



ロードマップでわかる!当世プロセッサー事情 第640回
AI向けではないがAI用途にも使えるCoherent LogixのHyperX AIプロセッサーの昨今
2021年11月08日 12時00分更新

MNP(Memory-Networked Processing)アーキテクチャーは
メモリーと演算ユニットを格子状に配置して重ねる構成
Linley Processor Conferenceでの説明は、それではMNPとはなにか? という話から入る。既存のアーキテクチャーは大抵の場合Unified Memory、つまりメモリーシステムは1ヵ所にまとまり、ここにシステムのその他のユニットからアクセスされる形をとる。この結果としてこのメモリーシステムがシステム全体のボトルネックになるという話だ。
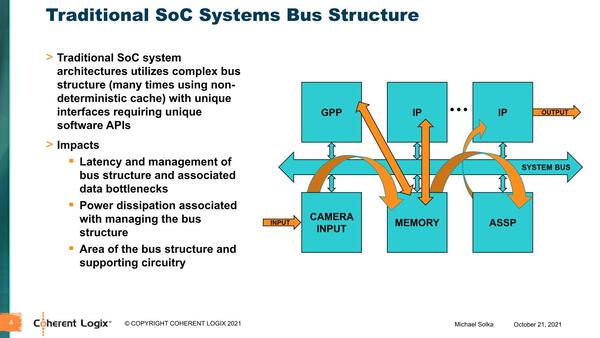
ある程度大きくなるとシステムを分割したNUMA(Non-Unified Memory Access)方式を取ったりもするが、今回の話はもっと極端である
単に帯域だけではなくレイテンシーも増えやすいし、広帯域/低レイテンシーなバスは消費電力、エリアサイズともに大きくなる。最近CPUが大容量キャッシュを搭載するようになったのも、メモリーシステムそのものがシステムの要求に追いつかなくなってきたため、これを緩和するためという用途に加え、バスネックを少しでも減らしたいという目的もあることを考えれば、少なくともこのスライドの言っていることは正しい。
この問題を解決するために、MNPではメモリー(DMR)と演算ユニット(PE)をそれぞれ格子状に配置して重ねるというおもしろい構成を取っている。PEは隣接するDMRからデータを取得し、演算結果はまた隣接するDMRに送り出す形になる。DMRは自身もメモリーを持つとともに、自身にないデータは隣接するDMRから取得する(逆にPEから格納された演算結果を必要に応じて別のPEに送り出す)という仕組みになっている。
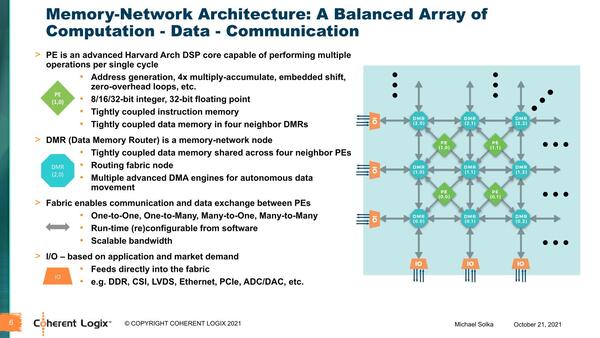
個々のPEはこのスライドにもあるように、基本的には32bitのDSPである。だから、プログラムを書き換えるまでは、同じ処理を延々と繰り返すか、DMR待ちの間は止まることになる
外部メモリーもI/Oの扱いになっており、使い方としては煩雑にメモリーアクセスするというのではなく、必要に応じてブロック単位で読み込み、各DMRに分散させて格納。PEはあくまでもDMRしか見ずに演算するという、昨今のAIプロセッサーと同じ仕組みになっている。
スライドが前後するが、このMNP構成の演算ユニットをまとめたものを、同社ではHyperXアーキテクチャーと称している。おもしろいのは、このPEをどう組み合わせるかを自由に定義できることだ。
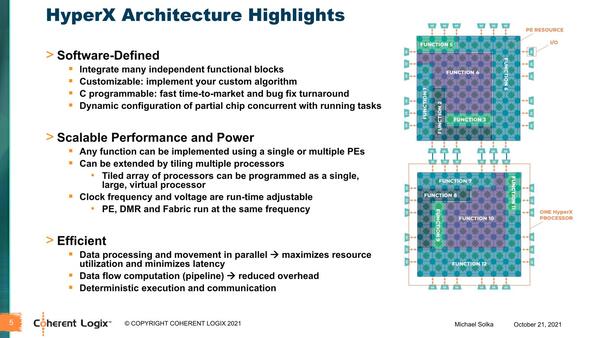
PEの組み合わせを自由に定義できる。おそらくDMR経由でInstruction Memoryの書き換えも可能になっているものと思われる
各PEはそれぞれ独自にInstruction Memoryを保持しているので、PE単体でももちろん動作するが、複数組み合わせて機能ブロック(Function Block)を構成することもできる。このブロックをどう組み合わせるかはプログラマーが定義でき、なんなら稼働中にブロック構造を動的に変更することも可能とされる。さらに上図にあるように、I/Oを経由して複数のHyperXチップを結合することも可能である。
ところでこの構図、「DMRからデータが取れる、あるいはDMRに結果を書き出せる」時はPEは稼働し、「データが来てない、もしくはデータを書き込めない」時にはPEが止まることになる。つまりデータの有無で動作制御できるわけで、事実上のデータフロー構成のプロセッサーとして稼働しているわけだ。このあたりの特徴だけ見ると、昨今のAIプロセッサーそのものという感じである。
ちなみに同社によれば、HyperXは6レベルの並列性があるとしている。まずブロック単位の処理(=タスク)で言えば、1つのブロックに複数のPEを含めるので、SIMD的な処理も可能で、個々のPEで別々の処理もできるから、その場合はMIMD動作になる。
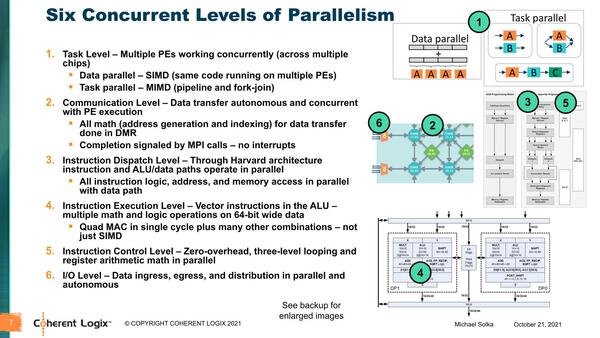
HyperXは6レベルの並列性がある。3~5は1つにまとめてしまっても良い気がするのだが。それでも4レベルの並行性がある
またPEの稼働にともなう通信は全自動で行なわれ、PE内部も複数の同時処理が可能(SIMD演算を含むVILW命令)で、I/Oも複数を同時に動作できる。これを支えるのはDMR同士の通信であるが、リンク帯域は1方向あたり192Gbpsに達し、チップ全体では5Tbit/秒以上の帯域を誇ることになる。
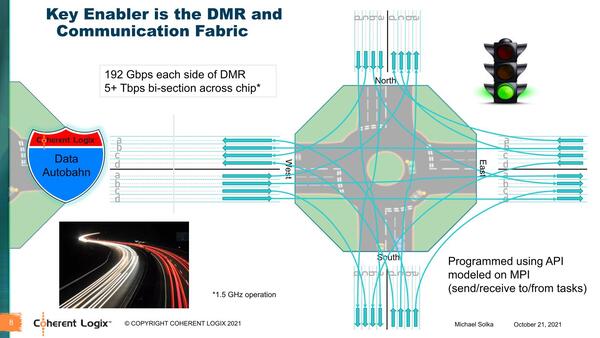
タスク同士の通信はMPIを利用するようだ
この連載の記事
-
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 -
第854回
PC
巨大ラジエーターで熱管理! NVIDIA GB200/300搭載NVL72ラックがもたらす次世代AIインフラの全貌 - この連載の一覧へ
















の1台が今ならオトク!")





























")













