




ChatGPTで話題“ジブリ風”も
WebのUIの機能強化も続いており、しばらく前から、画像をドラッグ&ドロップすると、適当に4つのプロンプトを作ってくれて、それで生成を始めると、一斉に画像のバリエーションを出してくれます。ちょっとしたものから複雑なことまで、様々なことができるようになりました。コンセプト出しの時間が短縮できます。画質の品質もさらに高まっており、例えば、「ジブリ風」の画像もかなり雰囲気が出ます。試しに、Stable Diffusionで生成したSFバイクに乗るキャラクターの画像を読み込ませてみたところ、ジブリ風のキャラクターがSFバイクに乗っているような画像として出力されてきました。

いわゆるジブリ風のキャラクターが乗るSFバイク。プロンプト解析に使った筆者作成の元画像は、ジブリ風ではなかったが、日本アニメ風だったので、ジブリ風と判定されたよう
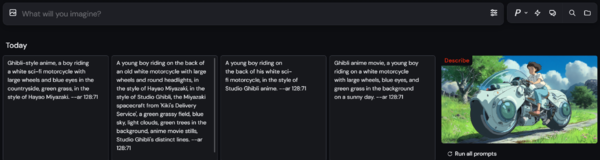
上記の画像から、MidjouneryのUI上で、さらにプロンプトを自動生成したもの。4種類のプロンプトが解析されて自動生成されており、いずれのプロンプトも「Ghibuli(ジブリ)」というワードが入っている。ただ、こういう固有名詞的なワードが入る場合は、著作権侵害の要件の一つである「類似性」を満たす生成物が生まれるリスクがあるので、生成後、類似性を持った画像が生成されていないか、Googleイメージ等でのセルフチェックを推奨したい

ただし、ジブリ風がプロンプトに入っていても、ムードボードなどを組みわせると簡単にまったく違う雰囲気の画像になる。筆者の別のムードボードを組み合わせた例
もちろん、全体的に表現力が上がっています。ほとんどすべてのジャンルに対応できて、描画できないものはなくなってきているという印象です。
Midjourney→動画生成も増加
画像全体の情報量も増している印象がします。過去のMidjouneryは細かいところが、曖昧になり溶けてしまう傾向がありましたが、v7では、そうした部分に一定の抑制が効いています。ChatGPTが4o Image Generatiorで入れてきたようなマルチモーダル性はまだ入っていないので、同じ画像の角度を変えるといった汎用性はまだないのですが、伝統的なクラウド型の画像生成AIサービスとしては圧倒的ですね。
Midjourneyは動画生成の素材として使われていることも増えています。Midjourneyで作った画像を、Wan2.1やKling AIなどの動画生成サービスで動かすといったものです。

過去に筆者が作成していた画像をプロンプト解析をさせて改めて作ったファンタジー系イラストの画像。v7で、ディティールの描写がより精密になっている
▲キャラクターが乗ったSFバイクをWan2.1でアニメーションにしてみた作例
AI動画生成サービスについては、Midjourney自身も去年から開発していることをアナウンスしていましたが、まだローンチにはたどりつけないようです。4月5日に公式Discordで実施したオフィスアワー(ユーザー向け説明会)では、4月末に完成予定だとしていました。しかしまだリリース日は未定で「手頃な価格モデルを提供することが目標」としています。つまり、現在の画像とは別料金となる可能性がありそうです。ただ、他社との提携やライセンスではなく完全に独自モデルをトレーニングしているようです。
Midjourneyでは3DモデルAIの開発を進めており、さらに、VR/ARハードの開発を進めていることも明らかにしています。ただ、発表時期はまったく未定のようです。それでも、Midjouneryの長期ビジョンとして、単に2D画像生成をつくるだけでなく、メタバース的な世界の自動生成といったものを目指すことは変わっていないようです。
この連載の記事
-
第147回
AI
ゲーム開発開始から3年、AIは“必須”になった──Steam新作「Exelio」の舞台裏 -
第146回
AI
ローカル音楽生成AIの新定番? ACE-Step 1.5はSuno連携で化ける -
第145回
AI
ComfyUI、画像生成AI「Anima」共同開発 アニメ系モデルで“SDXL超え”狙う -
第144回
AI
わずか4秒の音声からクローン完成 音声生成AIの実力が想像以上だった -
第143回
AI
AIエージェントが書いた“異世界転生”、人間が書いた小説と見分けるのが難しいレベルに -
第142回
AI
数枚の画像とAI動画で“VTuber”ができる!? 「MotionPNG Tuber」という新発想 -
第141回
AI
AIエージェントにお金を払えば、誰でもゲームを作れてしまうという衝撃の事実 開発者の仕事はどうなる? -
第140回
AI
3Dモデル生成AIのレベルが上がった 画像→3Dキャラ→動画化が現実的に -
第139回
AI
AIフェイクはここまで来た 自分の顔で試して分かった“違和感”と恐怖 -
第138回
AI
数百万人が使う“AI彼女”アプリ「SillyTavern」が面白い -
第137回
AI
画像生成AI「Nano Banana Pro」で判明した“ストーリーボード革命” - この連載の一覧へ



とは")













の1台が今ならオトク!")




























")

