



ロードマップでわかる!当世プロセッサー事情 第789回
切り捨てられた部門が再始動して作り上げたAmpereOne Hot Chips 2024で注目を浴びたオモシロCPU
2024年09月16日 12時00分更新

2023年にクラウド向けのAmpere Oneファミリーを発表
Ampere Alter/Alter MAXから3年あまり経過した2023年5月、Ampere ComputingはAmpere Oneファミリーを発表する。最大192コアの構成で、クラウドに最適化したカスタム構成と説明されていた。ただこの時点では、そういう製品が存在することだけがアナウンスされており、具体的な登場時期や詳細な構成などは一切明らかにされなかった。
2024年の5月にはアップデートが公開され、コア数は最大256まで増やされるとともに、QualcommのCloud AI 100 Ultraを組み合わせたAI推論向けのソリューションを提供することもアナウンスされたものの、詳細は引き続き明らかにされていない。
現実問題として2018年に一度X-Gene 4がご破算になり、そこから新規にCPUの設計をスタートすれば、5~6年かかるのはごく普通のことである。加えて言えば、Ampere Oneの最初のシリーズはTSMCの5nmを利用するが、ご存じの通りこのプロセスは大人気で、大口ユーザーはともかく会社規模としてはスタートアップ+αでしかない同社の優先度はどうしても下がるため、製造には時間を要するのも仕方がない。
それでもなんとか2024年8月には量産出荷を開始するとともに、今後のロードマップを開示した。
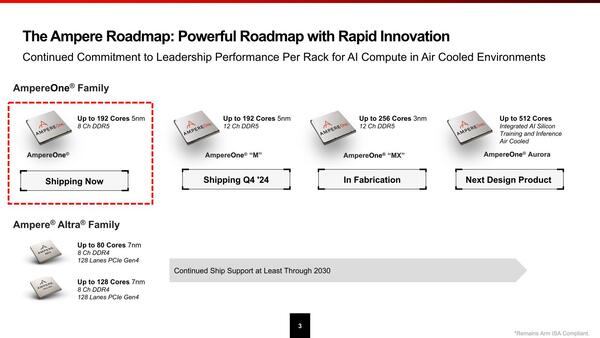
まずはメモリー8chのAmpereOne、次いでメモリーを12chにしたMバージョンとなり、256コアは3nmに移行した先ということは、早くて2025年後半だろうか?
そんなAmpereOne、まずコアの内部構造が下の画像である。
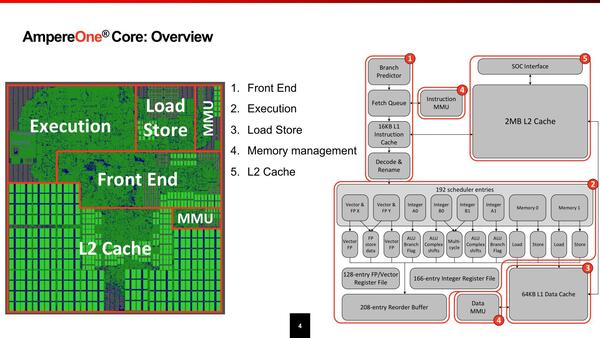
AmpereOneの内部構造。MMUとはなんだ? という話だが、これは単にTLB(Translation Lookaside Buffer)のことであった
基本的なAmpereOneの設計方針だが、絶対性能よりも性能/電力比やコア数に比例した性能、それと汎用性といったものを重視するとしており、これはインテルで言えばEコアベースのSierra Forestやその後継のClearwater Forestの方向性に近い。

おそらくX-Gene 4は左側の方向性を志向したコアだったのだろうな、と想像される。それはともかくハイパースレッディングはインテルの商標だった気がするのだが……
この思想はコアの内部構造にも反映されている。デコーダーは同時5命令で、これを4 MicroOpに変換してスケジューラーに送り込む格好だが、デコーダーそのものは最大で8命令/サイクルまで対応しているとする。
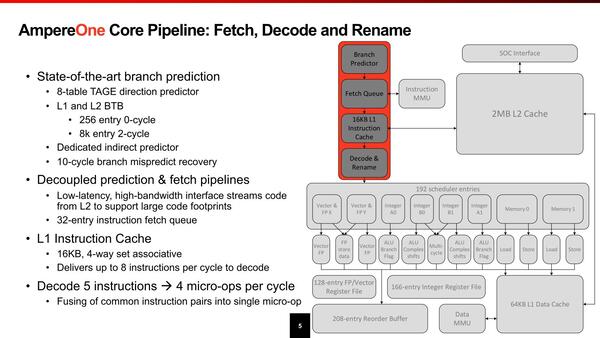
命令が減るのはMacro-Op Fusionを行なうからであるが、ただAArch32(32bit命令)はともかくAArch64(64bit命令)がそこまでMacro-op Fusionが効くのかやや疑問である
ここで性能を大幅に引き上げようと思ったらMicroOpキャッシュを設けるのが効果的だが、それをせずに32エントリーのフェッチキューのみで済ませているあたりは、AmpereOneのワークロードではMicroOpキャッシュが効くような処理はあまり多くないと考えているのかもしれない(API Server的な用途では、繰り返し処理の頻度が大幅に減るからMicroOpキャッシュが相対的に効きにくい)。
このあたりはピーク性能よりも性能消費電力比を重視して、あえてそこそこの性能に抑え、その分回路規模を小さくしたのかもしれない。
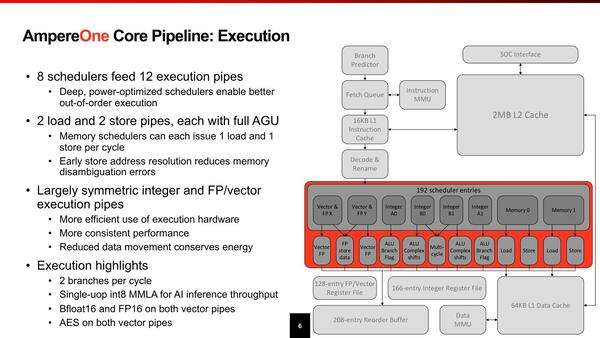
Multi-cycle(1サイクルで処理を完了できない命令向け)が別のユニットになっているのがおもしろい。つまり他の4つのALUは基本1サイクルで処理を終わらせる構成になっているわけだ
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






























