




ARMプロセッサーの話を取り上げるのはすいぶん久しぶりである。前回は連載179回で、7年半ほど前になる。ちなみにこの時「次世代コア」と言って紹介したCortex-A57/A53は、すでに「前世代コア」になってしまった。
今回取り上げた理由は、富岳とAppleである。日本は富岳で久しぶりにTOP500で首位奪回したとともに、TOP500では初めてARMベースで首位に立った。

そしてAppleは6月23日のWWDCで、次期MacにApple自社製のARMベースプロセッサーを採用することを明らかにした。そんなわけで、今回と次回はこの2つのARMベースプロセッサーの話を説明しよう。今回は富岳である。
富岳に採用されたプロセッサーA64FXは
スーパースカラー/アウト・オブ・オーダー構成
その富岳に採用されたA64FXは、Appleとは真逆の方向の設計思想である。極端なまでのデータ集約型な設計である。強いて言うなら、昔AMDのCTOを務めていたPhil Hester氏がBulldozerの設計に向けて提唱した“Throughput Computing”というのが一番近いかもしれない。
まずCPUのパイプラインから説明したい。下の画像がそのA64FXのブロック図である。命令デコードは4命令/サイクルで、7命令同時発行という構成になっている。
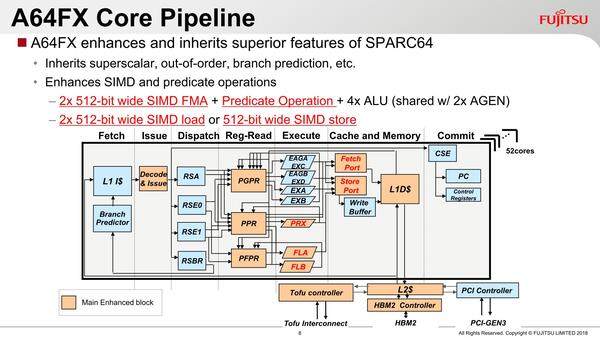
この図でオレンジ色の部分は「Main Enhanced block」と説明されている。なにからEnhance(強化)したのか? という元が下の画像の、2014年に発表されたSPARC64 XIfxである。
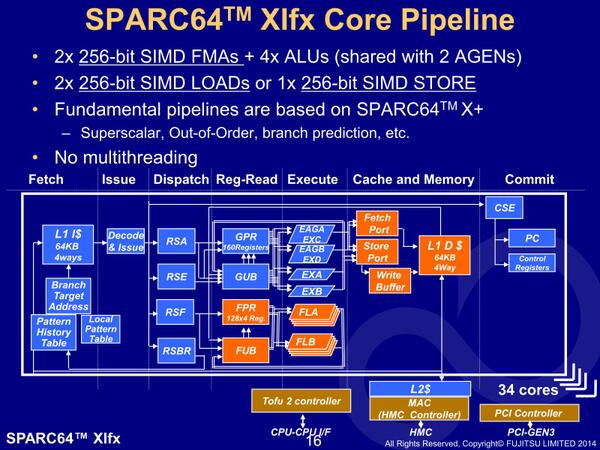
これは京コンピューターに利用されたSPARC64 VIIIfxから2世代ほど進化したもの。ちなみにSPARC64の場合、汎用のSPARC64とHPC向けのSPARC64 fxがあり、HPC向けの場合はSPARC64 IXfx(40nmプロセスに移行、コア数増加)→SPARC64 XIfxになっている(汎用向けは、すでにSPARC64 XIIが2017年に出荷されている)
画像の出典は、2014年のHotChipsにおける講演。
そもそも最近のプロセッサーの場合、デコード段で内部命令(μOp)に変換して処理をしているので、デコード段を含むフロントエンドをすげかえれば、異なる命令セットでもバックエンド側はほぼ同一の構成で行けるようになっている。
古いところではAMDのAm29050とK5、最近ではAMDがZenと並行して開発していたK12がこれにあたる。実際これは富士通も公言している話であり、開発リソースを分散させずに競争力のあるコアを複数開発するには良い方法だと思う。
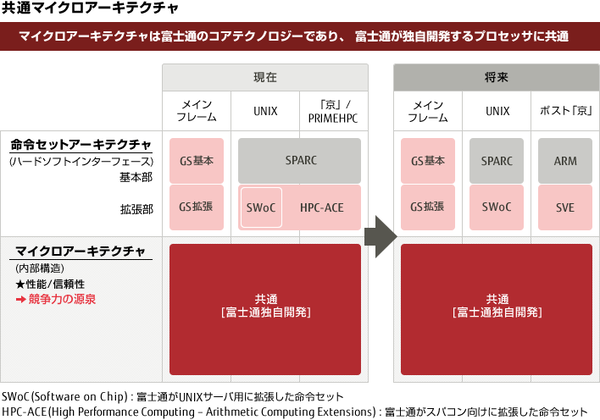
富士通の場合、旧IBM互換のメインフレーム(GSシリーズ)と、SPARCベースのUNIXサーバ、それと今回ARMベースのプロセッサーを開発することになったが、全部バックエンドは基本的に共通になっている
画像の出典は、富士通ジャーナルの“ポスト「京」プロセッサーの命令セットを紹介”
話を戻すと4命令/サイクルでのデコードに対し、実行部は以下のように役割が異なっている。
| 実行用オペランド | 概要 |
|---|---|
| EXA/EXB/EXC/EXD | 整数演算ユニット。厳密に言えば EXA:算術/論理演算、シフト、乗算 EXB:算術/論理演算、シフト、除算 EXC/EXD:算術/論理演算 と役割が微妙に異なっている。 |
| EAGA/EAGB | アドレス計算 |
| PRX | Predication操作(後述) |
| FLA/FLB:FPU/FMA | これも厳密には FLA:整数/論理演算、シフト、浮動小数点演算、FMA、除算、暗号化処理、ベクタアドレス計算 FLB:整数/論理演算、シフト、浮動小数点演算、FMA と役割が異なっている。 |
この9つ(ただしEXC/EXDとEAGA/EAGBは共通の命令ポートを利用するので排他利用となる)の実行ユニットが独立して動く7命令のアウト・オブ・オーダー構成である。
さて、この中で要となるのはやはりSVEである。SVE、正式名称はScalable Vector Lengthというベクトル拡張命令、要するにSIMDのことであるが、おもしろいのは最小128bit~最大2048bit幅まで、チップ設計者が128bit単位でSIMDの幅を自由に選べるようになっている。
しかも命令セットが幅を規定していないため、例えば256bitのSVEのマシンと512bitのSVEのマシンがあったとすると、プログラムは両方で共通になるという、やや独特なフォーマットになっている。
A64FXの場合には512bitを選択したわけだが、SIMDの幅を広げるほど1サイクルで処理できる計算量が増える一方で、その幅のデータを1サイクルで処理しないといけないから入出力、つまりAGUやLoad/Storeユニットには負担が掛かるし、SVEのレジスターのサイズも膨れ上がるので、どこかでバランスを取る必要がある。
富岳の実質的なチーフアーキテクトを務めた東工大の松岡教授としては、512bitほどがちょうど手頃だったという判断と思われる。
もっとも実際にはそれこそSkylake-SPなどと同じように512bit幅のSVEが2つあるわけで、実質的には1024bit幅になるが、1024bitのSIMD×1よりも512bitのSIMD×2の方がプログラミングと実装が容易だったと思われる。
この連載の記事
-
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 - この連載の一覧へ

















の1台が今ならオトク!")




























")













