



併用するAWS「Redshift」との使い分けは? Google Cloud「Data Cloud Summit」レポート
NTTドコモがペタバイト級分析基盤で「BigQuery」本格運用開始、背景を語る
2021年09月08日 07時00分更新

閉域環境への導入、詳細なアクセス制御でセキュリティ要件を満たす
BigQueryの採用時に、もうひとつの大きな要件となったのがセキュリティだ。
膨大な量と種類の情報を扱うIDAPでは「情報漏洩を一切許さない厳格なセキュリティレベル」(林氏)が求められる。そのため、全体を閉域環境(プライベートネットワーク環境)として構築し、運用することを基本としている。Google Cloud/BigQueryの採用にあたっても、オンプレミス、AWSの環境と閉域接続ができる必要があった。
そこでまず役立ったのが、ネットワークセキュリティを強化するVPC Service Controlsだった。同サービスでは、BigQueryやGoogle Cloud Storageといった各種サービスに「セキュリティ境界」を作成し、境界外(承認されていないネットワーク)からのアクセスをすべてブロックすることができる。これを利用して、IDAPではパブリック接続を完全に遮断している。
「2018年にVPC Service Controlsが一般提供開始となったことで、(完全な閉域環境という)セキュリティ要件が満たせることになり、導入への大きなきっかけとなった。余談だが、現在ではIngress/Egressルール(下り/上り通信のルール)もGAとなり、さらに詳細な制御ができるようになっている」
これに加えて、オンプレミス環境との閉域接続サービスである「Cloud Interconnect」、Google Cloudの各種リソースが持つAPIにプライベートIPでアクセス可能にする「Private Google Access for オンプレミスホスト」を用いて、Google Cloud環境、オンプレミス環境、AWS環境の全体をプライベートネットワーク化した。


VPC Service ControlsやCloud Interconnect、Private Google Access for オンプレミスホストといったサービスを活用してGoogle Cloudを閉域環境化。情報漏洩リスクを防いだ
またIDAPでは、機密性の高いデータも扱うことから分析者ごとの細かなデータアクセス制御が必須となっている。ただし“分析者×データセット”の組み合わせごとにアクセスの可否を設定するのは膨大かつ複雑な作業となり、実現は現実的ではない。そこで、Google CloudのIDaaSである「Cloud Identity」のグループ化機能を用いて、Big Query上のデータに対する細かなアクセス制御を実現したという。
Cloud Identityのグループ化機能では、1つのサービスアカウント(=1ユーザー)が複数のグループに所属することができる。さらに、グループを異なるグループに所属させることもできるので、サービスアカウントを階層構造で管理することが可能だ。そして、グループに対してデータセットへのアクセス権限(IAMロール)を割り当てられる。こうした仕組みを組み合わせることで、データアクセス権限の管理作業を簡素化している。
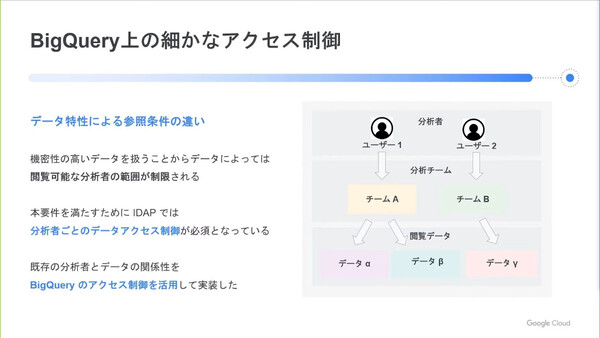
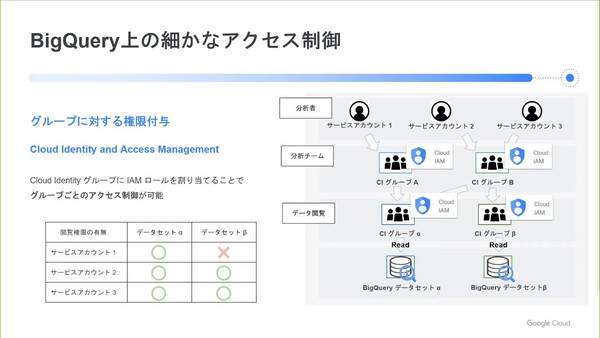
細かなアクセス制御を行うためCloud Identityのグループ化機能を使っている。各データセットへのアクセス権限を持つグループ(データ閲覧グループ)を用意し、そのグループに対して分析チームグループ単位で参加させるかたちで、多数の分析者に対するアクセス権限付与/管理を簡素化した
なお林氏は、IDAPの導入において自身が試行錯誤したポイントを“BigQuery Tips”として紹介した。Redshiftを起点としたBigQueryへのデータ連携におけるロードエラー頻発の原因を解消した「BIGNUMERIC型の活用」、機械学習チームにおける大規模データの読み取り処理を30分から10分以下に短縮した「BigQuery Storage APIで読み取り高速化」、想定よりも処理時間のかかっているクエリにおいて詳細な原因追及ができる「BQ Visualizerでクエリ分析」の3つだ。本稿では割愛するので、Data Cloud Summitのサイトから同セッションのオンデマンド配信をご覧いただきたい。
林氏のセッションまとめ
「あらゆるユーザーに、どんなスケールでも洞察を与える」BigQuery
記者説明会に出席したGoogle Cloudの寶野氏は、同社が“データクラウド”戦略で目指すところを紹介した。
現在、世界中の企業がデータアナリティクスを通じた新たなビジネス価値の創造を目指しているが、その実現に苦戦している企業がほとんどだ。データ自体はあるものの、過去に選択/導入してきたさまざまなテクノロジーが“足かせ”となって、価値を引き出せていない現状がある。
この状況に対して、Google Cloudでは統一されたエコシステムとしてデータプラットフォームを提供する。その一角を担うのが、アナリティクスプラットフォームのBigQueryだ。「あらゆるユーザーに、どんなスケールでも洞察を与えていく。これが現在のBigQueryの立ち位置だ」(寶野氏)。
寶野氏は、データがサイロ化せず組織横断的に利用できるストレージ、インデックスチューニング不要の高速処理、コンピュート/ストレージ/メモリの分離で大規模クエリにも対応できる柔軟なスケーラビリティ、クエリ開始後の動的なクエリプラン変更といったBigQueryの特徴を紹介した。
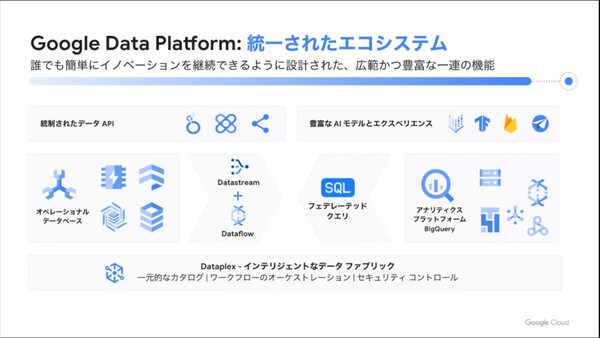
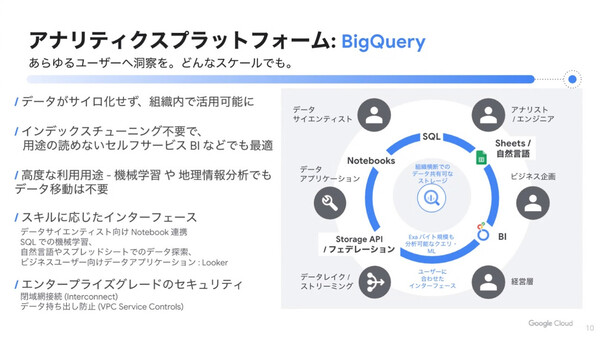
Google Cloudが提供するデータプラットフォームの全体像と、BigQueryの特徴
NTTドコモの林氏が「期待」を語っていた、BigQuery MLについても触れた。SQLを書くだけで「データアナリスト自身でもML(機械学習)モデルが作成できる」、さらに機械学習専用の環境にデータをコピーしたりする必要がないため「データのサイロ化が防げる」、そして機械学習モデルによる処理結果をSQLで参照できるため「BIツールなどからも結果を参照しやすい」とまとめた。「BigQueryを導入いただいている世界の上位顧客のうち、80%はこのBigQuery MLを使っている」(寶野氏)。
また、Big Queryによるデータサイロ解消の一環として、BigQuery Storage APIも紹介した。BigQueryのストレージにあるデータに直接、高速にアクセスできるため、これまでのDWHのようにクエリをかけてデータを取り出し、別環境にコピーするといった手間がなく、さまざまなかたちでデータを外部活用するのに便利な仕組みだとしている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



