




前回に引き続いて、今回も「Haswell」の詳細を解説する。まずは追加された「AVX2」命令から説明しよう。
HaswellでのAVXの強化
1サイクルで256bitの演算が可能に
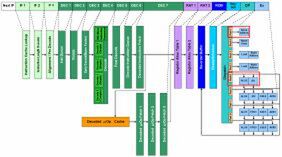
図1 Haswellの内部構造図。赤枠内がSandy Bridgeからの主な変更部分
AVX2命令は、Sandy Bridge世代で投入された「AVX」命令の機能と性能を拡張するものである。大きなポイントは以下の3点だ。
- 性能が2倍
- 浮動小数点のFMA(Fused Multiply-Add)演算をサポート
- いくつかの新命令を搭載
まず性能が2倍の根拠はなにか。Sandy Bridge世代でのAVX演算は、既存のSSE用演算器を流用して実装されていた。SSEはご存知のとおり、1サイクルあたり最大128bitの演算を行なう(関連記事)。そのためAVX演算の場合は、128bitずつ2回に分けて演算を行なうことになっていた。
これに対してHaswellでは、SSE演算器がすべて拡張され、AVXにあわせて1サイクルあたり256bitの演算が可能になっている。そのため、従来だと2サイクルを要していた演算が全部1サイクルで可能となり、これだけ見れば性能が倍になった形だ(Photo01)。ただし、残念ながら「それならSSEを使えば、1サイクルあたり2つのSSE命令が実行できる」とはいかない。あくまでもAVX命令を使った場合のみ有効である。

1サイクルあたりのSSE/AVX/AVXの演算可能な数。Single Precision(SP、単精度浮動小数点演算)なら1サイクルあたり最大32個。Double Precision(DP、倍精度浮動小数点演算)でも1サイクルあたり16個が演算可能になっている
次のFMA(Fused Multiply-Add)とは、乗算と加算が混じった形の演算である。
- A=A×B+C
この演算を1回で行なうというものだ。実はこの形の演算は、自然科学の分野では非常に広範囲で使われており、シミュレーションを初め多くの分野で利用されている。AVX命令もこのFMAをサポートしているのだが、Sandy Bridgeの世代では整数演算でしか利用できなかった。Haswellではこれを、浮動小数点演算に拡張した点が大きな差となっている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ












ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")











ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












