいてもSession 11(Compute-in-Memory and SRAM)というセッションには8つもの論文が出ている。一覧を紹介しよう。
| ISSCCのSession 11で発表されたPIMの論文 | ||||||
|---|---|---|---|---|---|---|
| 発表順 | 論文 | 著者 | ||||
| 11.1 | A 1ynm 1.25V 8Gb, 16Gb/s/pin GDDR6-based Accelerator-in-Memory supporting 1TFLOPS MAC Operation and Various Activation Functions for Deep-Learning Applications | SK Hynix | ||||
| 11.2 | A 22nm 4Mb STT-MRAM Data-Encrypted Near-Memory Computation Macro with a 192GB/s Read-and-Decryption Bandwidth and 25.1-55.1TOPS/W 8b MAC for AI Operations | 台湾国立清華大学とTSMCの共同 | ||||
| 11.3 | A 40-nm, 2M-Cell, 8b-Precision, Hybrid SLC-MLC PCM Computing-in-Memory Macro with 20.5 - 65.0TOPS/W for Tiny-AI Edge Devices | 台湾国立清華大学とTSMCの共同 | ||||
| 11.4 | An 8-Mb DC-Current-Free Binary-to-8b Precision ReRAM Nonvolatile Computing-in-Memory Macro using Time-Space-Readout with 1286.4 - 21.6TOPS/W for Edge-AI Devices | 台湾国立清華大学とTSMCの共同 | ||||
| 11.5 | Single-Mode CMOS 6T-SRAM Macros with Keeper-Loading-Free Peripherals and Row-Separate Dynamic Body Bias Achieving 2.53fW/bit Leakage for AIoT Sensing Platforms | 北京大学と中国Nano-Core Chipの共同 | ||||
| 11.6 | A 5-nm 254-TOPS/W 221-TOPS/mm2 Fully-Digital Computing-in-Memory Macro Supporting Wide-Range Dynamic-Voltage-Frequency Scaling and Simultaneous MAC and Write Operations | TSMC | ||||
| 11.7 | A 1.041-Mb/mm2 27.38-TOPS/W Signed-INT8 Dynamic-Logic-Based ADC-less SRAM Compute-In-Memory Macro in 28nm with Reconfigurable Bitwise Operation for AI and Embedded Applications | 北京大学とシンガポールNeoNexus、中国Pimchip Technology、米デューク大の共同 | ||||
| 11.8 | A 28nm 1Mb Time-Domain Computing-in-Memory 6T-SRAM Macro with a 6.6ns Latency, 1241GOPS and 37.01TOPS/W for 8b-MAC Operations for Edge-AI Devices | 台湾国立清華大と台湾工業技術研究院の共同 | ||||
「なんか台湾(というかTSMC)ばかりじゃないか?」と言われそうだが、2021年だとSession 15が"Compute-in-Memory Processor for Deep Neural Networks"で、米プリンストン大、中国清華大と中国Pi2star Technology・台湾工業技術研究院の共同、米ノースウェスタン大、中国清華大と中国電子科技大・台湾工業技術研究院の共同と合計4本の論文が出ているなど、必ずしも台湾/TSMCばかりというわけでもない。今回はそんな中からSK Hynixの論文を紹介しよう。
SK Hynixのものはタイトルの通り、1ynm世代(17~16nm)のGDDR6メモリーにMAC演算とアクティベーション関数を入れ込むことで、AI向けのPIMを開発した、というものだ。
GDDR6メモリーに演算ユニットを実装

同社におけるPIMの定義は、DRAMセルそのものに演算機能を持たせるのではなく、DRAMセルと演算ユニットを同一ダイ上に実装することで演算効率の向上を図るというもので、実装としてはSamsungのHBM-PIM(連載606回と連載636回)に近い。もっともSamsungの場合はHBM統合から一歩進んでAXDIMMみたいなものまで広げているが、SK Hynixはまだそこまでは踏み出していない。
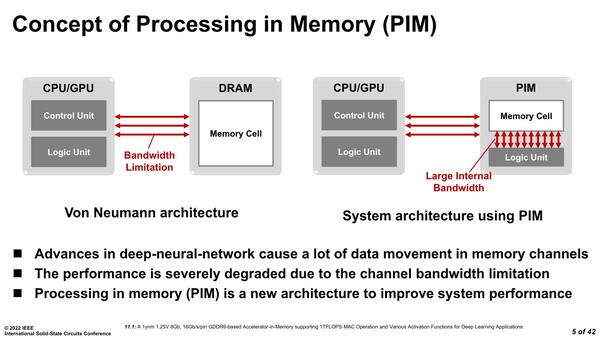
SK HynixによるPIMの定義。いや右だって、メモリーセルとロジックユニットが分離して配されているから結局フォン・ノイマンアーキテクチャーじゃないのか? と突っ込みを入れたくなるが、それはともかく。DRAMの会社としては、DRAMセルそのものにあれこれ工夫をするよりも、その外に置きたいのだろうという気持ちはわかる
SK Hynixが試作したものはAiM(Accelerator-in-Memory)と呼ばれている。最大の特徴は大幅に性能を引き上げていることで、チップ1つあたり1TFlopsに達している。また演算はBF16ベース、さらに活性化関数も6種類選べるといったあたりが違いとなっている。数字だけ見るとSamsungのHBM-PIMとあまり変わらないが、HBM-PIMはキューブ、つまりダイを8つ積層した数字であり、ダイ1つあたりの性能で言えば圧倒的にAiMの方が高速である。
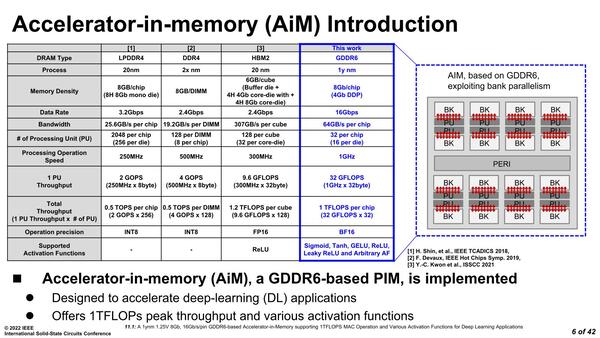
HBM2ベースのものが、Samsungが発表したHBM-PIMである
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















