




予想通り、GTC 2016でNVIDIAのGP100コアが発表された。今回はこのGP100の内部アーキテクチャーを主に解説しよう。
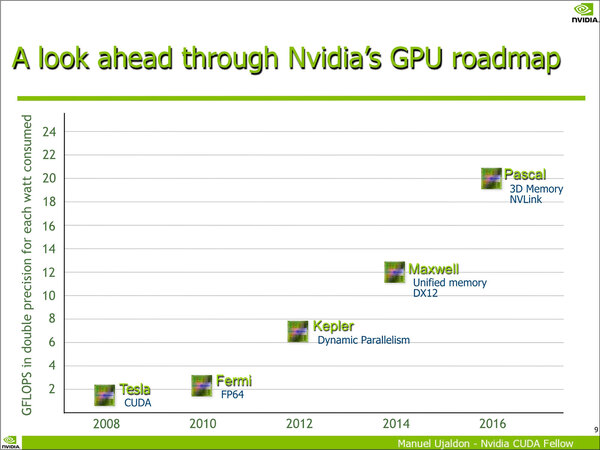
2014年~2017年のNVIDIA GPUロードマップ
Pascal世代の想定性能は
単精度で12TFLOPS、倍精度で4TFLOPSあたり
まず製品全般としてのロードマップであるが、前回のロードマップアップデートからほとんど変わらない。唯一違いがあるのは、どうも製品名は4桁にはならない、つまりGeForce GTX 1080にはならないらしい、ということだけである。
では、例えばGeForce GTX R80などになるのかS80になるのか、はたまたZ80なのか、といった具体的な話はまだ伝わって来ていない。とりあえず数字4桁の製品名はあまり好ましくはないと考えているのだそうで、数字は3桁に減らさせることになると思われる。
ちなみにGeForceグレード製品のスペックそのものは相変わらず不明のままで、HBM2/GDDR5X/GDDR5の使い分けかたも、まだ明らかになっていない。このあたりは、もう少し後で論じたいと思う。
さて、話をGP100に戻そう。昨年6月の話になるのだが、バルセロナ スーパーコンピューティング センターでPACT Cource:Introduction to CUDA Programmingというトレーニングコースが開催された(今年も5月末~6月に開催される)。
ここで“Innovations and futures of GP memory”というセッションが、NVIDIAのFellowであるManual Ujaldon氏を講師として開催されたのだが、このセッション資料がなかなか興味深いものだった。
このセッションは、2016年のPascalで3D積層メモリーを採用するという話を前提に、具体的にどんな形で利用可能になるかを論じたものである。
Pascalでは3D積層メモリーを採用する。この情報そのものは既知

2015年の段階の試作品。今回のGTCで展示されたものと比べると、穴の位置や電源回路などに微妙な違いが見られる
このセッションがおもしろいのは、この時には3D積層メモリーとしてHBMではなくHMCを主に取り上げていたこと、それとPascal世代の性能(単精度で12TFLOPS、倍精度で4TFLOPS)を示していたことだ。
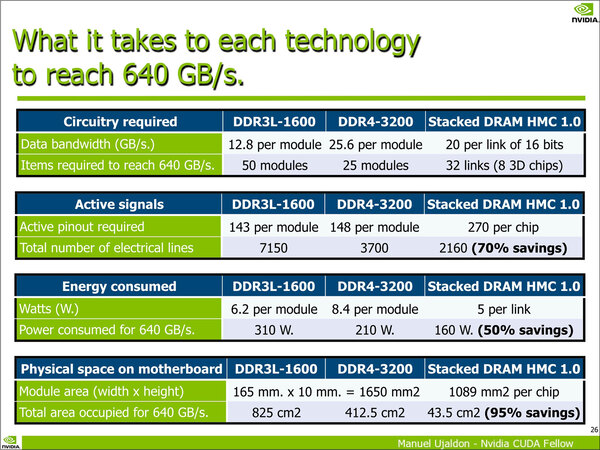
DDR3L-1600とDDR4-3200、それとHMC 1.0を比較するというおもしろい議論。主記憶としてのHMCという位置付けでのメリット/デメリットの議論である
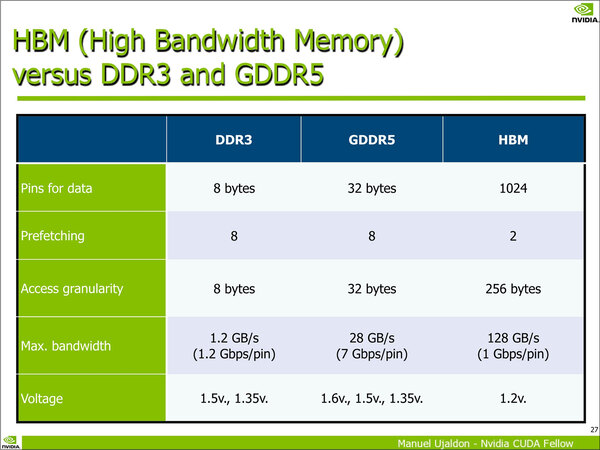
こちらはオンボードメモリー(つまりVRAM)としての特徴を比較したもの
ただスライド全部を見ても、PascalはHMCを使うとはどこにも書いてなく、単にHMC(ないしこれ相当の3D積層メモリー)を使うと、こんな具合に性能が上がるよ、ということでしかない。
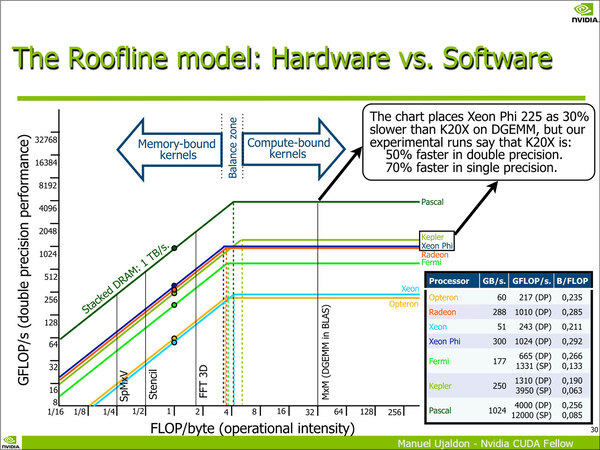
主眼は、3D積層メモリーを利用した場合、演算性能/メモリー帯域がどういう関係になるかを示したもの。KeplerやXeon Phiと比べて、Pascal+3D積層メモリーは高いバランスを取っていることが示されている
そもそもこのセッションは、大学など研究機関の研究者に向けて、CUDAを使うことで高い演算性能を利用できるので使ってほしいという無償のものであり、多分にマーケティング要素が含まれているとは言っても、あからさまな嘘はつけない。
したがって、少なくとも昨年6月の時点におけるPascal世代の想定性能は、単精度で12TFLOPS、倍精度で4TFLOPSあたりを目指していたと思われる。メモリー帯域はHMC 1.0×4と同等の帯域を予定していたというあたりだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ

















&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")












ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












