




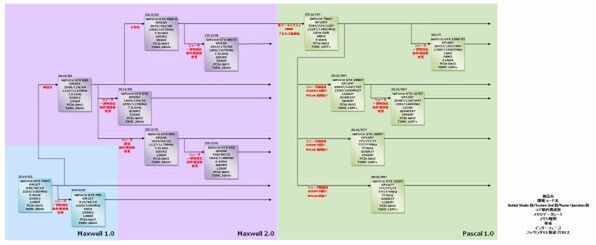
2014年~2017年のNVIDIA GPUロードマップ
テクニカルセッションとNVIDIAのブログで判明した
Pascalの内部構造
下の画像が全体の構成である。10個のSMをまとめて1つのGPCを構成、これが6つでトータル60個という計算だが、このうち4つのSMは無効化されているので、合計56SMという計算だ。
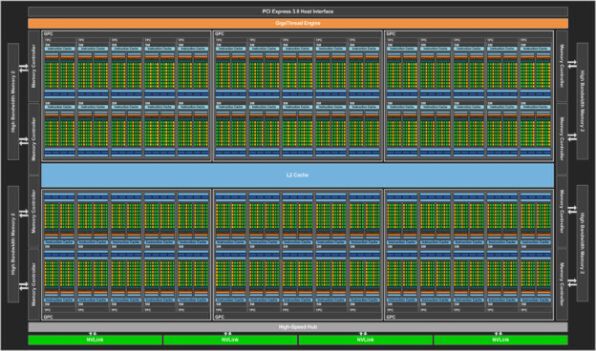
Pascalの全体構成。いささか図が潰れてていて見難いが、最上段はPCI Express 3.0 Host Interface、その下のオレンジの部分がGigaThreadEngine、中央のブルーがL2 Cache、下段のグレーがHigh-Speed Hubで、その下の4つのグリーンがNVLinkとなる
冒頭のロードマップ図で“GeForce Titan?”のRaster Operationの数が“120?”になっているのは、この無効化と関係ある。上の画像ではRasterizerが省かれているが、普通に考えるとRasterizerはSMとは別の場所に置かれており、SMを無効化してもRastezierは残っているように思われる。
すると、普通に考えれば120基が利用できるはずなのだが、実際にどうなのかははっきりしない。ちなみに3世代のTeslaの特徴をまとめたのが下の画像だ。
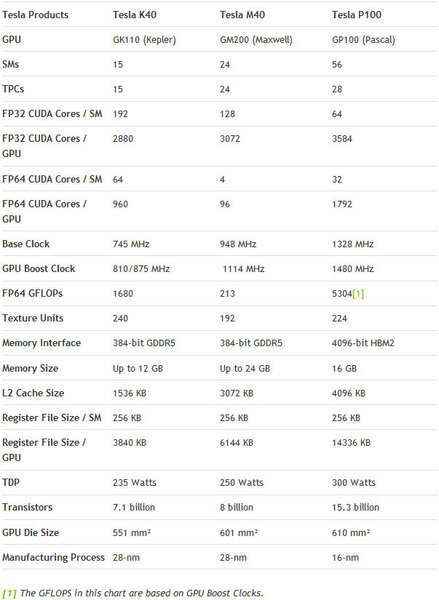
Teslaの特徴。P100は倍精度演算が5304GFLOPSなので、単精度では10608GFLOPSになる。ちなみにMaxwell世代のTesla M40では単精度でも7TFLOPSと発表されているので、おおむね50%増しとなる
倍精度もそうだが、Deep Learningでは単精度ですら多すぎるということで新たにFP16(半精度)がP100ではサポートされており、こちらでのピーク性能は21.2TFLOPSに達しており、MaxwellベースのTesla M40と比べて3倍の性能になる。
さて、上の画像でも小さく出ているが、GP100では4本のNVLinkが利用できる。NVLinkそのものは4対の双方向リンクになっており、リンク1本あたり40GB/秒、効率94%以上とされる。
効率、というのはおそらくPCI ExpressやUSB 3.0以降と同様にEmbedded Clockを採用しているためだと思われる。94%以上、ということだと64b/66b Encodingあたりを利用してEmbedded Clockを実装していると考えられる。
下の画像がP100×8+Dual CPUの構成で、これはDGX-1の構成向けのものと思われる。
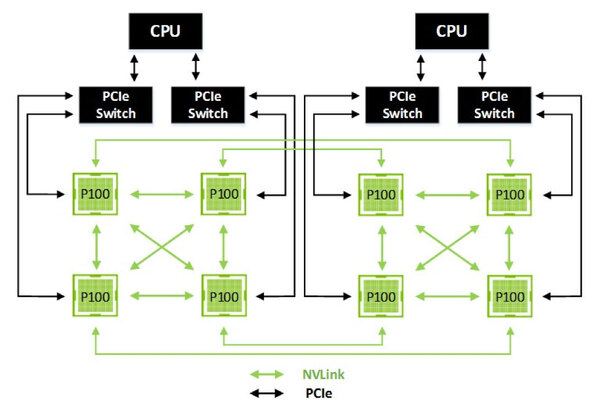
P100×8+Dual CPUの構成。PCIeのSwicthがCPUあたり2つ、というのはXeonがDual PCIe x16に対応していることに向けてと思われる
一方P100×4の構成例も示されており、直接NVLinkでの接続も可能とされる。
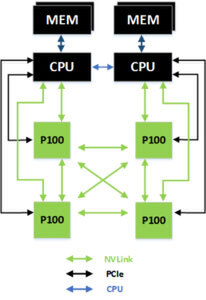
P100×4の構成例。こちらはCPUとしてIBMのPowerをベースにしたもので、Summit/Sierraはこの構成になると考えられる
あとはメモリーの話だが、NVIDIAのブログにはあまり詳細は書かれていない。とはいえHBM2を使うことは明らかにされており、利用されるダイ(HBM2のスタックを構成するメモリーチップ1つ)は8Gbitの容量だとされている。
つまりHBMスタック1つあたり32Gbit=4GB、これを4つ搭載するので16GBという形だ。これをTSMCのCoWoSを使ってGP100コアと接続している。帯域は1チップあたり1024bit/1GHz DDRでの接続なので256GB/秒、4つで1TB/秒という計算になる。
さて、話としてはこの程度だが、ついでにGP104などの構成について少し占っておきたい。まずSMの構成としては、Kepler世代と同様にGP104でもDP Unitを実装しつつ、無効化するだろう。これはDark Silicon絡みが理由だ。
ひょっとするとGP104ではDP Unitを省くかと思ったのだが、GPUの場合は通常のコアがフル稼働するので、熱密度がすごいことになる。したがって、多少熱を発生しないユニットをダイ上に残すことで、熱密度を緩和する必要がある。DP Unitはこの目的には手頃であり、またSMの再設計の手間を省くという意味でも有用だろう。
次がSM数であるが、GM204が28nmプロセスでおよそ300mm2程度だった。生産コストを抑えることを考えると、400mm2はかなり厳しいところであり、350mm2前後と仮定すると、SMの数は多くて36個(2304コア)あたりだろう。
GM204の2048コアに比べるとあまり差がないが、P100ですらベースで1.3GHz駆動が可能だったため、SM数を抑えたGP104では1.5GHzあたりも可能かもしれず、さらにWarp数を増やしたことで効率が改善しているため、性能もその分引き上げられると思われる。
問題はメモリー帯域だ。GP100では4FLOPS/Bytesを目指しており、実際はもう少し少ない(単精度で言えば10TFLOPS/1TBytesなので、10FLOPS/Byteの計算になる)あたりでバランスしている(4FLOPS/Byteとのギャップは2次キャッシュで埋める)形だ。もしGP104でも同程度の帯域を実現するとすると、おおよそ700GB/秒程度の帯域が必要になる(2304コア/1.6GHz動作で試算)。
これがGDDR5Xで可能か? というと、一応ぎりぎり可能ではある。GDDR5Xは、すでにMicronが14Gbps動作の型番をラインナップしており、14Gbps/384bit構成なら帯域は672GB/秒でほぼ700GB/秒が実現できるからだ。
512bit幅までやれば、900GB/秒近い帯域が確保できる。もっともこのクラスならそろそろHBM2を考えたほうがマシだとは思うが。以上のことから、2016年6月登場予定のGeForce GTX 1080相当のスペックはこれに準じたものとした。
またGeForce GTX 1070相当のものは、おおむねGeForce GTX 980と同等のシェーダー構成で動作周波数をやや引き上げたあたりでバランスさせてみた。この構成では、GDDR5Xは12Gbpsのものでも間に合う計算になる。もっともこのあたりは完全に筆者の推定なので、よく眉につばをつけて見ていただきたい。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第886回
PC
CFETの足を引っ張るPMOSを救え! imecが提案する新絶縁層と、あえて精度を緩める「Notch Alignment」の妙手 -
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 - この連載の一覧へ











、バッテリー駆動時間は13時間超え。もう欲しくなる要素しか見つからないッ!")








ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")
















