ロードマップでわかる!当世プロセッサー事情 第644回
業界初のマルチダイGPUとなるRadeon Instinct MI200の見事な構成 AMD GPUロードマップ
2021年12月06日 12時00分更新

全データ型でSIMD演算ユニットが16wide固定になった
MI200のXCU構造
そうした周辺の違いもさることながら、コアとなるXCUの構造も変化している。下の画像はMI100にあるXCUの内部構造である。1つのXCUに4組のVector/Matrix SIMDが搭載される。このVector/Matrix SIMDは以下の構成になっている。
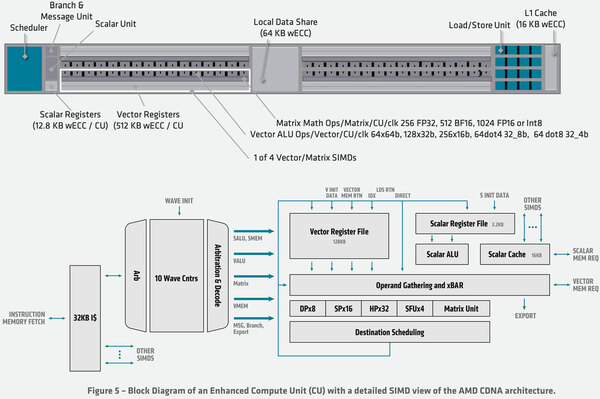
MI100のコアとなるXCUの内部構造。このWaveの周りやRegister FileのサイズなどがMI200でどう変化したのかは今のところ公開されていない
| Vector/Matrix SIMDの構成 | ||||||
|---|---|---|---|---|---|---|
| Dual Precision(DP:64bit) | 同時8演算 | |||||
| Single Precision(SP:32bit) | 同時16演算 | |||||
| Half Precision(HP:16bit) | 同時32演算 | |||||
| Quarter Precision(QP:8bit) | 同時64演算 | |||||
| Special Function(SFU) | 同時4演算 | |||||
| Matrix Unit | 同時1演算 | |||||
DP/SP/HP/QP/SFUはSIMD Unitを動かし、マトリックスの場合はMatrix Unitが動くという排他構造になっている。まずSIMDの方でいくと、演算幅は512bitで、これをデータ幅に合わせて分割するという方式であり、Vector Registerは512bit幅であり、Register Fileは256個のVector Registerで構成されている。
一方Matrix Unitの方はこれとは別の動作になっており、最大で8096bit分の処理を1サイクルで行なえるが、対象はFP32(256演算)/BF16(512演算)/FP16(1024演算)/Int 8(1024演算)に限られている。このSIMD/Matrix Unitは10本のWave(スレッドにあたる処理単位)で共有というか、準備ができたWaveから順に実行していくような形になっている。
対するMI200のXCUの構造が下の画像だ。一見MI100のXCUと差がないように見えるが、大きな違いは「データ型によらず、SIMD演算ユニットは16wideなこと」である。つまりDual Precisionでも同時16演算が可能になっているわけだ。逆に言えばSingle Precisionでは変わらず16演算のままで、Half/Qualter Precisionではむしろ同時演算数が減る形になる。
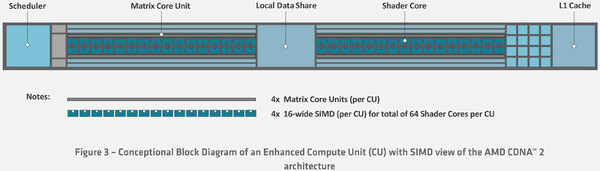
MI200のXCU構造。こちらもいずれもう少し詳細が出てくることを期待したい
なぜこんな実装にしたか? であるが、特にHPC向けに関して言えば、FP64の演算性能を引き上げるのは大命題(Frontierの要求性能がFP64でのものだから、ここを引き上げざるを得ない)であり、ベクトルでこれを16個並べるのは必須である。ただ、これを32個のFP32や64個のFP16に分割させるためには、さらに余分な回路が必要になる。命令セットも当然複雑になるため、回路規模がやや増えることは間違いない。
問題はそこまで回路規模を増やしてFP32/FP16の演算性能を引き上げる必要があるのか? という話になるが、FP32/FP16に関してはMatrix Unitでもサポートを追加しているので、こちらで処理すればいいという判断が下されたのだろう。実際、演算性能で比較してもMI200はFP64とFP32のどちらも47.9TFlopsを発揮でき、これはMI100はもとよりNVIDIAのA100と比較しても十分高い。
今回、仮にTSMCのN5を使えれば、だいぶトランジスタ密度が上げられるからそうした対応もあり得るだろうが、TSMCのN6ではN7と比較してそれほどトランジスタ密度は上がらない(TSMCによれば18%の向上)で、この分はFP64の増強に充ててしまって足が出た(のでCU数が微妙に減った)から、ここは素直に全データ型で16wide固定という、やや回路規模が減らせる方策を取ったのではないかと思う。
一方Matrix Unitの方は詳細が公開されていないが、ホワイトペーパーから数字を拾うと以下のとおりで、FP64のサポートとFP16のスループットを引き上げた以外はMI100と同じ構成になっている。
| Matrix Unitの構成 | ||||||
|---|---|---|---|---|---|---|
| MI100 | MI200 | |||||
| FP64 | N/A | 256 | ||||
| FP32 | 256 | 256 | ||||
| FP16 | 1024 | 1024 | ||||
| BF16 | 512 | 1024 | ||||
| INT8 | 1024 | 1024(いずれもFlops/Clock/CU) | ||||
こちらも、やはりトランジスタ数がそこまで潤沢にないので、ギリギリのところを狙ったというあたりだろうか。
ちなみにわかりやすいFP64 Vectorの性能で言えば、MI100が23.1TFlops、MI250Xが47.9TFlopsとなっている。MI100は120CU構成だから理論値は1504MHz駆動(実際は最大1502MHz)で、ここからMI250Xは1700MHzあたりで動作している計算となる。
巨大なダイ2つを接続する難題を
銅柱でチップを浮かすことで解決
次にパッケージについて。AMDは今回Radeon Instinctで700mm2を超えるダイ2つを接続する必要が出てきた。実はここに、従来のCoWoSは利用できない。なぜかと言えば、CoWoSのシリコン・インターポーザーも従来の半導体同様の製法で作る関係で、1回の露光で製造できるインターポーザーの面積は800mm2かそこらが限界になるからだ。
逆に言えば、1回の露光でこれを超えるインターポーザーが作れるなら、ダイもそれだけ大型化できることになる。現実問題、1400mm2+HBMの分をまとめて製造できるインターポーザーは存在しない。
これに対しての1つの解は、インテルのEMIBである。ダイ全体をカバーするのではなく、接続用のBallのところだけにインターポーザーを埋め込む形だ。ただこれはインテル独自の技術で、インターポーザーを従来のパッケージ基板に埋め込むのが意外に高コストであった。
そこでAMDは、従来型のシリコン・インターポーザーを2つのダイ間、およびダイとHBM2eの間に埋め込んで接続をするが、その周囲に銅の柱を立ててチップ全体を浮かすという形でこれを解決した。
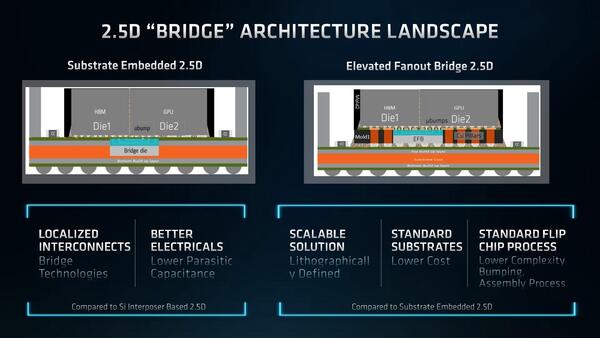
左がインテルのEMIBである。右が銅の柱を立ててチップ全体を浮かすAMDのブリッジ方式だ
この結果として、多少伝達特性は悪化する(シリコン・サブストレートを介さない電源ピンや外部への配線は、パッケージとダイの距離がやや離れることになるため)ものの、はるかに低コストで実現できるようになったとしている。
同じくマルチダイ(マルチタイル)構成のインテルのPonte VecchioがEMIBとFoverosを駆使してものすごく複雑な接続をしていることと比較するとやや見劣りするとも言えるが、逆に低コストで確実に利用できるわけで、これはこれで良い技術と言える。
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ













