



“Kubernetes+BlueData+MapR”=AI/機械学習やビッグデータ分析に強いコンテナ基盤と位置づけ
「HPE Container Platform」発表、機械学習/統合データ基盤としてアピール
2020年05月15日 07時00分更新

日本ヒューレット・パッカード(HPE)は2020年5月14日、コンテナプラットフォーム製品「HPE Container Platform」の国内提供開始を発表した。オープンソースソフトウェア(OSS)版のKubernetesをベースに、HPEが買収したBlueData SoftwareやMapR Technologiesのソフトウェア技術を組み合わせた構成で、特に「『AI/機械学習』や『ビッグデータ分析』領域に強みを持つ」とアピールしている。
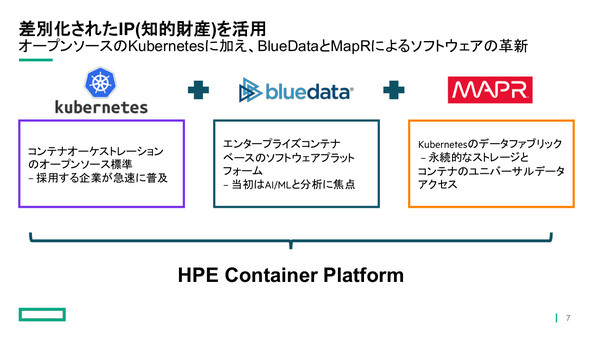
「HPE Container Platform」は、OSS版KubernetesとBluDataのコントロールプレーン、MapRのデータファブリックを統合したコンテナ基盤製品

日本ヒューレット・パッカード ハイブリッドIT事業統括 プロダクトアーキテクト統括本部 製品技術本部 ストレージソリューション部 部長代理の野瀬哲哉氏

日本ヒューレット・パッカード ハイブリッドIT事業統括 製品統括本部 製品部 カテゴリーマネージャーの加藤茂樹氏
「AI/機械学習」や「ビッグデータ分析」に強みを持つ理由
HPE Container Platformは、OSS版Kubernetesをベースに構成されたコンテナプラットフォーム製品だ。Kubernetesのほかに、AI/機械学習やビッグデータ分析のクラスタ展開をセルフサービス型“as-a-Service”モデルで提供するBlueDataのコントロールプレーン(BlueData EPIC)や、MapRのビッグデータ処理向け分散ファイルシステム(MapR FS)を用いた永続データストレージを統合しているのが特徴となる。

BlueData EPICが提供するセルフサービスポータル。機械学習/ディープラーニングやデータ分析のOSSクラスタを簡単に展開できる(画像はBlueDataのWebサイトより)
同プラットフォームは、オンプレミスのベアメタルサーバーから仮想化環境、パブリッククラウド、エッジ環境まで、あらゆるインフラに対し柔軟に配備できる。エアギャップ(インターネット隔離)機能も備えており、インターネット非接続環境でも構築や運用が可能。
またデータベースやデータ分析、AI/機械学習フレームワーク、CI/CDパイプラインなどの主要OSSは、あらかじめアプリケーションストアに用意された事前検証済みコンテナイメージを用いて容易に展開できるようになっている。もちろん、Kubernetes環境向けに自社で開発したアプリケーションコンテナの展開も可能だ。

HPE Container Platformのアーキテクチャ概要
なおHPEでは、特にAI/機械学習やビッグデータ分析といった領域においては、処理の高速性や効率性の観点からベアメタル環境での展開に優位性があり、顧客ニーズも高いと考えており、「HPE Apollo」や「HPE Synergy」「HPE Edgeline」といったHPEサーバー製品のユースケースに応じたリファレンス構成も提供する。ちなみに最小構成は5ノードからで、用途にもよるが一般的な構成規模は「おおむね30ノードから」(HPE)と見ているという。
もうひとつ、上位ライセンスとして、HPE Container Platform上に機械学習のライフサイクル管理にかかるアプリケーションコンテナ群を追加した「HPE ML Ops」も提供する。学習モデルの開発/トレーニング/デプロイ/モニタリングという一連のオペレーションを包括的に支援する。
なおHPE Container Platform/ML Opsのライセンスは、1物理CPUコアまたは2仮想CPUコア単位での課金としている。顧客ニーズに応じて、構成するハードウェアやクラウド、またプロフェッショナルサービスやトレーニングなど複雑な組み合わせとなるため、価格は要問い合わせとしている。
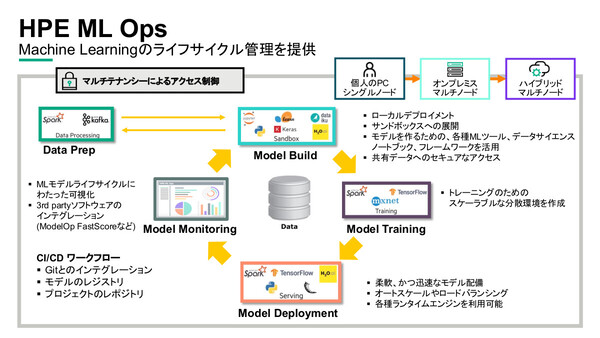
「HPE ML Ops」は、Container Platform上で機械学習のライフサイクル管理ツール群を提供する
既存のHadoop環境からデータを移行することなく「併用」も可能
HPE ハイブリッドIT事業統括 プロダクトアーキテクト統括本部 製品技術本部 ストレージソリューション部 部長代理の野瀬哲哉氏は、HPE Container Platformの特徴を「データ処理特性に応じた柔軟な配備」「セキュリティに配慮したデータ分析基盤の統合」「強固なデータファブリック」の3つだとまとめた。
特に3点目の「強固なデータファブリック」については、買収したBlueDataとMapRのテクノロジーにより実現した、HPE独自の“強み”だと語る。
「もともとBlueDataでは、I/O高速化や分散処理アプリのコンテナ実装ノウハウですぐれたものを持っていた。ここにMapRが持つ、柔軟性が高く無限にスケールできるデータファブリック機能を組み合わせることで、ステートレスアプリだけでなくステートフルアプリも用意かつ高速に配備することができる」(野瀬氏)
もうひとつの注目点として、野瀬氏は、外部データレイクを透過的に利用できるリモートストレージ機能を備えていることを紹介した。既存のHDFS(Hadoop)やNFSのデータストアに蓄積されている大量のデータを、このプラットフォーム上に移行することなく利用できる。

「強固なデータファブリック」を備えたコンテナプラットフォームであることを強調した
また、HPE ハイブリッドIT事業統括 製品統括本部 製品部 カテゴリーマネージャーの加藤茂樹氏は、同製品が主なターゲットとするユースケースとして「既存Hadoop環境の置き換え/統合」「複数クラウドからの移植/統合」「全社共通データ基盤」の3つを挙げた。
「1つめは『置き換え/統合』と書いてあるが、データ分析基盤として導入されているHadoop環境からデータを動かすことなく『併用』することもできるのが強み。また、すでに複数のデータ基盤を持っている企業も増えているが、それらを統合することでコストを抑えることができる。最後に、これからデータ活用に取り組む顧客については、ぜひ全社共通データ基盤として導入いただきたい」(加藤氏)
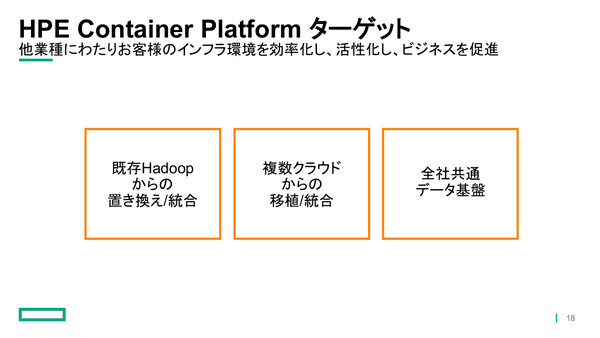
HPE Container Platformの主なターゲット。すでにビッグデータ活用に取り組んでいる企業、これから取り組む企業の両方にアピールしていく
本記事はアフィリエイトプログラムによる収益を得ている場合があります



