




Tremontの内部構造は
従来のAtomとはまるで別物
さて本題。このTremontであるが、今年10月に開催されたLinley Fall Processor Conference 2019において、インテルは“Introducing Intel Tremont Microarchitecture”と題して内部構造を説明したので、この内容を解説しよう。
まず基本的なアーキテクチャーであるが、まるで従来と別物に進化している。おさらいの意味で振り返ると、Atomのアーキテクチャーは、下表のように進化してきた(ここでissueはALUのみで、FPUは勘定に入れていない)。
| Atomのアーキテクチャー推移 | ||||||
|---|---|---|---|---|---|---|
| アーキテクチャー | 命令同時デコード数 | 命令発行数 | 命令の実行順 | |||
| Bonnell(45nm) | 2-way Decode | 2-issue | In-Order | |||
| Saltwell(32nm) | 2-way Decode | 2-issue | In-Order | |||
| Silvermont(22nm) | 2-way Decode | 3-issue | Out-of-Order | |||
| Airmont(14nm) | 2-way Decode | 3-issue | Out-of-Order | |||
| Goldmont(14nm) | 3-way Decode | 4-issue | Out-of-Order | |||
そもそも最初のBonnellは1 x86命令/サイクルの構成で、2-issueというのはALUとAGUが1つづつのシンプルな構成である。
これはロードをともなうALU命令を1サイクルで処理できるように、という話であって、IPCは1命令/サイクルが目標。そのままでは性能が低すぎるので2GHz動作にすることで、その前に利用されていたBanias/Dothanと同等以上の性能を確保するというアプローチだったが、性能の低さは否めなかった。
これがSilvermontでOut-of-Orderを実装、限定的に2 x86命令/サイクルの処理性能を目指し、Airmont/Goldmontでこれを細かく改良した形だ。
最新のGoldmont/Goldmont+ではデコーダーが3命令/サイクルに拡充されたものの、実行ユニットの数はそれほど増えていない(Goldmont+では分岐処理用にJEUというユニットが追加されたが、ALUそのものは2つのまま)ので、おおむね2 x86命令/サイクルという性能そのものは変わらない。
以上を念頭に置いてTremontの構成を見ると、まるで別物である。

Tremontの構成。Decodeは後述するとして、Execution Portが10ポートで、うち3ポートがFPUなので、整数演算は7ポートとなる。ほぼGoldmontから倍増している
まずFront End。従来とまったく異なる、3-way Decoder×2という、おそろしく強力な構成である。
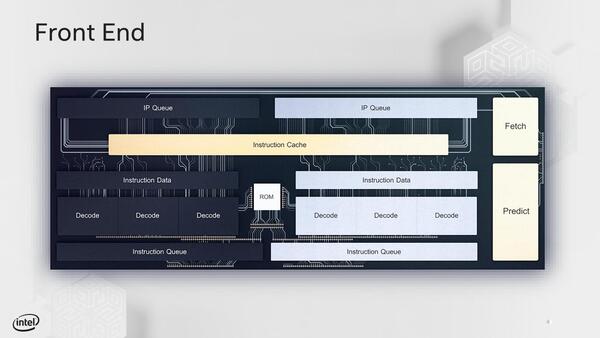
命令キャッシュそのものはUnifiedだが、これを見る限り3ポート(L2→InstCache、InstCache→Decode #1、InstCache→Decode #2)構成のようだ
さらに言えば、IP Queue(これはx86ベースの命令キュー)とInstruction Queue(これはMicroOpベースの命令キュー)も2組づつ用意されている。
これは要するにハイパースレッディングを前提に、同時に2つのスレッドのデコードを行なえるシステムを実装したということだ。その2つのスレッドを最大で3命令/サイクルで処理できるというわけだ。
ちなみに、気になるのは“Single Cluster Mode”なるモードの搭載で、言葉通りに読めば、ハイパースレッディングを無効にして、最大で6命令/サイクルのデコードが可能なモードもあるように見える。

2つのスレッドを最大で3命令/サイクルで処理できる。最大で6命令/サイクルのデコードが可能なモードもあるように見えるこれが、例えばBIOSでパッと切り替えられるような実装になっているかどうかは謎
“on product targets”というのは、現在のAtomは単にローエンドのモバイル製品(や一部NUCなどの製品)のみならず、ネットワーク機器や組み込み機器などにも使われているからだ。
こうした用途の中にはマルチスレッド性能が不要なのでシングルスレッド性能を上げてほしい、というものも存在するので、こうした特定用途向けにSingle Cluster Modeが利用可能、という話であろう。
当然これだけ強力なデコーダーをちゃんと動かすためには、分岐予測やフェッチのメカニズムも相応に強化する必要がある。

2つのスレッドは別々の動きをするので、プリフェッチも当然Out-of-Orderで動くようにしないと間に合わなくなる、というのは理解できる
とはいえ、こうなってくるともはやSmall Coreとは言い難いレベルな感じもしなくもない。ただ“Core class branch prediction”というのは現在、つまりSkylakeベースとなるCoffeeLakeやCometLake、あるいはSunnyCoveなどのCoreではなく、もう少し昔(SandyBridgeあたり?)の構成に近い、という意味かと思われる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































