



「Google Cloud Next '21」で発表されたデータクラウド領域の新発表について説明
「BigQuery Omni」やサーバーレスSparkなど、Google Cloudが披露
2021年10月14日 07時00分更新

グーグル・クラウド・ジャパン(Google Cloud)は2021年10月13日、同日からスタートした年次イベント「Google Cloud NEXT '21」で発表された、データクラウドおよびオープンクラウド領域の新サービスや新機能についての記者説明会を開催した。
本稿ではまず“マルチクラウド対応BigQuery”の「BigQuery Omni」一般提供開始、サーバーレスSpark「Spark on Google Cloud」、「Spanner PosgtreSQL interface」といったデータクラウド領域における新発表について紹介したい。オープンクラウド領域については稿を改めてお伝えする。

年次イベント「Google Cloud NEXT '21」がオンラインで開幕した


グーグル・クラウド・ジャパン 技術部長(アナリティクス/機械学習、データベース)の寶野雄太氏、同 技術部長(インフラストラクチャ&アプリケーション モダナイゼーション)の安原稔貴氏
“トランスフォーメーションクラウド”を構成するデータクラウド
Google Cloudでは、顧客ビジネスのデジタル変革/DXを実現する新世代の“トランスフォーメーションクラウド”ビジョンを掲げてクラウドサービスの拡充を進めている。具体的には、データ活用で組織のスマート化を推進する「データクラウド」、市場の変化に素早く対応するクラウドインフラを提供する「オープンクラウド」、柔軟な働き方を実現する「ピープルクラウド」、ビジネスの要素を保護する「トラステッドクラウド」という4領域のサービス群で構成される。
「クラウドを使って会社全体を変革する」ことが求められる時代に対応して、Google Cloudが提供するのが「トランスフォーメーションクラウド」
今回の説明会ではデータクラウド領域の主要な新発表について、グーグル・クラウド・ジャパン 技術部長(アナリティクス/機械学習、データベース)の寶野雄太氏が説明を行った。
AWSやAzure上のデータを移動せず分散処理「BigQuery Omni」
データクラウド領域ではまず“データのサイロ化”を解消するサービスとして、ハイブリッド/マルチクラウド環境にまたがる大規模なデータのアナリティクスや統合を実現する「BigQuery Omni」の一般提供(GA)が発表されている。これは「Google Cloudだけでなく、AWSやAzureのストレージにあるデータに対しても、同じツール(BigQuery)で一気に分析がかけられるサービス」(寶野氏)。
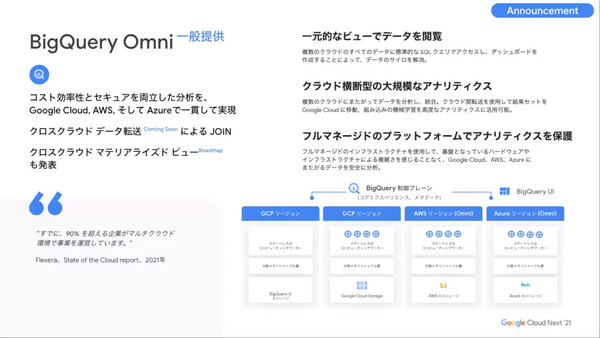
「BigQuery Omni」の一般提供を発表
具体的なアーキテクチャを見ると、マルチクラウドに対応するコンテナプラットフォームの「Anthos」が基盤となっており、コンテナ化されたBigQueryのクエリエンジンを他社クラウド(AWS、Azure)にも展開して、Google Cloud上にある単一のBigQueryコントロールプレーンから一元的に管理する仕組みだ。したがって、BigQueryでの分析実行前にデータをGoogle Cloudに移動/コピーする必要はなく、分析の実行や結果表示もすべてBigQueryのインタフェース(GUIやAPI、CLI)から行える。
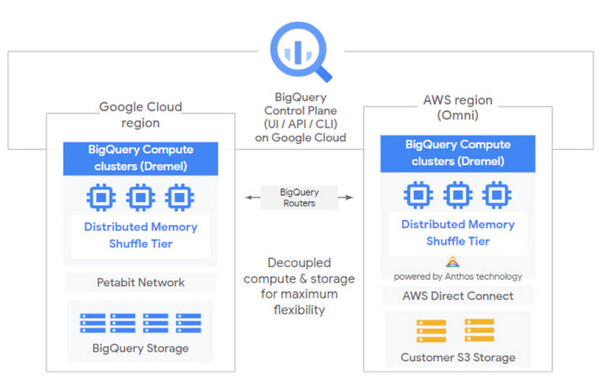
マルチクラウドで稼働するBigQuery Omniのアーキテクチャ(画像は公式ブログより)
これに加え、今回はBigQuery Omniの分散アーキテクチャを生かした新機能として、ソースとなるクラウド側で一定の処理を行ったうえでデータを転送し、JOINできる「クロスクラウドデータ転送」(近日追加予定)、マルチクラウド間のデータでマテリアライズドビューが構築できる「クロスクラウド マテリアライズドビュー」(将来提供予定)も発表されている。
また、BigQueryに保存されているデータ活用を促進するものとして、「Cloud Functions」を利用するPython、Node.js、Go、Rugyなどの外部関数をBigQueryから呼び出せる「BigQuery外部関数」(近日追加予定)、数億行のログデータから1行を検索するような処理を改善する「BigQuery検索インデックス」(プレビュー)も紹介された。
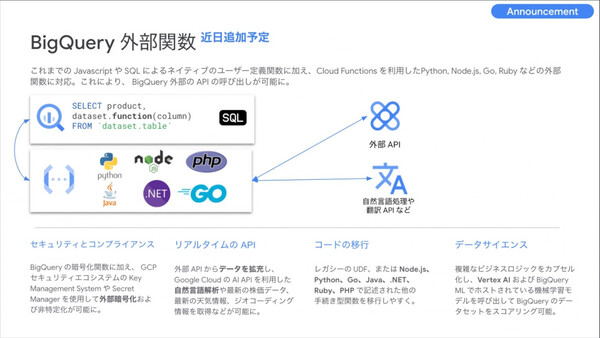
「BigQuery外部関数」の概要。「BigQueryのSQLからCloud Functionsを起動し、外部APIでデータ処理して再度BigQueryに取り込む、あるいは外部APIから新しいデータを取り込むといった使い方ができる」(寶野氏)
データファブリックサービスの「Dataplex」も一般提供が発表された。これは企業のデータウェアハウス(DWH)、データレイク、データマート、データベースなどに分散配置されたデータを、その場所から移動させることなく統合、管理するサービスだ。

データファブリック「Dataplex」も一般提供となった
インフラ管理不要のサーバーレスSpark「Spark on Google Cloud」
寶野氏が「今回の中でも非常に新しく、大きな発表だった」と紹介したのが、“業界初のサーバーレスSpark”をうたう「Spark on Google Cloud」(プレビュー)だ。Sparkをサーバーレス環境で構築しており、開発したジョブをすぐに実行可能で、そのジョブに応じてオートスケーリングも行われる。
寶野氏は、Sparkはデータサイエンティストに人気がある一方で、これまではコンピュートクラスタを設計、構築、管理する必要があるため、「Sparkジョブの開発には40%の時間しか使えていなかった」と説明。これをサーバーレスで提供することにより、データサイエンティストはジョブ開発に専念できると述べた。
なおこのSpark on Google Cloudは、Google Cloudの各種データクラウドサービスとも統合を進める。たとえばBigQueryとの統合により、BigQuery上にあるデータに対して、データ移動なしでSparkジョブを実行できる。またDataplexとの統合では、Dataplexの管理下にあるデータのETL処理にSparkが利用可能となる(いずれも近日追加予定)。

「Spark on Google Cloud」はサーバーレスのマネージドサービスであり、Sparkジョブ開発に専念できる
「Spanner」のPosgtreSQL互換インタフェース、「Looker」とコネクテッドシート統合
“データ洞察の民主化”というテーマでは、「Spanner PostgreSQL interface」(プレビュー)や「Looker」の機能強化が発表された。
Spannerは、SLA 99.999%の可用性を持つGoogle Cloudの分散リレーショナルデータベースサービスだが、これまでは独自インタフェース(API、SQL)から利用する必要があった。このSpannerにPostgreSQL互換のインタフェースを提供するのがSpanner PostgreSQL interfaceである。これにより、PostgreSQLのスキルを持つエンジニアの利用や、PostgreSQLを使ったアプリケーションのデータベース移行が簡単になると、寶野氏は説明した。
Lookerについては3つの新発表があった。そのうち「Looker+コネクテッドシート」では、GoogleスプレッドシートでBigQueryエンジンによる大規模データ分析ができるコネクテッドシート機能にLookerが統合される。「この統合によって、Lookerのセマンティックモデルを使いながら、ビジネスユーザーのデータ探索がより加速していく」(寶野氏)。

Lookerに関する3つの新発表。Googleスプレッドシートの「コネクテッドシート」とも統合される
MLモデリングの統合ノートブックインタフェース「Vertex AI Workbench」
“高速なML(機械学習)モデリング”というテーマでは、今年の「Google I/O」で発表した機械学習プラットフォーム「Vertex AI」において、データサイエンティスト向けのノートブックインタフェース「Vertex AI Workbench」(プレビュー)を発表している。
「Vertex AI Workbenchは、ノートブックインタフェースをさまざまなGoogle Cloudのツールと統合して、MLOpsに組み込んだかたちで提供するもの。これにより、さまざまなツールを行き来することなく、単一のインタフェースからより高速にプロトタイプとモデル開発ができるようになる。従来型のノートブックに比べて5倍速い開発を可能にする」(寶野氏)
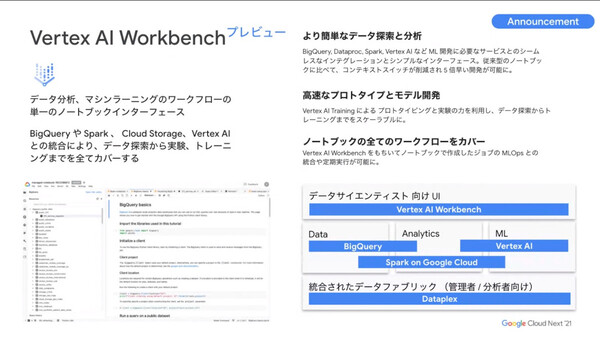
「Vertex AI Workbench」の概要
さらに、このノートブックで作成したMLモデルの工程をそのままVertex AIに持ち込むことで、モデル生成の自動化やコンプライアンスが実現すると述べた。
加えてVertex AI Workbenchは、前述したSpark on Google Cloudとも連携するという。「Workbenchの中でSparkのジョブを作成し、サーバーレスSparkで実行する、そのような一連の動作も近日追加予定だ」(寶野氏)。これにより、MLモデルの開発や学習の作業が非常にストレスなく実行できるようになると紹介した。
* * *
データクラウド領域における今回の発表のまとめとして、寶野氏は次のようにGoogle Cloudの方向性をあらためて説明した。
「今回はディテールを紹介したが、Google Cloudのビジョンは非常にシンプル。データアナリティクスや機械学習、あるいはトランザクショナルデータベースを一元的に扱えるようにして、ユーザーがデータの真価を解き放つことを支援する。そのために、インタフェースの統合などの部分は非常に注力しているし、インフラを意識しなくても大規模なデータ処理を実現できる環境を提供するということを基本的としている」(寶野氏)
本記事はアフィリエイトプログラムによる収益を得ている場合があります



