




第2世代EPYCでは
レイテンシー削減を実現
話をI/Oチップレット周りに戻すと、この結果としてNUMAのドメインが従来の8つから今回は大きく2つになった形である。

右のRome側で、果たして1つのNUMAドメインの中をさらに細分化できるのか? はうっかり確認し忘れた。いずれ機会があれば確認したい
NUMAのドメインが減り、かつ帯域向上とレイテンシー削減が施された結果として、レイテンシーそのものも確実に減っているとする。
余談であるが、Ryzen 3000シリーズでもこのインフィニティー・ファブリックのレイテンシー削減は非常に効果がある。筆者の検証結果では、CCX間を跨いでの通信に要する時間が、Ryzen 7 2700X(DDR4-2666)では118ナノ秒前後だったのが、Ryzen 9 3900X(DDR4-2666)では86ナノ秒前後、Ryzen 9 3900X(DDR4-3200)では76ns前後に短縮されている。
Ryzen 7 2700Xの場合は、同じダイの中にある2つのCCX間を、やはり同じダイ上にあるデータ・ファブリック経由で接続、Ryzen 9 3900Xの場合は異なるダイに跨ったCCX間を別のダイ上にあるデータ・ファブリック経由で接続なので、普通に考えればRyzen 7 2700Xの方がレイテンシーが少なくなりそうなものだが、第2世代のインフィニティー・ファブリックでは帯域強化とレイテンシー削減が本当に実現できた模様で、このあたりもRyzen 3000シリーズの高速化に一役買っている。
第2世代EPYCでもこの効用が発揮されているようで、第2世代EPYCでは実効でも200GB/秒を超える帯域でSocket間の通信が可能としている。

これはインフィニティー・ファブリックの速度(Raw Link BW)と、その際の実効帯域(Data BW)を示したもの。4リンクが前提の構成である
なおこの性能が得られるのは、当たり前であるが第2世代EPYC向けのRomeプラットフォームを利用した場合で、第1世代EPYC向けのNaplesプラットフォームを利用した場合の速度は10.7GT/秒に抑えられる。
このあたりは、プロセッサーだけをアップグレードするか、それともプラットフォーム(=マザーボード)ごと入れ替えるか、という話になるわけだ。プレットフォームごと入れ替えるとそれなりに費用は高くつくが、その分性能が大きく改善するというわけだ。
PCI Expressの帯域が倍増
続いてI/O回り。第2世代EPYCでは128レーン(8x16)のPCI Express Gen4レーンが1つのSocketから出せる。初代EPYCでもやはり8x16レーンのPCI Expressを引っ張りだせたので変わらないと言えば変わらないのだが、帯域は倍増した。
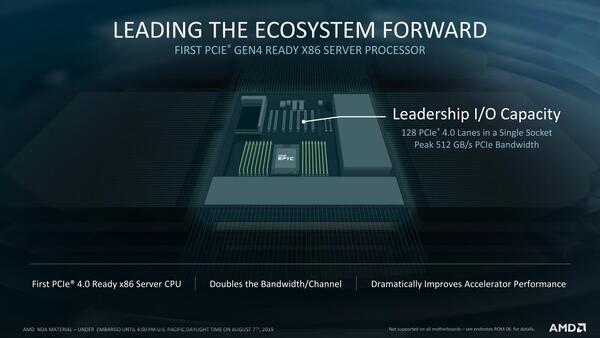
実装の問題はあるにしても、PCI Express Switchを挟めば、従来のPCI Express Gen3相当なら256レーン(16x16)を利用できる計算になる。それこそPCI Express Gen3のアクセラレーターを大量につなぎたい、というケースでは非常に効果的だろう
そのPCI Expressだが、いろいろと機能強化がなされている。帯域以外にもP2Pサポート(CPUを介さずに、たとえばPCI Expressのアクセラレーター同士で通信する技法)が公式にサポートされたほか、1つのPCI Express x16レーンに最大8つまでデバイスを接続できる(8x2構成にして、その先にPCIe Switchを挟めばPCIe Gen3x4のNVMe SSDを8つぶら下げられる)など、柔軟性が大幅に増している。

機能が強化されたPCI Express。81というのは5×16+1で、この+1は管理用デバイスの接続などを想定しているものと思われる
おもしろいのが2 Socket構成である。初代EPYCの場合、PCIeレーンと(Socket間接続の)インフィニティー・ファブリックが共用だった関係で、2 Socketの場合はそれぞれのSocketから64レーンずつPCIeが出て、残りはSocket間接続に利用されており、結局2 Socketでも合計では128レーンでしかなかった。
ところが第2世代EPYCではSocket間の通信には18GT/秒の専用ポートを利用する関係で、それぞれのSocketから81レーンずつ、合計で162レーンが利用可能となっている。1 Socketならx16レーンを利用するアクセラレーターを8本接続できるのが、2 Socketではこれを10本に増やせる形だ。もちろんこれもNaplesプラットフォームをそのまま利用する場合は引き続き合計で128レーンに制限されることになる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































