





Tera Computer Co.の「MTA-1」
今回から再びスーパーコンピューターの話に戻る。連載310回からしばなくアクセラレーターを解説してきたが、こちらはまだ現在進行形の話であり、この先の話はもう少し時間が経たないと説明できない。
そもそもなぜアクセラレーターの話をしたかといえば、ASCI/ASCの先端システムが全部CPU+GPUのハイブリッド構成に急速に移行しているからで、ASCI/ASCの話を追ってゆくと必然的に触れる必要があった。
ただASCの現役最高性能のSequoiaや、ASCと直接関係はないが、Titanなどの話はすでに解説した。
これに続きIBM/NVIDIA連合がPower8+GPUベースでオークリッジ国立研究所とローレンス・リバモア国立研究所に納入するSummit/Sierraは、インストール開始が2017年、オペレーション開始が2018年を予定している(関連リンク)ため、まだ説明をするには早すぎるし、資料もない。
ということで、このあたりで一度ASCI/ASCのシステムの変遷を追っていくのは一旦やめにして、これまで歴史を追っていく中で説明を後送りにしたものをいろいろ拾っていきたいと思う。
今回はその1つ目ということで、Tera Computer Co.のMTAの話をしたい。Tera COmputer Co.は以前、Red Stormの説明のところで少し出てきた。
ちなみにこの記事ではうっかり「ところが2000年、SGIはカナダのTera Computer Co.にCRI部門を丸ごと売却してしまった」と書いてしまったが、カナダではなく「カナダに近いワシントン州シアトル」の会社である。お詫びして訂正したい。
SMP+SMTに近い独特な構成となった
Tera MTA
そのTera Computer、設立は1988年のことである。創立したのはJim Rottsolk氏とBurton Smith氏の2人で、Rottsolk氏がCEO、Smith氏がChief Scientistの職を担っていた。両者は2005年に辞任しており、奇しくも2人とも現在はMicrosoft(Rottsolk氏はMicrosoft SiArchのSenior Director、Smith氏はTechnical Fellow)に在籍している。
そのTera Computerが最初に手がけたのはThreaded Processorである。最初の製品であるTera MTA(あるいはMTA-1)は、Multi-Threaded Architectureの頭文字をとったものである。
MTA-1はその名の通り、内部に仮想的に128のバーチャルプロセッサーを実装し、このそれぞれが別々のスレッドに割り当てられている。最近の言い方にすれば128wayのSymmetric Multi Thread(SMT)の構成と考えればいい。
もっとも、昨今のSMTとはやや異なる部分もある。通常のSMTマシンの場合、どれだけスレッド数が増えても、それを実際に処理する実行ユニット部に関しては固定である。例えばSMT対応のプロセッサーが2つあっても、あるスレッドの処理が2つのプロセッサーをまたいで処理されることはない。
これに対してMTA-1の場合は、複数の物理プロセッサーにまたがる形で、あるスレッドの処理を分散して処理可能である。もう少し正確に書くと、複数のプログラムからさらに複数のスレッドが生成されることになるが、この生成されるスレッドがプロセッサーをまたぐ形で実行可能ということである。
要するにSMP+SMTの構成に近い形だ。ただしその規模がまったく異なる。下図は1ノードのMTA-1内部の模式図であるが、インターコネクト・ネットワークを経由する形で最大256のプロセッサーと最大512のメモリーユニット、他に最大256のI/Oキャッシュユニットと256のI/Oプロセッサーを接続可能だ。
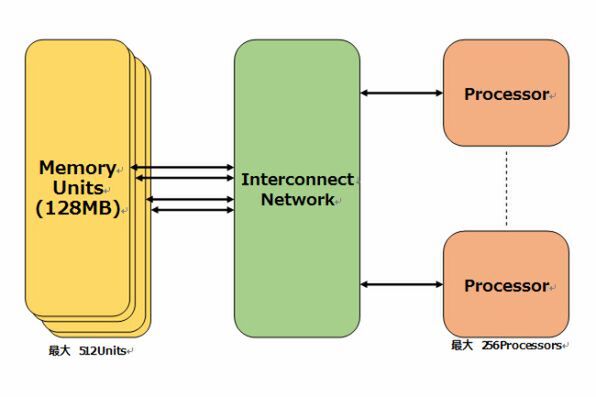
MTA-1内部の1ノードあたりの模式図
このインターコネクト・ネットワークは16×16×16の3Dメッシュ構造を持っており、最大ノード数は4096になる。プロセッサーやメモリー、I/O類を全部接続しても1280ノードなので残りは未接続のままであるが、あえて未使用のまま残してあるそうだ。
これはレイテンシーの最適化を図るためで、インターコネクトは常に最短の経路を通って通信を行なうように工夫されているという。
→次のページヘ続く (ガリウム砒素で製造しPentium IIより高性能に)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






























