




Cyclops64のチップが世に出ることはなく
シミュレーションでプロジェクトが終了
プロジェクトではチップの設計だけでなく、アプリケーションの性能をいかに引き出すかという部分もいろいろと研究された。デラウェア大学のGuang R. Gao主幹教授の論文では、FFT(Fast Fourier Transform:高速フーリエ変換)、LU分解、SCCA2ベンチマークなどで、それなりに高い性能を引き出しやすいことが示されている。
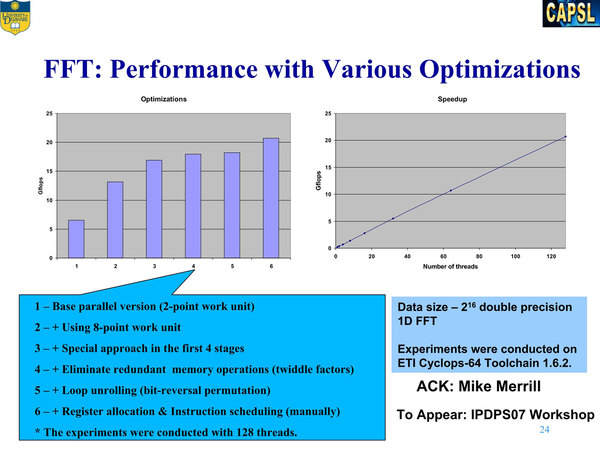
これは128スレッド(64コア)でのFFT数値。何もしないと7GFLOPSそこそこしか性能が出ないのが、最適化を施すと3倍の21GFLOPSまで性能が上がる
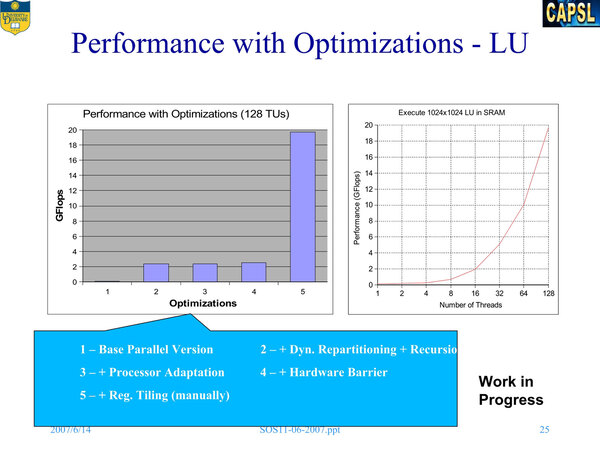
LU分解。こちらも最適化で大きく性能が上がることが示されている
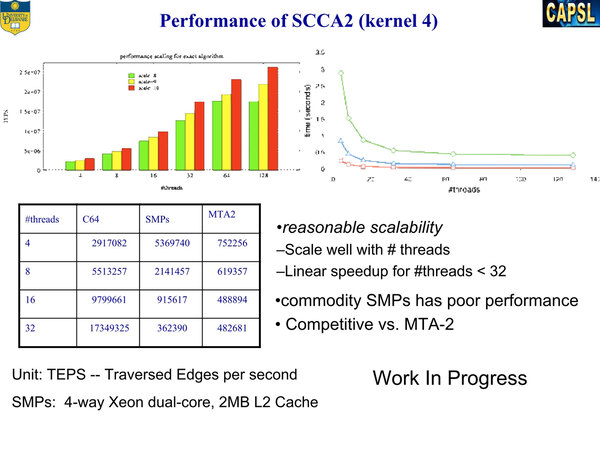
SCCA2ベンチマーク。こちらでは4wayのXeon Dual Core SMP、それとMTA2も比較対象にしており、Thread数が増えると急速に性能が上がることが示されている
もっとも、必ずしも使いやすいとも言い切れない部分も多分に存在した。同じGao主幹教授も共同執筆者に名を連ねている“Optimization of Dense Matrix Multiplication on IBM Cyclops-64: Challenges and Experiences”という論文では、結論として「データがSRAM内に納まる範囲内では、タイリングやループ除去、レジスター割り当て、命令スケジューリングが最も重要なファクターであり、この際にはスクラッチパッドは煩雑に利用するデータの格納に利用できる」
「ところがデータがSRAMに納まりきらない場合、DRAMの帯域がボトルネックになる。そこでSRAMをDRAMアクセスのバッファとして使い、さらにDRAMアクセスを計算処理とオーバーラップさせるようにすることで、大幅に性能を改善できる」としている。
また、コンパイラに対しては「最内周ループでのレジスター割り当てが最大のポイント」だと指摘している。要するに、アプリケーションを書く際にはデータ量を気にしないといけないということだ。
IBMによる“Dissecting Cyclops:A Detailed Analysis of a Multithreaded Architecture”という論文では、「メモリーとロジックを混載させたことで、純粋なロジックほど高速化できず、また純粋なメモリーほどメモリー容量を大きくできないという制約が課せられた」ことと「現状のCyclopsは1MFLOPSの計算能力に対して250バイト程度のストレージしか提供できず、1MFLOPSあたり1MB程度のストレージを提供できる従来型のシステムに比べて見劣りする」ことの2点を、Cyclopsのアーキテクチャー上の制約として示している。
また、高い性能を引き出すためには、とにかくスレッド数を増やすことが重要であると指摘している。
さて、ここまでで気がついた読者もいるかもしれないが、実はCyclops64のチップそのものは存在しない。チップの設計後、そのモデルを搭載したファースト・シミュレーションとラストシミュレーション、場合によってはMr.Clopsを利用してさまざまなアプリケーションを移植した結果を評価する、という形でプロジェクトは遂行された。
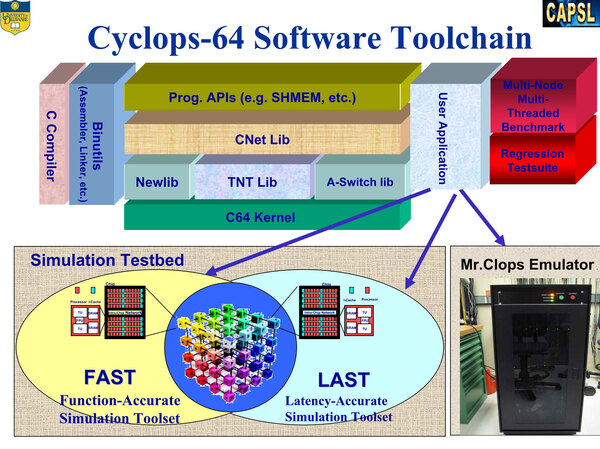
FAST/LASTのシミュレーターは別のプラットフォーム上で動作した模様。Mr.Clopsはハードウェアエミュレーターである
GENESISを彷彿させる話だが、結果から言えばインテルのように3D積層のメモリーなどを考えない限り、2007年時点での技術ではワンチップ化にはあまり意味がないということを明確にできたのは、効果的ではあっただろうと思われる。
ちなみにWikipediaでは“The architecture was conceived by Seymour Cray Award winner Monty Denneau, who is currently leading the project.”(アーキテクチャーは、現在プロジェクトの指揮を取っており、シーモアクレイ賞受賞者のMonty Denneauによるものと思われる)と、まだCyclops64プロジェクトが続いているかのように書かれている。
しかし、ほとんどの論文が2006~2007年で、わずかに2009年のものがある程度であり、主要な論文に名前を連ねていたGuang R. Gao主幹教授の現在の研究プロジェクトにはCyclops 64の名前はなく、すでに終了している。
2012年にGao主幹教授が出した“Overview of HPC Computer Architecture:A Long March Toward Exa-Scale Computing and Beyond”というプレゼンテーションによれば、Cyclops64プロジェクトは“2004-2010+”という微妙な表現になっているが、少なくとも2012年9月の時点では終了している。
無理にチップを量産してシステムを作って「やっぱり問題が多かった」と言うよりはずっとスマートな方法ではあったとは思う。
ちなみにプロジェクトの指揮を取っているとされたMonty Denneau氏は2013年にIBMのFellowとなっているが、経歴ではCyclops64ではなくGF-11が前面に出てきているあたりがまたなんとも……という感じではある。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















