



今年もビルダーを魅了!AWS re:Invent 2019レポート 第3回
「AQUA for Redshift」などデータレイク/アナリティクス領域でも新発表が続々
Redshiftは他社の3倍、そして10倍高速に―AWSジャシーCEO基調講演
2019年12月16日 07時00分更新

アナリティクス:Redshift専用ストレージにカスタムチップを搭載し高速化へ
さらにジャシー氏は、来年(2020年)中旬の一般提供開始を予定している「AQUA(Advanced Query Accelerator) for Amazon Redshift」も発表した(現在はプレビューリリース)。すでにRA3において他社クラウドDWH比で「3倍」のクエリ速度を実現したが、AQUAの投入によってさらに「最大10倍」にまで引き離すと豪語する。
AQUAとはどんなものか。Redshiftのサイトでは「ハードウェアにより高速化された新しい分散型キャッシュ」と説明されている。また基調講演での発表スライドでも、CPUとは独立した「Custom Analytics Processors」のボードが描かれている。ただしこれだけではよくわからない。


「AQUA(Advanced Query Accelerator) for Amazon Redshift」を発表
ジャシー氏はAQUA開発の背景について、まず2012年以降のコンピュートとストレージそれぞれのスループット向上スピードから話を始めた。その間、コンピュートのスループット(CPUとDRAM間のスループット)は2倍にしかなっていないが、ストレージのスループットは12倍も高速化している。「かつてはストレージがボトルネックだったが、現在はコンピュートのほうがボトルネックになっている」(ジャシー氏)。
そこでコンピュートノードをクラスタ化し、処理を並列化させるアイデアが生まれる。この考え方は妥当だが、クエリパフォーマンス向上を求めてコンピュートクラスタをさらにスケールアウトさせていくと、今度はコンピュートクラスタとストレージとの間でデータを転送するネットワークが飽和し、やがてパフォーマンスは頭打ちになる。
大規模なDWH環境におけるこの課題を解決するために、従来のアーキテクチャを根本的に見直し、コンピュートクラスタとストレージの間にRedshiftの処理を最適化する新たなレイヤーを設ける。これがAQUA(AQUAレイヤー)だ。
AQUAではまず、コンピュート処理の一部をAQUAレイヤーにオフロードする。具体的には、ストレージノード内にAWS独自設計のチップやFPGA(前述のCustom Analytics Processorsボード)を追加し、データ暗号化や圧縮、さらにフィルタリング、アグリゲーションといったクエリ処理の一部もここで実行する。コンピュートクラスタに転送されるのは、AQUAで“下処理”済みのデータだ。
さらに、AQUAノードはスケールアウトアーキテクチャを採用しており、大規模なデータを処理する場合には、自動的にスケールして並列処理を行う仕組みだ。そしてAQUAはキャッシュなので、処理対象のソースデータそのものはS3ストレージから移動させない。つまり従来のように、コンピュートクラスタにすべてのデータを取り込む(ロードする)処理を行わない。
こうした最適化を行うことで、Redshiftにおいてコンピュートノードやネットワークの負荷を軽減し、従来のボトルネックを解消してより高速かつ大規模なDWH処理を実現可能にするのが、AQUAの狙いである。
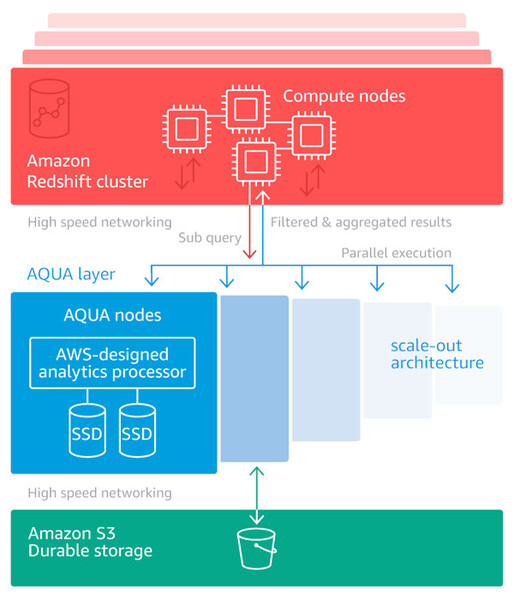
AQUAのアーキテクチャ図(公式サイトより)。コンピュートノードとストレージの間に、スケールアウトするAQUAレイヤーを設ける。このレイヤーにデータ処理とクエリ処理の一部をオフロード、並列処理させることで高速化を実現する
もうひとつ重要なことは、AQUAがRedshiftの中で透過的に処理を行う点だろう。したがってAQUAを利用する場合でも、ユーザーは従来とまったく同じ手法でRedshiftを利用できるという。
「一般には『新しいものが輝くのは最初だけ』と言われるが、われわれはRedshiftもS3もずっと進化させ続けている」(ジャシー氏)
* * *
同基調講演ではこのほか、機械学習をユーザーフレンドリーなものにする「Amazon SageMaker」においても大量の新発表が行われた。引き続き稿をあらためてお伝えする。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第5回
クラウド
ゼンリンDC、仮想サーバー1800台の「VMware Cloud on AWS」移行は順調 -
第4回
クラウド
「平均的な開発者にも機械学習の力を」―AWSジャシーCEO基調講演 -
第2回
クラウド
AWSのジャシーCEO基調講演、大量の新発表とその狙いを読む -
第1回
クラウド
「AWS DeepComposer」発表、メロディに合わせAIが自動作曲 -
クラウド
今年もビルダーを魅了!AWS re:Invent 2019レポート - この連載の一覧へ



