




7nmプロセスに加え
8nmと6nmをロードマップに追加
話がいろいろ錯綜してくるのはここからだ。下の画像は昨年10月のスライドであるが、同社は10nmをLong-lived nodeと位置づけており、一方7nmについてはEUV(極端紫外線)を使わないものはShort-lived nodeになるとしていた。
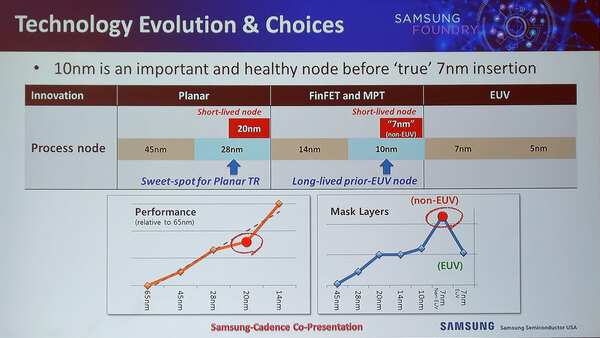
昨年10月にARM TechConでサムスンがCadenceと一緒に行なったプレゼンテーションより。この時は、まだEUVの出力向上に楽観的だったと思われる
この結果、同社は7nmのnon-EUV(つまりArF+液浸のQuad Patterning)に関してはプロセスを提供せず、EUV Readyになった段階で7nmをEUVでのみ提供する、という方針を示していた。理由は言うまでもなくコストである。
7nmのNon-EUVでのマスク枚数は10nm(ArF+液浸のTriple Patterning)の倍になるとしており、結果としてウェハー製造コストが大幅に跳ね上がるためだ。ついでに言えば当然マスクの製造コストを含むNRE(Non-Recursive Engineering)コストも倍にはならないにしても跳ね上がる。それを考えれば7nmはEUVオンリーの方が良い、という判断だった。
ところが、ここにきてその方針が少し怪しくなってきた。3月の10nmの量産発表の中に以下の一文があったからだ。
“サムスンはプロセスロードマップに、8nmおよび6nmを追加することを発表する。この8nm及び6nmのノードは、既存のプロセスノードと比較して、拡張性、性能、消費電力の点で優れている。8nmおよび6nmノードは、最新の10nmおよび7nmテクノロジーの特徴を継承しており、さまざまな顧客の要求を満たすための設計インフラの強化と、さらなるコスト競争力の強化を実現する”
この8nmと6nmの詳細は、5月に開催されたSamsung Foundry Forum 2017で公開されたらしいのだが、残念ながらこの詳細は明らかにされていない。ただ、もれ聞こえてくる話をまとめると下表のようになる。
| 8nmと6nmの詳細 | ||||||
|---|---|---|---|---|---|---|
| 8nm(8LPP) | 10nmノードの寸法縮小版。Triple Patterningで実現できるギリギリの線を狙った模様。さすがにTSMCの用にStandard Cell Libraryのみを縮小、という訳ではないらしい。ただ本当にTriple Patterningで済むのかどうかは定かではない(一部Quad Patterningが必要、という話もある)。 | |||||
| 6nm(6LPP) | 7nmの第2世代。6nmになった理由は良く分からないが、これも若干ピッチを詰めたもの、という話もある。もともとSamsungの7nmはTSMCやIntelの7nmに比べると若干寸法が大きめで、実質8nm程度という話もあり、これを他社の7nm並に詰めたのが6nmらしい。 | |||||
「らしい」が続くのは、サムスンがかたくなに情報を開示しないので確認が取れないためである。それはともかくとしてなぜこんなことになったのか?といえば、やはりEUVを利用しての量産開始が2019年後半になる(SamsungはEUVを使った7LPPのリスク生産開始を2018年後半、本格量産開始を2019年後半としている)ため、10LPPの本格量産開始から2年近く間隔が開いてしまうためだろう。
おまけに、もしなにかあってEUVを利用しての生産が必ずしも順調ではなかったり、あるいは量産開始までの時期がずれてしまったら、さらに間隔が開くことになる。これはサムスンだけでなくTSMCやGlobalfoundriesも同じだ。
TSMCにしてもGlobalfoundriesにしても、コストが跳ね上がるのを覚悟でArF+液浸のQuad Patterningで量産を開始するのは、万一EUVが遅れた場合でも、とりあえず7nm世代の量産はできるためである。
言ってみれば保険であるが、サムスンにはこれにあたるものが欠けている。したがって、今回追加された8LPPがその保険にあたるものと考えるのだが妥当だろう。ちなみにサムスンは8LPPの本格量産開始を2019年前半に予定している。

気になるのは「なぜ8LPPをこのタイミングで追加したか」である。ここまでの話は前から見えていたことであって、別に珍しい話でもなんでもない。サムスン社内では当然さまざまなオプションプランを検討していたはずで、そのうちの1つが8LPPだったと想像は付くが、であればもっと早く発表しても良かったはずだ。
これがサムスン社内の慎重派が強く主張して、それが通ったという程度の話であれば別に問題はないのだが、ASMLのスキャナーの状況などを勘案して、「こりゃいかん」と慌ててロードマップを更新した……という話ならばかなり問題は多い。
このあたりは2018年になってEUVベースのリスクプロダクションをファウンダリー各社が開始したあたりでもう少し情報が出てくると思われる。
5nmがFinFETを使う最後の世代
4nmではGAAFETを利用
ところで冒頭でサムスンはSTMicroelectronicsからライセンスを受けて28nmのFD-SOI(28FDS)を製造している、という話を書いた。
筆者が知っている範囲では、Lattice Semiconductorがこのサムスンの28FDSを使って次期FPGA製品を製造するほか、NXPがi.MX 7/8でやはりサムスンの28FDSを利用する予定だが、これに続き18nmのFD-SOI(18FDS)を開発することを明らかにしている。
また、FinFETについては6LPPに続き5LPP(5nm)と4LPP(4nm)もSamsung Foundry Forum 2017でロードマップとして示されている。
ちなみにSamsungによれば、5LPPはFinFETを使う最後の世代となり、4LPPではGAAFET(Gate All Around FET)を利用したMBCFET(Multi Bridge Channel FET)構成になる予定とされているが、こちらも詳細などは明らかにされていない。
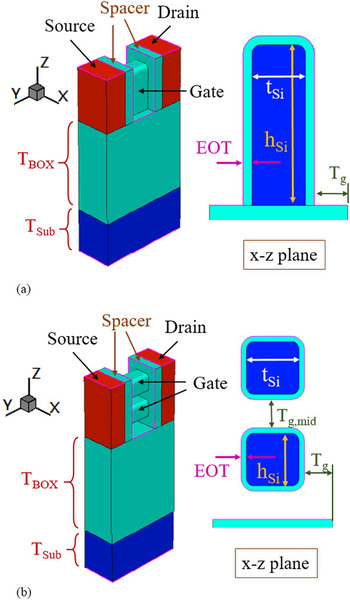
GAAFETの例。上がFinFET、下がGAAFETである。ゲートが配線の周囲を完全に囲み、その外側は絶縁層になっているのがわかる
画像の出典は、“GAAFET Versus Pragmatic FinFET at the 5nm Si-Based CMOS Technology Node”
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ














の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



















