




10倍どころか100倍近い
性能/消費電力比を実現
さてこのGoogle TPUの性能だが、論文によれば下表の通りである。18コアのtXeon E5-2699 v3の2ソケット構成単体と、そのサーバーに、Tesla K80を1枚追加したもの、およびDual Xeon E5-2699 v3にGoogle TPUを組み合わせたものの3種類での性能比較であるが、INT 8における演算性能はXeonが合計で2.6TOP/秒なのに対しGoogle TPUは92TOP/秒を叩き出している。
Measured、つまり実測の消費電力で比較すると以下のとおりだ。
| 消費電力の比較表 | ||||||
|---|---|---|---|---|---|---|
| プロセッサー | ダイ単体 | システム全体 | ||||
| Xeon(INT 8) | 17.931GOP/s/W | 5.714GOP/s/W | ||||
| Xeon(FP) | 8.965GOP/s/W | 2.857GOP/s/W | ||||
| Google TPU | 28.571GOP/s/W | 2.825GOP/s/W | ||||
| Tesla K80 | 2300GOP/s/W | 239.583GOP/s/W | ||||
基調講演における10倍どころか、100倍近い性能/消費電力比を実現できているわけだ。こうなると基調講演で語った10倍の差はいったいなにと比較したのか? という議論になるわけだが、これは後述する。
ちなみにこの論文では、ベンチマークとしてMLP(多層パーセプトロン)、LSTM(Long Short-Term Memory:長期間の時系列データを扱えるネットワーク)、CNNの3種類について、それぞれ2つづつトータル6つのネットワークを利用している。
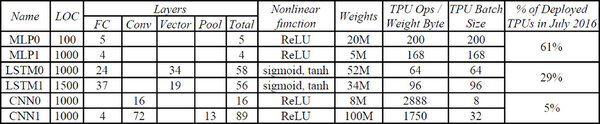
ネットワークの層数は4層~89層、活性化関数もさまざまで、Weight(係数)の量も5万~100万個と大きく異なる
この6種類のネットワークの傾向をまとめたのが下の画像である。TPUは1万ps/Bytesあたりまでほぼ性能が上昇して86TOP/秒あたりでやっと頭打ちになるのに対し、Haswellは13Ops/Bytesあたり、K80は8Ops/Bytesあたりですでに性能が頭打ちになっており、これ以上性能が上がらないことが示されている。
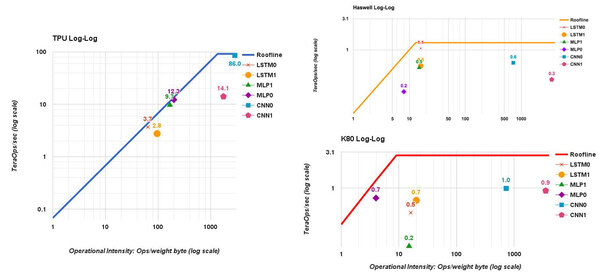
ネットワークの傾向。本来は3つの異なるグラフであるが、一つにまとめさせていただいた
水平部は演算性能のリミット、斜線部はメモリー帯域のリミットであり、要するにHaswellやK80は演算性能の前にメモリー帯域がリミットになってしまっている。
上で書いた性能の話だが、実効性能に近い数字が2007年8月に開催されたHotChips 29で公開された。こちらはK80およびGoogle TPUのCPUに対する性能比をそれぞれ算出したもので、相乗平均の結果が右端となる。
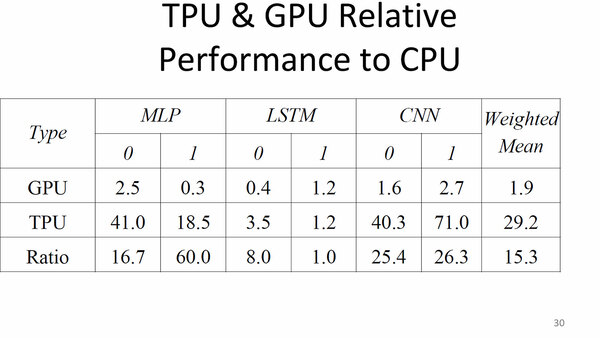
HotChips 29で公開された、実効性能に近い数字。これは6種類のネットワークのそれぞれの処理性能を、CPU(Xeon)で行なった場合と比較しての数値となる
出典は“Evaluation of the Tensor Processing Unit: A Deep Neural Network Accelerator for the Datacenter”
Xeon 2Pと比較して29.2倍ほど、K80と比較して15.3倍ほどの性能となっている。絶対値という意味では、おおむね23TOP/秒あたりが平均的な性能ということになる。
第2世代となるGoogle TPU v2が登場
カード間で2次元Meshの構築が可能に
初代Google TPUの詳細が発表される「前」の2017年5月に開催されたGoogle I/Oで、第2世代となるGoogle TPU v2(Cloud TPU)が発表される。

Google TPU v2。1年前と異なり、2017年は基調講演の比較的早い段階で公開された
大きな違いは、今度は4つのGPUで1枚のカードを構成するだけでなく、カード間で2次元Meshを構築できることで、大規模なデータセンター(学習用クラウド)をTPUだけで実現できることになる。
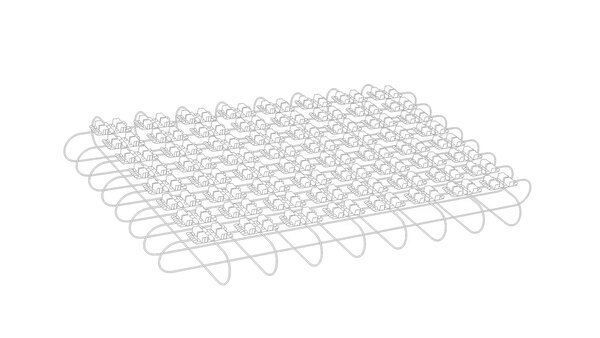
それぞれのTPUボードに4本のインターコネクトが搭載されており、これで2D Meshを構築できる。構成は8×8。リンク速度は1本あたり双方向で500Gbpsだそうだ

実際に稼働中のCloud TPUのシステム。一般のデータセンターと比較して5倍の帯域を10分の1のコストで実現できたと説明されている。おそらく中央の2つのラックがGoogle TPU v2のPod、左右のラックは制御用のホストと思われる
このGoogle TPU v2の構成であるが、2019年のHotChipsでGoogle TPU v3と併せて解説されたほか、David Patterson教授による“Domain Specific Architectures for Deep Neural Networks: Three Generations of Tensor Processing Units (TPUs)”という講義の中で詳細が説明されており、しかもそれがYouTubeで公開されている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ











&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")




















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












