



併用するAWS「Redshift」との使い分けは? Google Cloud「Data Cloud Summit」レポート
NTTドコモがペタバイト級分析基盤で「BigQuery」本格運用開始、背景を語る
2021年09月08日 07時00分更新

グーグル・クラウド・ジャパン(Google Cloud)では2021年9月7日~10日の日程で、トランザクショナルデータベースやデータ分析ソリューションに特化したオンラインイベント「Data Cloud Summit」を開催している。

Google Cloudの「Data Cloud Summit」は9月10日まで開催中。セッションのオンデマンド配信も実施
初日のセッションではNTTドコモ サービスイノベーション部 エンジニアの林 知範氏が登壇し、同社が2014年から構築、運用してきたビッグデータ分析基盤「IDAP」において、Google Cloudの「BigQuery」を今年から本格導入した背景や、オンプレミス環境やAmazon Web Services(AWS)環境と組み合わせたアーキテクチャ、BigQuery採用で得られたメリット、BigQuery活用のうえでのTipsなどを紹介した。
本稿では、その後に開催されたGoogle Cloudの記者説明会における質疑応答の内容も合わせて、同セッションをレポートする。


NTTドコモ サービスイノベーション部 エンジニアの林 知範氏、グーグル・クラウド・ジャパン 技術部長(アナリティクス/機械学習、データベース)の寳野(ほうの)雄太氏
社内2500人が活用する5PBのビッグデータ分析基盤「IDAP」
NTTドコモのIDAP(Integrated Data Analytics Platform)は、同社が社内のデータ分析者(データサイエンティスト)向けに自社開発/運用しているデータ管理基盤(DMP)だ。

NTTドコモの「IDAP(Integrated Data Analytics Platform)」概要
IDAPには通信事業のネットワーク系データ、スマートライフ事業のサービス系データが蓄積されており、ユーザー登録している社内分析者は現在およそ2500人、1日あたりのデータ処理量は50TB以上、分析可能な総保有データ量は5PB以上という、巨大なデータ分析基盤である。

IDAPの総保有データ量は5ペタバイト以上に及ぶ
IDAPは2014年8月、オンプレミス環境+AWS環境で運用を開始した。その時点ではAWSのデータウェアハウス(DWH)サービス「Amazon Redshift」125台構成をとり、さらに2年半後の2017年1月には、データ量の増加に対応するため同規模のクラスタをもう1つ追加している。
実はこの2017年時点で一度、Google Cloud/BigQueryの採用も検討されていたが、当時はIDAPで求めるセキュリティ要件や性能要件を満たさず、見送られた。
しかし、翌2018年の12月にGoogle Cloudが「VPC Service Controls」の一般提供を開始(GA)し、セキュリティ要件が満たされることになった。そこで、2019年3月に再びBigQueryの性能検証を実施。さらに、Google Cloudのエンジニアとも議論を重ねることで、「2018年度と比べて大幅な性能向上が確認できた」(林氏)という。
「性能検証の結果、一部で性能要件を満たせていない部分も見つかった。ここについてはまず、Google Cloudジャパンのエンジニアと原因分析のディスカッションを行って原因を特定。そのうえでBigQueryの開発エンジニアを訪問し、IDAPにおけるユースケースや改善要望などを伝えた。その結果、性能要件を十分に満たすレベルまでBigQueryが改善された」
これで導入のめどがついたため、2020年10月にはパイロットユーザー向けにBigQueryの小規模導入を実施。「ユーザーから性能面、機能面で高い評価が多数寄せられたため」(林氏)そのまま導入を拡大し、2021年7月から本格運用を開始している。

IDAPの誕生から現在までの変遷
Google Cloud/BigQueryに魅力を感じた理由
オンプレミス+AWSで構成されていたIDAPに、なぜBigQueryも加えることになったのか。
林氏は、分析を行うデータ量が大幅に増加するなかで基盤構成を最適化する必要があり、検討を開始したと話す。IDAPの中核となるDWHサービスを、性能面、機能面で検討していった結果、BigQueryに大きな魅力を感じるようになったという。

Google Cloud/BigQueryの導入を検討した背景
BigQueryに魅力を感じた1つめの理由は「同時並列実行における高いパフォーマンス」だという。IDAPではデータのロードや加工処理、ユーザーのアドホックな分析クエリ、定期実行クエリといったワークロードが同時並列実行される。BigQueryでベンチマークテストを行ったところ、同時並列実行においても十分な性能を発揮した。
もう1つの理由は、BigQueryが備える「BigQuery GIS(位置情報データ分析)」や「BigQuery ML(機械学習モデルの作成/実行)」といった豊富な機能群だ。IDAPはNTTドコモ社内の幅広い職務に就く分析者が利用するデータ分析基盤であり、こうした誰でも扱いやすい機能が提供されることで「高いユーザビリティを提供できると感じた」(林氏)という。
「BigQuery MLへの期待は大きい。IDAPのユーザー(社内分析者)は、プログラムをガリガリ書けるというよりはSQLを書くのが得意という方が多い。これまで『機械学習と言えばPython』とハードルが高かったところが、SQLで機械学習ができるようになることで、気軽に機械学習に触れてもらえる。これにより、新たな価値を生むことができるのではないかと思っている」

「BigQuery ML」の概要(Google Cloud寶野氏の説明資料より)。Pythonなどのプログラミング不要で、SQLから機械学習モデルの作成/実行ができる
他方でIDAPでは、既存のAWS Redshift環境も併存するかたちをとっている。BigQueryとRedshiftの使い分けについてはどう考えたのか。
林氏はまず、従来環境における具体的なユーザーのユースケースを調査し、状況を把握したと語る。その結果、BigQueryで実行するほうが高いパフォーマンスが発揮できるケースが見られたため、それらをBigQueryで実行している。一方で、ドコモではAWSクラウドの活用が進んでおり、データソースがAWS上にあるケースが多い。その場合はデータ転送コストがかからないRedshift側で処理している。
「現在、ユーザークエリの6~7割ほどをBigQueryで実行している。BigQueryは巨大なデータの読み取り、結合といった処理も得意だ。一方、Redshiftではデータの加工処理や、3割ほどのユーザークエリの処理を行う。こうした使い分けで、最もコストパフォーマンスが高くなるような構成をとっている」
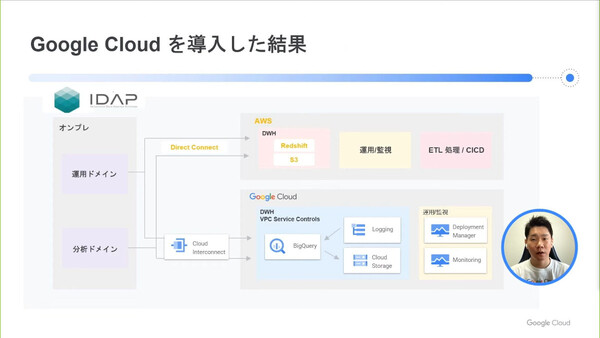
現在のIDAPの構成。オンプレミス環境、AWS環境、Google Cloud環境をつなぎ、最もコストパフォーマンスが高くなる構成をとっている
本記事はアフィリエイトプログラムによる収益を得ている場合があります



