




Sunny Coveからキャッシュ周りが変わった
Willow Cove
次はWillow Coveコアの話だ。もともと2018年のArchitecture Dayの際のスライドでは、Willow Coveはキャッシュ構成の再設計、新しいトランジスタへの最適化、セキュリティーの強化の3点が挙げられていた。このうち新しいトランジスタへの最適化は、上に示した10nm SuperFinへの対応ということでわかる。

おそらくはキャッシュだけでなくTLBも強化されているのではないかと思うが、そのあたりは今後インテルがSystem Optimization Manualに詳細を記載するまでわからない
コアの構成が上の画像であるが、Ice LakeというかSunny CoveのBackendと比較すると以下の違いがあり、多少Window Sizeなどを増強したかもしれないが、大きな変更はなさそうである。
- RSの数は4つ。ALU/FPU/AVX向けのPort 0/1/5/6、Store Data向けのPort 4/9、Load/Store Address向けのPort 2/8とPort 3/7の4つになっている。
- それぞれのポートの下にぶら下がる実行ユニットの数も同じ。
- Schedulerのウインドウサイズなどは今回明らかにされていないので比較できないが、構造そのものは大きく変わっていない
では変化があるのは? というとキャッシュ周り。そもそもIce Lakeの場合、キャッシュ構成は以下のようになっており、1次キャッシュこそ共通ながら2次と3次キャッシュが大容量化されるとともに、キャッシュ構成がNon-Inclusiveに切り替わった。
| Ice LakeとTiger Lakeの違い | ||||||
|---|---|---|---|---|---|---|
| Ice Lake | Tiger Lake | |||||
| 1次キャッシュ | 命令32KB+データ48KB | 命令32KB+データ48KB | ||||
| 2次キャッシュ | 512KB、Inclusive | 1.25MB、Non-Inclusive | ||||
| 3次キャッシュ | 2MB/core、Inclusive | 3MB/core、Non-Inclusive | ||||
Inclusive方式はレイテンシーこそ低いものの、キャッシュの利用効率が下がるという問題がある。一方Non-Inclusive方式では、キャッシュの利用効率そのものは高いものの、キャッシュミス時のデータのFillに時間が掛かるのと、複数コア間でのSnoopingの頻度も高まる関係で、レイテンシーが大きくなる。
かつて、インテルはAMDに対してプロセス面でアドバンテージがあり、それもあって大容量のキャッシュをInclusiveで搭載、対するAMDはプロセス面でのディスアドバンテージを補うべく、相対的に少ないキャッシュをExclusive構成で搭載することで見劣りしないように工夫する(ただしレイテンシーが余分にかかるので少し遅い)という戦略を取っていたが、このところAMDとインテルの立場がプロセスに関して逆転している。そこで、多少なりとも容量面での不利を補うためにこうした方策を取ったのかもしれない。
上の画像の最後に出てくるControl Flow Enforcementとは、Jump/Returnなどの制御命令を実行する際に、分岐先インジェクションなどの攻撃を受けやすいというものである。
この分岐先に対する攻撃は何種類かある(一番有名なのはSpectre V2)だが、そのSpectre V2そのものへの対応はIce Lake世代で一応完了している。ここで挙げられたのは、そうした応急対処ではなく、もう少し恒久的というか根本的に分岐命令の安全性を高めるための方策ではないかと思われる。
単にコアだけではなくSoCレベルでの改良箇所も多い。まずファブリックは、今回Dual Ring構成になったとしており、さらに新たにLP5-5400のサポートも追加されたとされている。
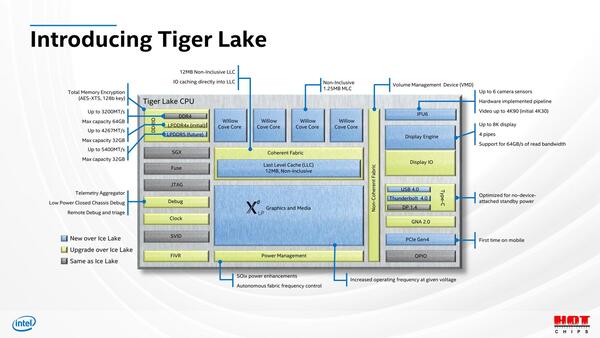
SoCといっても厳密に言えばPCH(Platform Controller Hub)は別なので、その意味ではRenoirに比べるとSoCのレベルは低い

新たにLP5-5400をサポート。“(initial)”の文字からもわかるように、LP5-5400対応の製品は今後の投入になる模様だ。そもそもLP5-5400はまだサンプル出荷も始まってない(現在は特定顧客向けの開発用の初期バージョンがわずかにリリースされているだけ)段階なので、そもそもLP5-5400に対応したコントローラーそのものが内蔵されていない可能性すらある
加えて、Non-Inclusive LLCを採用したことでRing Busのトラフィックそのものが半分になったとしており、結果として従来比で4倍の帯域を利用可能になる計算だ。I/Oキャッシングに関しては、現状詳細不明なままであるが、後述するUSB Type-C周りであるいはなにかローカルキャッシュが利用されているのかもしれない。
ちなみに、上の画像にある86GB/sはLP5-5400を使った場合の数字である。またRyzen Pro/EPYC同様に、メモリー上のデータを自動的に暗号化すると思われる、Total Memory Encryptionが新たに追加された。
またアクセラレーターであるGNA(Gaussian and Neural Accelerator)も2.0になった。GNAの話は連載525回で説明したが、CPUコアから処理をオフロード可能なアクセラレーターという扱いである。

2.0になってなにが改良されたのかは良くわからない。説明ではmWの消費電力でテラOpsの処理性能を持っており、ノイズキャンセルなどに活用できるとされていた。ちなみにこれはArchitecture Dayでのみ触れられており、Hot Chipsでは出てこないスライドだ
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























