



ロードマップでわかる!当世プロセッサー事情 第563回
Ampere採用GPU「A100」発表、Titan Aが発売される可能性も NVIDIA GPUロードマップ
2020年05月18日 12時00分更新

AIプロセッサーの昨今はちょっとだけお休みいただいて、5月14日に行なわれたGTC 2020の基調講演の内容を解説したい。言うまでもなくAmpereアーキテクチャーである。

AmpereアーキテクチャーのGPU「A100」
今年のGTC(GPU Technology Conference)はオンラインでの開催となり、Jensen Huang CEOによる基調講演は8分割されてYouTubeにアップロードされている。いわゆるライブではなく、あらかじめ撮影したものを一挙公開の形で筆者も最初戸惑った。
ちなみに基調講演の模様はYouTubeのNVIDIAチャネルで視聴可能なほか、GTCのサイトでも参照できる。
さてその基調講演ではさまざまな話題が取り上げられたが、今回はAmpereを中心に説明しよう。つまり連載535回で予想した内容の答え合わせである。
さてそのAmpereであるが、予想通りデータセンター向けの製品であり、コンシューマー市場に下ろすことはまったく考えていない、ある意味振り切ったものだった。まずはスペックから見ていこう。
Voltaに酷似するがGPCの数などが違う
NVIDIA A100 Tensor Core GPU
Ampereアーキテクチャーを搭載するNVIDIA A100 Tensor Core GPUは、2種類のパッケージで提供される。1つ目が新しいSXM4モジュールに搭載されるものだ。

SXM4モジュールに搭載されるNVIDIA A100 Tensor Core GPU。A100を囲むように配置されている4つの金色のモジュールは後述する
実際にはこのA100の上には巨大なヒートシンクが装着されて収まる形になるので、これを直接目にすることはないと思う。

DGX A100を紹介するムービーより。この後ヒートパイプにフィンが付き、次いでカバーがかぶさる
さてそのA100であるが、まず大まかにスペックを並べると以下の通りとなる。
- ダイサイズ 826mm2。TSMCのN7プロセスで製造。トランジスタ数は542億個
- メモリー:1.6Gbps HBM2×6(実際は×5)。8GBスタックを利用し、最大容量48GB(実際は40GB)
- 内部は8GPC(GPU processing cluster)構成(ただし実際は7GPC)。1つのGPCには7~8個のTPC(Texrure Processing Cluster)を搭載し、TPCあたり2つのSM(Shader Module)を搭載する。したがってシステム全体では128SM構成で、このうち108SMが利用可能。
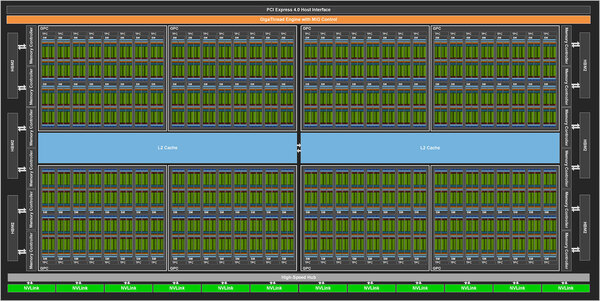
GPCの数やメモリーコントローラーの数は違うが、このレベルで言えばVoltaと非常に似たレイアウトである
- SMの内部構造は、一見するとVoltaのそれと大きな違いはない。ただしTensor Coreの数は、VoltaはSMあたり8つだったのが、Ampereでは4つに減っている。SMあたりのINT32/FP32/FP64コアの数はいずれも64で、これはVoltaと変わりがない。
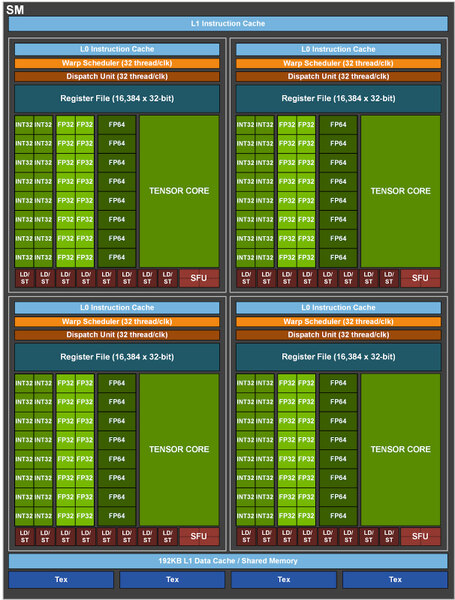
SMの内部構造はVoltaと大きな違いはない。もっともTensor Coreそのものの性能は大幅に上がっているので、単純に数で比較してもあまり意味はない
- コアの動作周波数は最大(Boost)で1410MHzと、VoltaベースのGV100(1530MHz)やPascalベースのGP100(1480MHz)よりもやや控えめ
- ただし性能は圧倒しており、整数/浮動小数点演算性能では、以下の数字が示されている。
| 整数/浮動小数点演算性能 | ||||||
|---|---|---|---|---|---|---|
| GP100 | GV100 | GA100 | ||||
| INT32(TOPS) | 15.7 | 19.5 | ||||
| FP16(TFlops) | 21.2 | 31.4 | 78.0 | |||
| BP16(TFlops) | N/A | N/A | 39.0 | |||
| FP32(TFlops) | 10.6 | 15.7 | 19.5 | |||
| FP64(TFlops) | 5.3 | 7.8 | 9.7 | |||
| NVIDIA A100 Tensor Core GPUの演算性能 | ||||||
|---|---|---|---|---|---|---|
| FP16 | 312/624TFlops | |||||
| FP16 w/FP32 | 312/624TFlops | |||||
| BF16 w/FP32 | 312/624TFlops | |||||
| TF32 | 156/312TFlops | |||||
| FP16 | 19.5TFlops | |||||
| INT8 | 624/1248TOPS | |||||
| INT4 | 128/2496TOPS | |||||
- モジュール全体の消費電力(TDP)は400W
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ


















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





































