




ダイ同士をワイヤーでつなぎ
独自のコネクターでパッケージング
ところでこのコア同士をどうつなぐか、であるがこれは2Dメッシュである。ただ、WSLは84個(12×7)のダイに分かれている。これはマスクがこの1個分として作られているので、同じマスクを84回移動しながら露光して製造するわけだが、通常はこれを切り落とすことになる。
したがって2Dメッシュも個々のダイの中は問題なく接続できるが、ダイの間は通常切り落とされることになるため、ここに配線を通せない。そこで後工程でダイの間にワイヤーを通すという荒業で対策している。
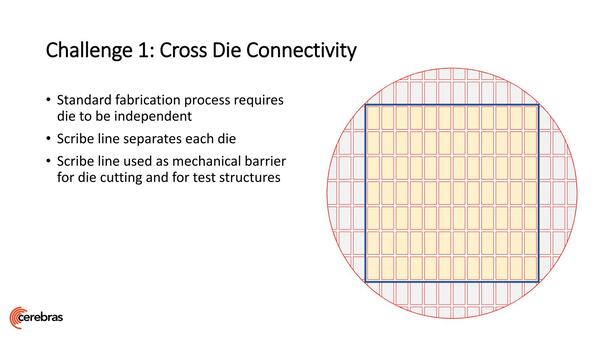
ダイとダイの間は切り落とす。この切り落としの領域(要するに切り代)のことをScribe lineと呼ぶ。ここは露光のはざまになるので、トランジスタも配線も実装できない
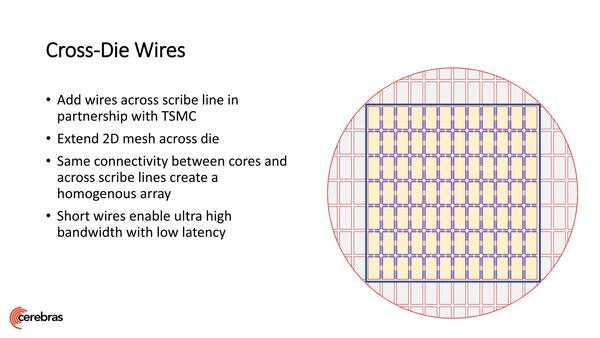
ダイの間にワイヤーを通すことでコア同士をつないでいる。ここをどうやって作ったかに関して今のところ詳細な説明はない(そのうちどこかでTSMCが発表しそうな気もするが)
また当然Defect(欠陥)も問題になる。これに関しては、冗長コアと冗長配線を用意、欠陥箇所を迂回する形で利用できるとした。

TSMCの16FF+はかなり熟成されたプロセスなので、欠陥はそう多くはないとは思うが、だからといって欠陥0にはならない
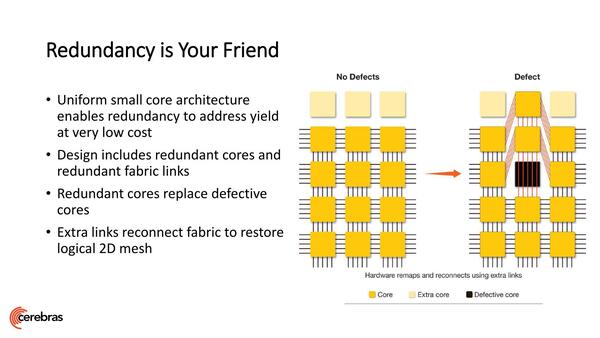
上一列が冗長コアである。同様にコア間のリンクに関しても冗長リンクが用意されるとしている
パッケージも独特である。まずFlip Chipの形でプリント基板に装着するわけだが、その際に中間的な熱膨張率を持ち、両者の差を吸収できる独自のコネクターを開発したそうだ。

Flip Chipの形でプリント基板に装着する。そもそもシリコンとプリント基板では熱膨張率が違う上、これだけダイが大きいと相当寸法に狂いが出そうである
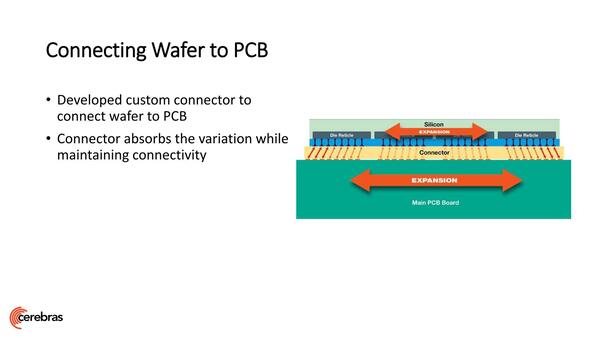
独自のコネクター。もう少しダイサイズが小さければCoWoS(高密度パッケージ技術)などでも良かったのだろうが、これだけ大きいとCoWoSをそのまま使うわけには行かないだろう
ちなみにソフトウェア的には当然既存のフレームワークを変換して利用する形になる。これだけコアがあると小規模なネットワークであればまるごと全部をオンダイ(オンウェハーというべきか)に載せることも可能とされる。
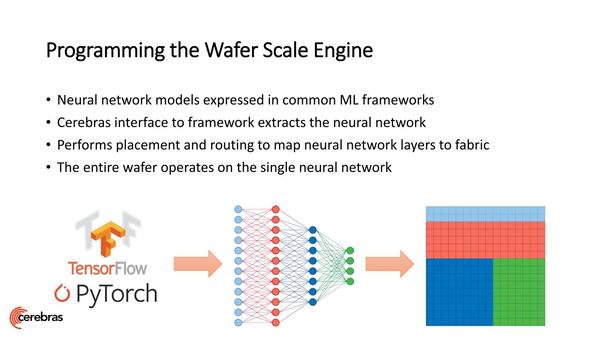
ソフトウェアは既存のフレームワークを変換して利用する。逆にここに載せきれない場合は、ウエイトを入れ替えながら動かすような形になるので、若干効率は落ちるはずだ。今のところ、どんなネットワークならまるごと載るかといった情報は出てきていない
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ














の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



















