



DBに最適化された新たなストレージアーキテクチャを採用、分析クエリが「最大100倍高速」に
Google Cloudが発表、PostgreSQL互換の高速DBサービス「AlloyDB」とは
2022年05月16日 07時00分更新

グーグル・クラウド・ジャパン(Google Cloud)は2022年5月12日、PostgreSQLとの完全互換性をうたうフルマネージドデータベース(DB)サービス、「AlloyDB for PostgreSQL」(プレビュー。以下、AlloyDB)を発表した。
オープンソースDBであるPostgreSQLとの互換性を維持しつつ、DBに最適化されたストレージアーキテクチャを採用して構築、さらにAI/機械学習による最適化なども適用することで高速化を実現している。さらにSLA 99.99%(予定)の高可用性、リニアなスケーラビリティ、AI/機械学習による運用管理の自動化なども特徴とする。
同日の記者説明会では、AlloyDBの特徴や高速化を実現できた技術背景、Google Cloudが提供する他のマネージドDBサービスとの違い、国内の早期導入顧客による評価、さらにデータベースのクラウド移行を支援/促進する新しいプログラムなどが紹介された。本稿では技術面の特徴を中心に概説する。
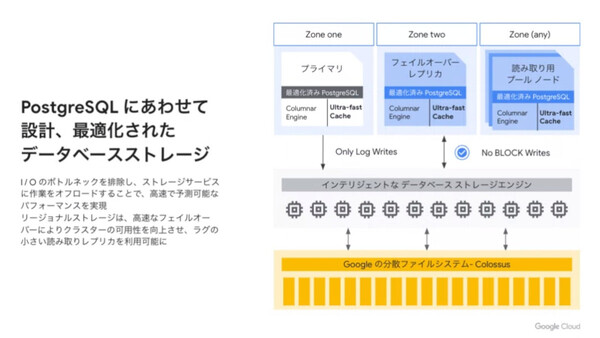
「AlloyDB for PostgreSQL」ではコンピュートとストレージのレイヤー分離を徹底し、DB処理に最適化されたストレージアーキテクチャで高速化を実現している

グーグル・クラウド・ジャパン ソリューション&テクノロジー部門 技術部長(データクラウド)の寳野雄太氏、ソリューション&テクノロジー部門 データベース ソリューションの江川大地氏、データ・プラットフォーム 事業開発部長の大久保順氏
レガシー商用DBからオープンソースDBへのモダナイズを支援
AlloyDB(アロイ・ディービーと読む)は、Google Cloudが提供する新たなフルマネージドDBサービスだ。
同社 ソリューション&テクノロジー部門 技術部長(データクラウド)の寳野雄太氏は、AlloyDBを提供する背景について、プロプライエタリな商用DB(Oracle DB、Microsoft SQL Serverなど)からオープンソースDBへの移行を阻む「商用グレードの機能ギャップ」を埋め、顧客企業におけるDBのモダナイズを加速させるものだと説明した。
「オープンソースDBでモダナイズしようとしても、現実にはスケールやパフォーマンス、可用性、管理の容易さ、リアルタイムでの洞察(分析)など、商用グレードDBとの機能のギャップがあり難しい。そういう声を多くいただく中でわれわれは、より良いオープンソースの互換DBが作れるのではないか、と考え始めた」(寶野氏)


オープンソースDBへの移行を望む声は強いものの、大きな機能差があり難しい。そこでPostgreSQLとの互換性を持ちつつ商用グレードの機能を実現するAlloyDBが開発された
PostgreSQL 14との完全互換を維持しつつ大幅に高速化
それでは具体的に、AlloyDBの特徴はどのようなものなのか。同社 ソリューション&テクノロジー部門 データベース ソリューションの江川大地氏は、大きく6つに絞って説明した。
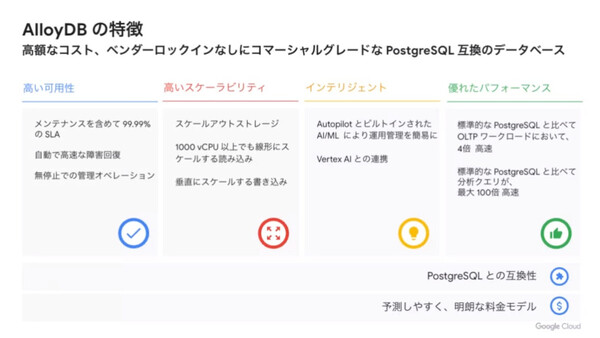
AlloyDBの特徴
まず注目されるのが「優れたパフォーマンス」だ。AlloyDBではPostgreSQLの処理に最適化された独自のストレージアーキテクチャを採用している(詳細は後述する)。
Google Cloudによる性能比較テストでは、AlloyDBは標準的なPostgreSQLと比較してトランザクション処理(OLTPワークロード)でも4倍以上、分析クエリでは最大100倍の高速化が確認できたという。また公式ブログでは「AlloyDBはAmazon(AWS)の類似サービスと比較して、トランザクションワークロードが2倍高速になる」と記している。
「Google Cloudの顧客企業では、リアルタイムの洞察やレポートなどで(DWHなどでなく)OLTPのデータベースを使用しているケースがある。そうした声を受けて、AlloyDBでは『カラム型エンジン』など分析処理にも役立つ機能を持たせている」(江川氏)


Google CloudによるAlloyDBの性能比較テスト結果(トランザクション処理はTPMで、分析クエリは処理秒数で比較)
こうした高速化を実現しつつ、AlloyDBではPostgreSQL 14との高い互換性を備えている。江川氏は、AlloyDBはPostgreSQLのパラメーター(フラグ)を175以上サポートするほか、50以上の拡張(Extension)もサポートしているため「既存のPostgreSQLと同じように扱える。既存のアプリケーションもコードの変更なしで、そのまま移行できる」と説明する。
また、利用料金については「予測しやすく、明朗な料金モデル」になっていると述べた。ライセンス料金やストレージI/Oベースの課金は発生せず、PostgreSQLを実行するコンピュートノードのサイズ(vCPUコア数、メモリ容量)や使用するストレージ容量だけで、容易に利用料金が予測できる。
ストレージレイヤーにより多くの処理をオフロード
AlloyDBが大幅な処理の高速化を実現した背景には、特殊なストレージアーキテクチャの存在がある。江川氏はその概要を紹介した。
Google Cloudでは「Cloud Spanner」や「BigQuery」といったDBサービスにおいて、コンピュートレイヤーとストレージレイヤーを分離させたアーキテクチャを採用している。分離することで、各レイヤーが独立してスケール可能になり、ワークロードに応じてパフォーマンスやデータ容量を柔軟に調整できる。
今回のAlloyDBにおいても、この「コンピュートとストレージの分離」という考え方が踏襲されている。特にAlloyDBでは、ストレージレイヤー内部をさらに2つのレイヤー(DBストレージエンジンと分散ファイルシステム)に分離させており、これがDB処理の高速化や可用性の向上、高いスケーラビリティに貢献している。

AlloyDBのアーキテクチャ概要。PostgreSQLノードはトランザクションログのみを書き込むので、ストレージI/Oのボトルネックが軽減される
実際のアーキテクチャを見てみたい。上図の中段にあるDBストレージエンジンは、PostgreSQLのコンピュートノード(図の上段)と分散ファイルシステム(図の下段)の間を媒介するレイヤーだ。この3つのレイヤーは、いずれも独立してスケールさせることができる。
PostgreSQLのプライマリノードがDBの書き込みを行うと、ストレージエンジンにはデータブロックではなくトランザクションログ(WAL:Write Ahead Log)が送信される。ストレージエンジンはそのログを一時保存し、ログに基づいてデータブロックを非同期に生成したうえで、分散ファイルシステム「Colossus」への書き込みを行う。つまり、書き込み処理の大部分がDBサーバー側からストレージ側にオフロードされている。
このように各レイヤーが役割分担を行うことで、ストレージI/Oのボトルネックが軽減され、低いレイテンシと高いパフォーマンス、柔軟なスケーラビリティ、コスト効率性などを実現している。AlloyDBでは、メンテナンスも含めて「SLA 99.99%」を予定しているが、そうした高い可用性にもこのアーキテクチャが寄与している。
また、PostgreSQLの読み込み専用レプリカノード(最大20ノードまで)は、プライマリノードとストレージを共有しており、データの移動やコピーなしに生成することができる。プライマリノードでDBの更新が発生した場合は、ストレージエンジンと同じようにトランザクションログを受け取って更新を行うため、タイムラグが最小化される。同一リージョン内の別ゾーンにレプリカノードを構成し、ゾーン障害に備えることも可能だ。
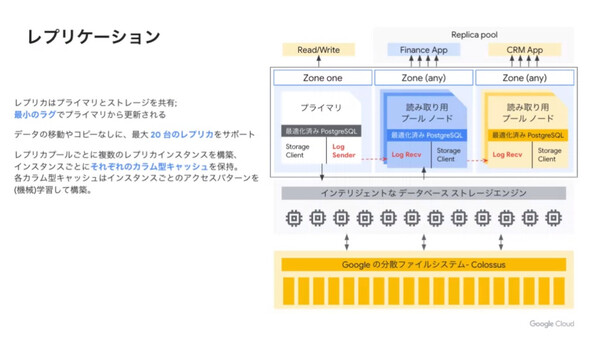
読み込み専用のレプリカノードをアプリケーションごとに用意すれば、DBキャッシュが各アプリケーションに最適化される利点もある
スケーラビリティについては、読み込み性能はレプリカノード群が1000vCPU以上の規模になってもリニアにスケールし、また書き込み性能もプライマリノードの最大インスタンスサイズまでリニアにスケールすると述べた。また可用性については、DB障害を60秒以内に自動検出/回復させる機能が盛り込まれているという。
なお、上述したアーキテクチャは単一リージョン内で構成されるもので、複数のリージョンをまたぐ構成はできない(同一リージョン内のゾーンをまたぐ構成はできる)。したがって、マルチリージョンのDBシステムを構成する場合は、AlloyDBではなくCloud Spannerの利用が推奨される。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



