




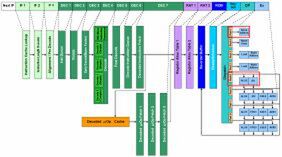
図1 Haswellの内部構造図。赤枠内がSandy Bridgeからの主な変更部分
- A=A×B+C
Sandy Bridge世代では浮動小数点で上の演算を行なう場合、以下のように2つの命令に分けて処理を行なう必要があった。トータルでのレインテンシーは8サイクルかかる。
- A=A×B (レイテンシー 5サイクル)
- A=A+C (レイテンシー 3サイクル)
これがHaswellの世代では1回でできるので、前掲のスライドにも「Latency:5 cycles」と記述されている。
そのほかにも、これまではSSE3/SSE4などで提供されてAVXには含まれていなかった命令を、全部AVXで取り込むようにしたり、強力なデータの並べ替え機構(AVXレジスタにデータを取り込む時の指定方法を強化)、bit演算命令などの追加という改良が加えられている。
AVX強化に合わせて、
1次データ/2次キャッシュの帯域も強化
ただし、AVX命令の性能を強化した結果、データ入出力についても強化しないといけなくなった。例えば「A=A+B」という演算では、2つの処理が必要になる。
- ①AとB、2つの値を読み込む
- ②計算後にAの値を書き出す
従来のSSEは128bitだったので、読み込みが16byte(128bit)×2で32byte/サイクル。書き出しは16byte/サイクルの帯域が必要である。Sandy Bridgeはこれに合わせてLoadユニットを増加させていたが、AVX2で演算性能が倍になると、これらの帯域も倍増させないと間に合わなくなった。
そのため、CPUコアと1次キャッシュ(正確には1次データキャッシュ)の帯域は、ついに読み出しが64byte/cycle、書き込みが32byte/cycleで、合計96byte/cycleの帯域を持つように強化された。それに合わせてデータ1次キャッシュと2次キャッシュの間の帯域も、Sandy Bridge世代の倍である64byte/サイクルに強化されている。
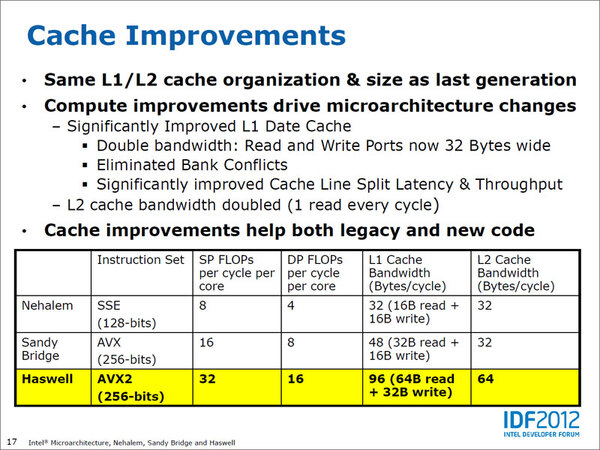
Haswellでのキャッシュ強化についての説明スライド。右に帯域幅の強化について記されている。命令に関しては引き続き16byte/サイクルの命令フェッチが維持されているので、こちらに関しては帯域はNehalem世代と同じく、16byte/サイクルのままと思われる
ただし、上のスライドにもあるとおり、1次/2次キャッシュの構成やサイズそのものは、Sandy Bridge世代と変わっていない。また別の資料によれば、1次/2次キャッシュへのアクセスレイテンシーも「不変」とあるので、この帯域倍増は純粋に、バスの配線を倍増する形で実装したものと思われる。もちろん、バス幅以外まったく同じというわけではなく、書き戻しの際の干渉を軽減したり、キャッシュライン※1をまたがってデータアクセスする場合の効率を改善したりと、さまざまな工夫はされている。
※1 キャッシュは通常、32byteあるいは64byte単位で管理されており、この最小単位をキャッシュラインと呼ぶ。キャッシュにリクエストを出す場合、このライン単位で読み書きをするため、これにぴったりあった形で読み書きをすると高速だが、ラインをまたがった場合は著しく効率が落ちる。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ










が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")

















