



拡大するGPUサーバーニーズにも柔軟に対応できる「GPU over APN」実現に向けた第一歩
複数DCに分散設置したGPUクラスタで生成AI学習、NTT ComがIOWN APNで実証に成功
2024年10月07日 19時00分更新

NTTコミュニケーションズ(NTT Com)は2024年10月7日、IOWN APN(オールフォトニクスネットワーク)を活用した分散データセンター(DC)での生成AI学習実証実験に成功したことを発表した。
実験では、これまで単一データセンター内で構成されてきたGPUクラスタ(GPU搭載サーバーのクラスタ)を、IOWN APNの100Gbps回線で接続した2つのデータセンターに分散配置。分散学習に対応した生成AIモデル開発プラットフォーム「NVIDIA NeMo(ニーモ)」を使った小規模な学習処理を実行し、単一データセンター内のGPUクラスタとほぼ同等の時間で処理できることを示した。
NTT Comでは、IOWN APNで接続した複数のデータセンター間でGPUクラスタを分散配置するアプローチを「GPU over APN」と位置付け、今後、さらに大規模なGPUクラスタでの実証を進めたうえで、自社の商用サービスへの適用や、共創パートナーとのソリューション開発に発展させていく方針だ。
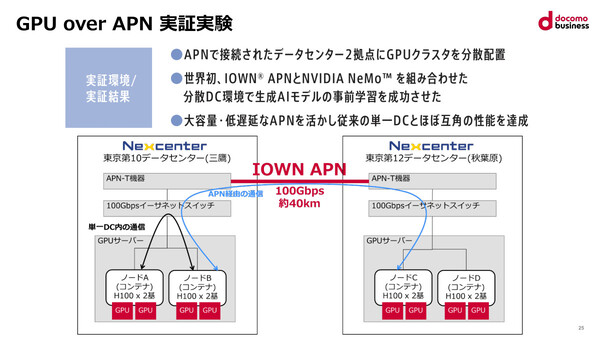
実証実験の概要。2つのデータセンター(三鷹と秋葉原、距離およそ40km)間をIOWN APNの100Gbps回線で接続し、分散配置したGPUクラスタを使って生成AIモデルの事前学習処理を実行した
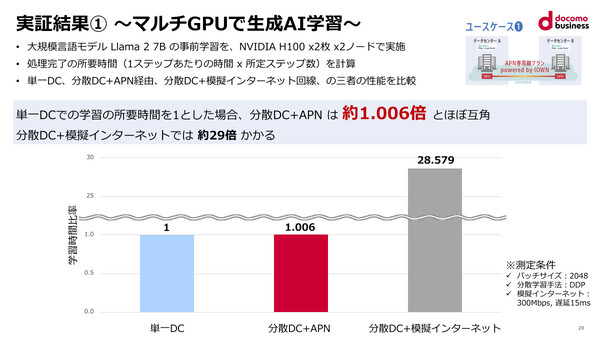
実証実験の結果。今回の分散GPUクラスタによる処理時間は、単一データセンター内のGPUクラスタの「およそ1.006倍」と、ほぼ同等となった


NTTコミュニケーションズ イノベーションセンター IOWN推進室 担当部長の張 暁晶氏、同 エバンジェリストの林 雅之氏
APNで遠隔分散GPUクラスタを実現する「GPU over APN」の狙い
記者発表会では、NTTコミュニケーションズ イノベーションセンター IOWN推進室から担当部長の張 暁晶氏、エバンジェリストの林 雅之氏が出席して、今回の実証実験を行った背景や今後の展開などを説明した。
張氏は、GPU over APNの実現に取り組む背景として、単一データセンター内で構成したGPUクラスタにはさまざまな制約があることを指摘する。「柔軟、オンデマンドにGPUリソースを入手できない」「他のデータセンターに移動できない機密データの取り扱いが難しい」「データセンターの床面積や電力供給量に限界がある」といった制約だ。
複数のデータセンターをまたぐかたちで1つのGPUクラスタを構成できれば、こうした制約は解消/緩和できる。ただし、そのためには低遅延のデータセンター間ネットワークが必要だ。そこでIOWN APNの出番となる。
IOWN APNではすでに、NTTが約100kmの距離にあるデータセンター間を1ミリ秒未満の遅延で接続する実証実験に成功している。さらに、約70kmのデータセンター間での秘密計算処理も実証済みだ。
張氏は、GPU over APNで想定される2種類のユースケースを示した。GPUクラスタのノードを2つのデータセンターに分散配置するもの(ユースケース1)と、一方のデータセンターにあるGPUクラスタがAPN経由で他方のデータセンターにあるストレージに接続してデータの読み書きを行うもの(ユースケース2)だ。今回は両方のユースケースで実証実験を行っている。
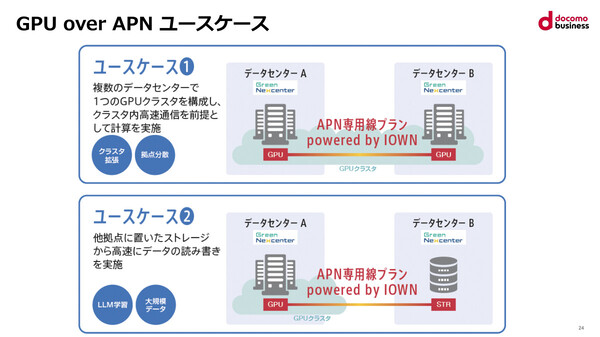
GPU over APNで想定される2種類のユースケース。今回はそれぞれの実証実験が行われた
ユースケース1では、LLM「Llama 2 7B」の事前学習を2ノードで分散処理するワークロードを実行した。2つのノード間を、100Gイーサネット(単一データセンター内)、100G IOWN APN(分散データセンター)、300Mbps/遅延15msの模擬インターネット(分散データセンター)という3つのネットワークで接続し、処理に要する時間をそれぞれ算出している。なお、分散データセンター間はおよそ40kmの距離がある。
前述したとおり、IOWN APN経由の分散GPUクラスタにおける処理時間は、単一データセンター内のそれとほぼ変わらない(1.006倍)ことがわかった。ちなみに、模擬インターネットを使った分散処理の場合はおよそ29倍の時間がかかるという結果も出ており、IOWN APNの優位性が示されている。
もうひとつのユースケース2では、GPUクラスタからストレージサーバーへのNFSアクセス性能を、上述した3種類のネットワークで計測した。こちらも、IOWN APN経由で読み出し処理にかかる時間は、単一データセンター内の1.1倍に収まるという。一方で、模擬インターネット経由では2613倍もかかるとされている。
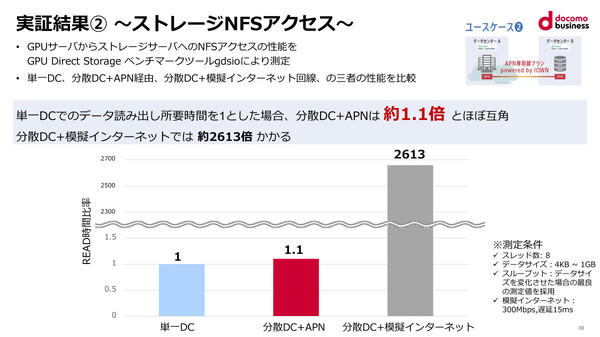
ユースケース2、GPUクラスタから遠隔データセンターにあるストレージサーバーへのアクセス性能。こちらでもIOWN APN経由でかかる時間は、単一データセンター内の場合とほぼ同等だった
なお今回の実証実験では、GPUサーバーとして「NVIDIA H100」GPU 2基×2ノードを搭載した「DELL Power Edge XE8640」を、またストレージサーバーとして「Dell Power Scale F710」を用いた。またソフトウェアスタックにはNVIDIA NeMoを採用した。実験環境の管理のために、学習処理の進捗を可視化するダッシュボード「Weights & Biases」、機器状態を監視するダッシュボード「DELL Observability」を用意し、分散データセンター環境を一元的に可視化できる仕組みとして活用したという。
より大規模なクラスタ/処理の実証も進め、商用化を目指す方針
実証結果のまとめとして張氏は、いずれのユースケースにおいても「分散データセンター+IOWN APNで実用的な性能が実現できること、インターネット回線と比べて優位性があることが確認できた」「(GPU over APNで)GPUクラスタを複数のデータセンターに分散配置できる可能性が開かれた」と述べた。
ただし今回の実証環境は、LLMの分散学習処理としては小規模なクラスタ構成(2ノード)によるものだ。張氏も「今回の実証は小規模な環境で、比較的軽量な処理を試したもの」であることを強調したうえで、今後はさらにノード数規模やワークロードを拡大させた実証実験も行いながら、「最終的には、大規模なGPUクラスタを使いたいお客様に役立つものに仕上げたいと考えている」と述べた。
NTT Comでは、国内70拠点以上のデータセンター間を接続できる100GbpsのIOWN APNサービス「APN専用線プラン powered by IOWN」や、液冷方式に対応し1ラックあたり最大80kWの冷却能力を持つコロケーションサービス「Green Nexcenter」、顧客専有型のマネージドGPUサーバー環境「GPUプラットフォーム」などをすでに提供している。今回の技術をこれらのサービスに組み合わせた“GPUクラウドソリューション”の商用提供を目指す方針だ。
さらに、同技術を用いたソリューションを共創するパートナーも募り、AIのほか画像処理、大規模分散データ処理といった具体的なニーズも汲み取りながら、商用化を進めていきたいと話した。
なおNTT Comでは、10月10日と11日に開催する年次イベント「docomo business Forum '24」(会場:ザ・プリンス パークタワー東京)で、今回の「GPU over APN」実証結果を含むIOWN関連展示を行う。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



