




第1世代の14nm FinFETプロセス
「14nm XM」
ではなぜSamusungと提携することになったかという話をするために、まずは14nm XMの話を少し解説したい。GLOBALFOUNDRIESは2012年9月、14nm FinFETプロセスである14XM(eXtreme Mobile)を発表する。当時はまだ28nmの量産に苦闘していた時期であるが、それもあってか2014年に14XMを導入することをアピールした。

プロセスの歴史。2012年はまだ28nmの量産に苦闘していた時期。この頃は28nm FD-SOIが2013年に提供予定と、さらっと書いてあるのもおもしろい
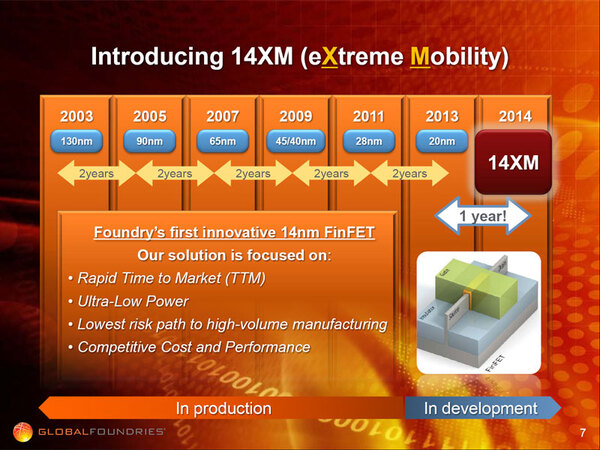
2014年に14XMを導入することをアピールしている。そもそも28nmがまともに生産できるようになったのが2013年に入ってからというあたり、突っ込みどころは多い
この14XM、下のプレゼンテーション資料にもあるように、基本的には20nm LPMプロセスを下敷きとしたものである。

14nm XMのプレゼンテーション資料。HKMGもこの世代からGate Lastになることが明らかにされている
その20nm LPMは自社の28nm、あるいは他社の20nmと比べても優秀というふれこみであり、これを14nm FinFETと組み合わせることで優れたプロセスになるという話であった。
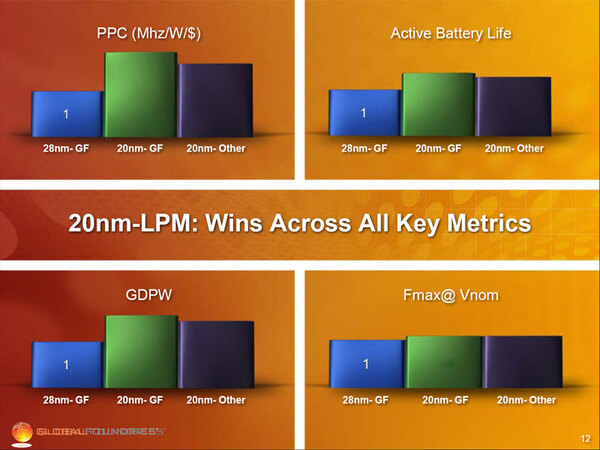
20nm LPMは自社の28nm、あるいは他社の20nmと比べても優秀。なお、GFPWはGood Die Per Waferの略で、歩留まりのこと。PPCはPower/Performance per Costの略である

20nm LPMと14nm FinFETを組み合わせることで優れたプロセスになる。MOL(Middle of Line)は、この場合配線層のこと
肝心のFinFETの性能は、同じ電圧であれば20~55%向上し、逆に同じ動作周波数であれば消費電力を40~60%削減できるとしていた。
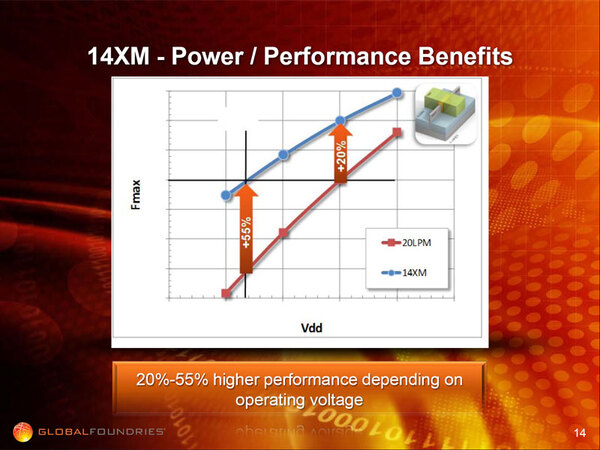
FinFETは、同じ電圧であれば20~55%性能が向上するという。目盛りに数字が振ってないのがミソ
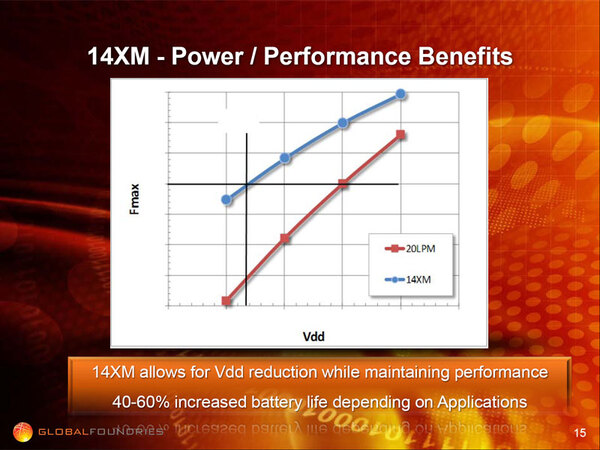
電流が同じと仮定すれば、電圧を20~30%下げられることになる
別のデータもある。下の画像は、2013年に行なわれたSemicon Westで前CEOのAjit Manocha氏が行ったの基調講演のプレゼンテーションに含まれているものだが、GLOBALFOUNDRIESの28nmプロセスと20LPM、それと14XMを比較したものである。

28nmプロセスと20LPM、それと14XMを比較したもの。いずれもシミュレーションでの結果であり、実際のシリコンを使って測定したものではない
同じ消費電力であれば、20LPMに比べて14XMは20%高速化可能であり、逆に同じ速度であれば14XMは20LPMよりも38%消費電力を減らせる。また、同じ設計であれば14XMは20LPMよりも5%のダイサイズ削減が可能としている。
ところで、どうしてダイサイズが削減できるかといえば、これはトランジスタの駆動能力に関係してくる。FinFETは構造的にプレーナ型よりも大量の電流を駆動させやすい。これは連載248回の写真にもあるように、マルチゲート構造を簡単に取れるためである。
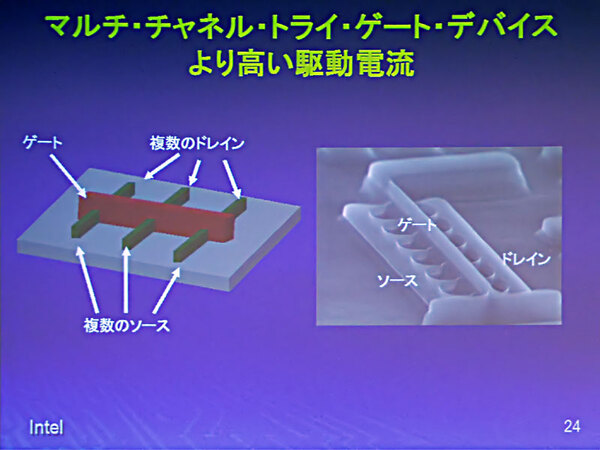
3D構造方式のメリット。大きな出力が必要な場合、普通はトランジスタを並列に複数並べるが、3D構造ではこれをまとめて作りやすい
この結果として、例えば4ゲート構造のFinFET1個とプレーナ型トランジスタ4つを並べるののどちらが面積が小さくなるか、という話になるわけで、言うまでもなくFinFETの方が配線が減るので小さくまとまる。
20nmと14nmで配線が共通の場合、すべてのプレーナ型トランジスタを単純にシングルゲートのFinFETに置き換える限りは、実装面積(≒ダイサイズ)は同一である。ただしマルチゲートFinFETを念頭に物理配線を最適化した場合、同じ配線プロセスであっても実装面積を小さく出来る場合もある。これが5%という差になったと考えればいい。
また別のデータとしては、昨年11月にEDA大手ベンダーの1つであるCandenceが実施したDesign Signoff Summitで、Director Desgin MethodologyのRichard Trihy氏が紹介した資料が下の画像だ。

これはマルチコアGPU向けに性能を一致させた場合の消費電力削減の効果と、CPU向けに消費電力を一致させた場合の性能向上効果を示したもの。おそらくGPUは、ARMのMaliあたりをターゲットにシミュレーションした結果と思われる
具体的には、14XMを使ってデュアル「Coretex-A9」を構成した場合と、同じコアを28nmSLPで構成した場合での性能/パワー比較が示されている。
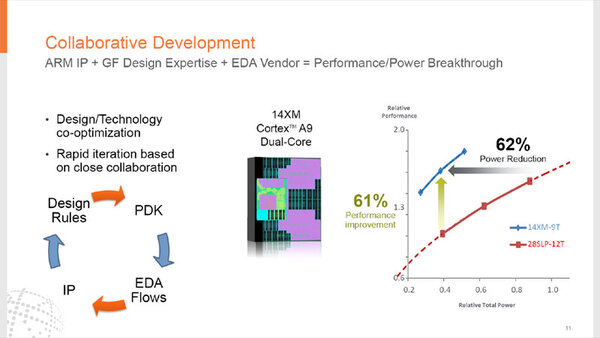
14XMを使ってデュアル「Coretex-A9」を構成した場合と、同じコアを28nmSLPで構成した場合での性能/パワー比較。Cadenceのイベントでこれを説明していることからもわかる通り、同社もこの14XMをサポートしていた
この数字そのものは2013年2月に公開された、Test Vehiecleを使って製造したテスト品をベースにしていると思われる。本当に14XMがリリースできれば、結構期待が持てるプロセスだったことがわかる。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ










が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")

















