



多様なデータソースを統合する「Dataplex」、CDC/レプリケーションの「Datastream」など
Google Cloud、“データクラウド”を構成する新サービス3つを紹介
2021年06月03日 07時00分更新

グーグル・クラウド・ジャパン(Google Cloud)は2021年6月2日、Google Cloudの“データクラウド”戦略および最新のデータ関連サービスに関する記者説明会を開催した。先月発表された3つの新サービス、多様なデータソースを統合分析可能にするデータファブリック「Dataplex」、スケーラブルなリアルタイムデータ複製を可能にする「Datastream」、データのみならずデータ分析の“手法”までを組織間で共有できる「Analytics Hub」が紹介された。
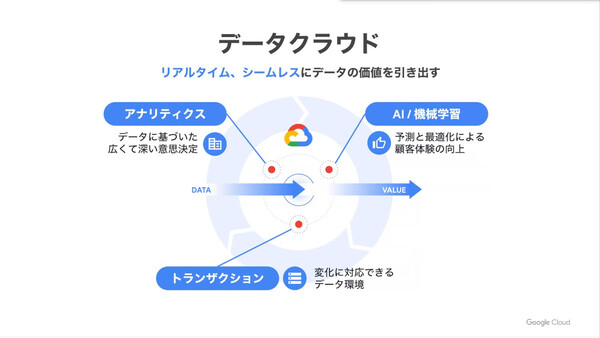
Google Cloudが考える“データクラウド”の要件

説明会に出席したGoogle Cloud ソリューション&テクノロジーグループ 技術部長(アナリティクス/機械学習、データベース)の寶野(ほうの)雄太氏
Google Cloudがデータクラウドとして重視している4つのポイント
説明会に出席したGoogle Cloud 技術部長(アナリティクス/機械学習、データベース)の寶野雄太氏はまず、企業におけるDX(デジタルトランスフォーメーション)の取り組みにおいて必須となるデータ活用について、「その実現のためには3つの要素が不可欠」だと説明した。
「1つめは、データに基づく意思決定を、あらゆる部署のあらゆるユーザー(従業員)が行えるようになること。またデータを永続的に収集、分析することで、より広く深いビジネス意思決定ができるようになる。次に、データを機械学習で活用することで、さまざまなイノベーションが起こせるようになる。たとえばレコメンデーションで顧客体験を向上させたり、ビジネス上の差別化も図っていける。ただし、ここでは常に新しいデータで機械学習モデルを更新し、変化に対応できる仕組みも求められる。最後に、アプリケーションを支える柔軟なデータ環境も必要だ。データ活用で得られた知見をもとにビジネス戦略を修正し、それをITアーキテクチャに反映し続けることになるからだ」
そして、Google Cloudでデータクラウドを構築することにより、これら3つの要件をすべて満たすことができ、「データの価値をリアルタイム、シームレスに引き出すことが可能になる」と説明する。
寶野氏は、Google Cloudが重視している4つのポイントについても説明した。オープンソースツールを選択できたり、Google Cloud独自の技術を別の場所(クラウド)でも動かせたり(ポータビリティ)する「オープンさ」、機械学習をいち早くあるいは自動で活用できるサービスの「インテリジェンス」、ガバナンスとセキュリティのフレームワークによる「信頼性」、そしてデータをリアルタイムなアクションにつなげるための高い処理能力と分散スケール能力を持つ「プラネットスケール」の4つだ。
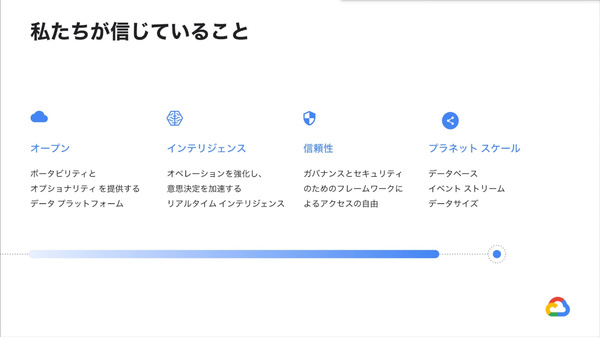
Google Cloudがデータクラウドで重視する4つのポイント
データクラウドを構成する3つの新しいサービスを紹介
続いて寶野氏は、Google Cloudが先月発表した3つのデータ関連サービスについて説明した。
Dataplex(プレビューリリース)は、企業内のデータウェアハウス(DWH)、データレイク、データマート、データベースに分散しているデータの管理や分析を統合することで、“データサイロ”を解消するデータファブリックサービスだ。「データの移動や重複(コピー)を回避しつつ、ビジネスに有意義な方法でデータを整理し管理する」ことを基本コンセプトとしている。
Dataplexでは、基盤となるデータソース(ストレージ)を抽象化して、レイク/データゾーン/アセットという抽象化された単位でデータの統合を可能にする。たとえば部門ごとにレイクを持ち、そのレイク内でデータ種別や使用方法に応じたゾーンを作成し、そこに個別データ=アセットを格納するイメージだ。ポリシーはレイク/ゾーン/アセット単位で一括適用できるため、データ管理者はセキュリティやガバナンスを維持しながら、データ分析者に自由なデータ利用を許可できる。
「データ分析者から見ると、データがどこにあろうとも一元的に整理してインテグレーションし、すぐに分析できる。しかも、データがどこにあろうともSQLや(Jupyter)Notebookといった同じ分析手法やツールが使え、同じ分析体験を享受できる。他方で管理者側から見ると、データへのアクセス制御やデータライフサイクルポリシーを一元化できるほか、メタデータからデータの意味を知ることもできる。データのクオリティが低ければ自動的にアラートを出すといった機能も備える」

データファブリックサービス「Dataplex」の概要
次のDatastream(プレビューリリース)は、変更データキャプチャ(CDC:Change Data Capture)/レプリケーションサービス。異種データベース/ストレージ/アプリケーション間で、レイテンシを最小限に抑えながらデータの同期を行う。
これにより、リアルタイムのデータ分析やデータベースレプリケーション、イベントドリブンアーキテクチャをサポートする。「Oracle Database」や「MySQL」のデータベース変更ストリームを、「BigQuery」や「Cloud SQL」「Google Cloud Storage」「Spanner」などのGoogle Cloudサービスに配信することも容易だという。また、サーバーレスアーキテクチャで開発されており、データ量の増減に応じてシームレスかつリアルタイムにスケールアップ/ダウンできることも特徴としている。
Datastreamのユースケースとして寶野氏は、ECサイトにおける「在庫データのリアルタイム分析」「データベースのモダナイズ」という2つの例を挙げた。後者については、トランザクションの急増で従来のデータベースでは処理がまかなえなくなった場合に、Datastreamでリアルタイムにレプリケーションした読み出し専用データベースを用意し、商品の参照や検索処理はこちらにオフロードするというものだ。「こうしたニーズをお客様から非常に多くいただいている」。
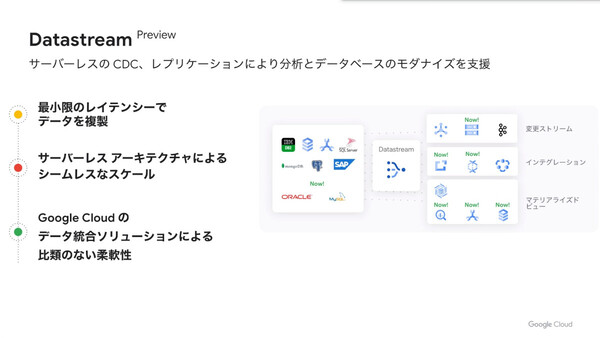
データのCDC/レプリケーションサービス「Datastream」の概要
3つめのAnalytics Hub(第3四半期にプレビューリリース予定)は、BigQueryを基盤として、異なる組織/企業間でデータセットや分析アセット(BigQuery MLモデル、Looker Blocks、データ品質レシピなど)を公開/共有/交換できるサービスとなる。
200を超える一般データセット(気象、暗号通貨、医療、運輸など)のほか、Googleが提供するデータセット(Googleトレンドなど)、さらにデータプロバイダーが販売する商用データセットなどが提供され、ユーザーはセルフサービス型でこうしたデータを購読(サブスクライブ)し、自社で活用することができる。
寶野氏は、これまではBigQueryのストレージを通じて組織横断でのデータ共有が盛んに行われてきたと語る。たとえば今年4月の数字を見ると、7日間で3000以上の異なる組織が、200ペタバイト以上のデータを共有していたという。
Analytics Hubはこれをさらに機能拡張したサービスとなる。寶野氏は、その特徴として「データ分析のやり方(分析アセット)まで共有できる」点だと説明した。「単にデータを共有するだけでなく、たとえば『BIツールのLookerではこのように可視化できます、このようなテンプレートがあります』といった使い方までをシェアできる。ここが大きな違いだ」。
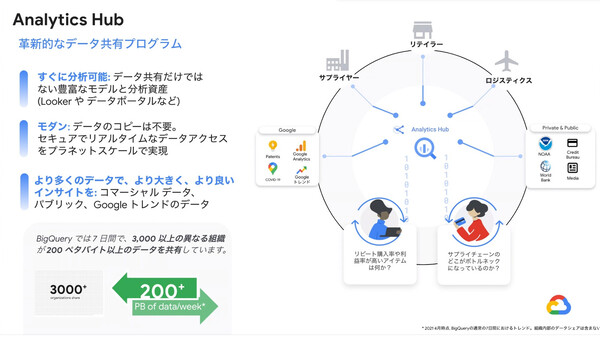
データおよびデータ分析手法の共有基盤となる「Analytics Hub」の概要
寶野氏はもうひとつ、Google Cloudでは業種別のデータソリューションも提供していることを紹介した。各業界に特化したサービスと機械学習モデルを用意しており、「Google Cloudにデータを入れていただければ、自動的に機械学習でビジネス課題を解決することが可能だ」と説明した。たとえば小売・日用品業界では、BigQueryに売上データを蓄積しておくだけで、レコメンデーションエンジンを使った商品のレコメンドが可能だという。
まとめとして寶野氏は、Google Cloudでは「オープンでインテリジェントな信頼性の高い統合データプラットフォーム」を提供しており、「顧客ニーズに応えること、分散したデータを扱うこと、安全でスケーラブルな方法で分析結果を共有することに注力している」と述べた。
またGoogle Cloudのデータクラウド戦略でユニークな点はどこか、という質問に対しては、データ処理/分析/機械学習のエンジンやユーザーツールを自由に選択し、組み合わせて利用できるオープンな環境を目指している点だと述べた。
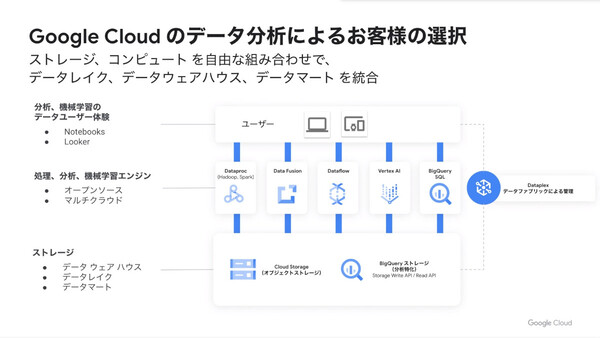
顧客が使いたいストレージやエンジン、ツールを組み合わせて使える「オープンさ」が特徴だと説明した
本記事はアフィリエイトプログラムによる収益を得ている場合があります



