



CPUベースのスパコンにおけるLLM学習効率化の意義とは
富岳で学習した“純”国産LLMが、GitHub・Hugging Faceで無償公開
2024年05月13日 09時00分更新

東京工業大学、東北大学、名古屋大学、理化学研究所、富士通、サイバーエージェントおよびKotoba Technologiesからなる共同研究チームは、2024年5月10日、スーパーコンピューター「富岳」を用いて学習した、日本語能力に優れた大規模言語モデル(LLM)「Fugaku-LLM」を公開した。
Fugaku-LLMは、富岳で効率的にLLM学習するための研究成果として開発され、日本語を中心とした独自データで学習させた、130億パラメーターのLLM。開発者・研究者向けにGitHubでソースコードが、Hugging Faceでモデルが公開され、ライセンス内においては、商業および研究目的でも利用できる。
共同研究の全体統括を担った東京工業大学の学術国際情報センター 教授である横田理央氏は「海外製のGPUに頼らずに、国産のハードウェアで、さらに国産のモデルを一から開発した、純粋な国産LLMはFugaku-LLMが初めて。外国製のものに一切頼っていないことが大きな成果」と説明する。

東京工業大学 学術国際情報センター 教授 横田理央氏
共同研究の発端と体制
Fugaku-LLMの共同研究プロジェクトは、現在はKotoba TechnolgiesのCEOで、当時はコーネル大学の院生だった小島熙之氏らが、東北大学の坂口慶祐氏らに、富岳で何かできないかといと話を持ち掛けたことが発端となった。
2020年公開のOpenAIによる論文では、モデルのサイズ(パラメーター数)やデータセットのサイズ、トレーニングに使用される計算量を増やすと、より高い性能が発揮できるという「スケーリング則」が発表されている。「つまり、パラメーター数やデータセットを増やしていくだけで、費用対効果の“下限”が保証される。投資がしやすくて、失敗がない」と横田氏。
このように大きな投資がしやすいという背景のもと、国内で最も大きな計算資源として理化学研究所(理研)と富士通が共同開発したスーパーコンピューターである富岳に着目。2023年の6月より、富岳の政策対応枠において、本格的にプロジェクトが開始された。
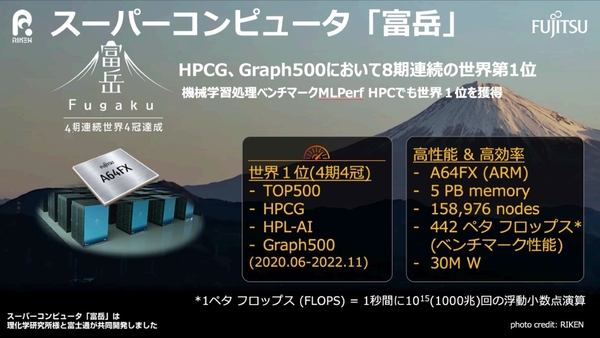
かつて4期連続で世界4冠を達成していたスーパーコンピューター「富岳」に着目した
共同研究チームは、東京工業大学 学術国際情報センターの横田氏の研究チーム、東北大学 大学院情報科学研究科の坂口慶祐氏、名古屋大学 大学院工学研究科の西口浩司氏および、発端となったKotoba Technologiesの小島氏が手を組んだ。さらに富岳側として理研のMohamed Wahib(モハメド・ワヒブ)氏や富士通 人工知能研究所の白幡晃一氏をはじめとしたチームも連携し、坂口氏の研究室に在籍していたサイバーエージェントの佐々木翔大氏も学習用データを提供している。
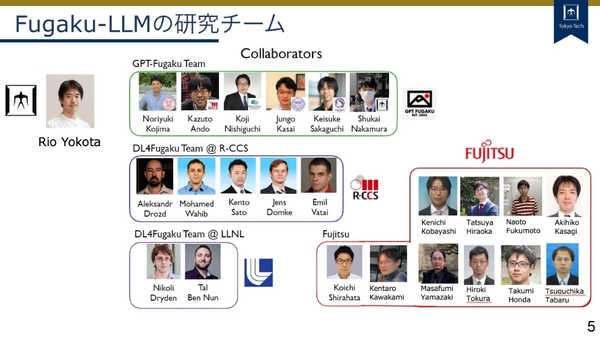
Fugaku-LLMの研究チーム
各機関、各企業の具体的な役割は以下のとおり。
東京工業大学:全体総括、大規模言語モデルの並列化および通信の高速化(3 種類の並列化を組み合わせた通信性能の最適化、Tofu インターコネクトD上での集団通信の高速化)
東北大学:学習用データの収集、学習モデルの選択
富士通:演算高速化と通信高速化(Tofu インターコネクトD上での集団通信の高速化、パイプライン並列の性能最適化)、事前学習と学習後のファインチューニング
理化学研究所:大規模言語モデルの分散並列化・通信の高速化(Tofu インターコネクトD 上での集団通信の高速化)
名古屋大学:3D 形状生成 AI への Fugaku-LLM の応用方法の検討
サイバーエージェント:学習用データの提供
Kotoba Technologies:深層学習フレームワークの「富岳」への移植
CPUベースの富岳で学習させたLLMを開発した意義とは
今回Fugaku-LLMを公開するに至って、大きく2つの研究成果が得られたという。
ひとつは、富岳のLLM学習における計算・通信の性能の向上だ。
通常はLLMの学習にはGPUが用いられるが、富岳はCPUベースであり、富士通製のA64FXという特殊なArmアーキテクチャーのCPUが用いられている。今回、深層学習フレームワークであるMegatron-DeepSpeedを富岳に移植することで、CPU上の行列演算ライブラリを高速化しており、従来で110秒かかっていた行列演算を18秒と、約6倍に高速化している。「この分野で6倍高速化するというのは非常に珍しい」(横田氏)。
またプロジェクトでは、分散処理した上で、富岳の1万3824台のノードを利用して計算していたため、ノード間での通信の高速化も試みた。富士通のインターコネクト技術である「TofuインターコネクトD」を最大限に活かせるよう、富岳向けに3種類の並列化を組み合わせて通信性能を最適化、従来の3倍となる通信速度を実現した。
CPUベースの富岳と、GPUを搭載する東京工業大学のスーパーコンピューター「TSUBAME4.0」との成果の比較について、「単純にノードあたりの性能で比較するのが適切かどうかわからないという前提で、CPUはGPUと比べると速度が出ないかもしれないが、今回、膨大に並列で使用する技術を用いたため、それを人間が使いこなすこともできるのではないか」と横田氏。
今回の共同研究における、LLM学習の計算・通信性能の向上は、世界中でGPUが不足している中で、今後の富岳上で実施されるプロジェクトに寄与するという。
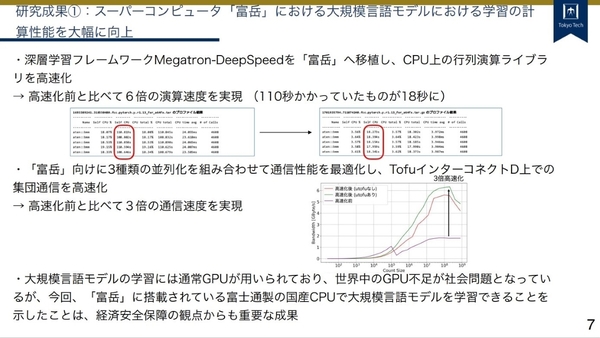
「富岳」におけるLLM学習の計算性能の向上
もうひとつの研究成果が、透明性や安全性を担保した上で、日本語性能に優れた130億パラメーターのLLMを開発したことだ。
Fugaku-LLMは、130億パラメーターのモデルを、一から独自のデータで学習しており、全学習工程が把握でき、透明性と安全性に優れているという。
学習においては、前述の通り1万3824台の計算ノードが用いられ、学習のデータ量は約4000億トークン、そのうち60%が日本語コンテンツになり、「国内の取り組みの中では、非常に大きい日本語データで学習していることが特徴」だという。
その成果もあり、Fugaku-LLMは、日本語性能に強く、Stability AIによるベンチマーク「Japanese MT-Bench」では平均スコアが5.5と、「国内の独自データで学習しているオープンなモデルにおいて最高性能」だという。GPT-4の平均スコアと比べると大きく劣るものの、人文社会系タスクではGPT-4を上回り、「日本語や日本文化に根差した会話などにおいて、活用が期待される」と横田氏。
また、LLMが日本語を処理するにあたっては、適切なトークナイザー(文章をトークンに分解する技術)を用いるのが重要で、英語に特化したLLMであると日本語の文字効率が悪く、今回の研究成果は、トークンあたりの課金でLLMを利用する際のコストを下げられるような可能性を秘めているという。

日本語性能に優れた130億パラメーターのLLMを開発、Japanese MT-Benchの平均スコアは5.5

Fugaku-LLMの回答のデモ(提供:富士通)
Fugaku-LLMは、世界中の開発者や研究者が、LLMの開発に活用できるように、GitHubにソースコードを、Hugging Faceにモデルを無償公開しており、研究および商用利用が可能なライセンスとなっている。さらに富士通も、同社の先端技術を無償で試せる「Fujitsu Research Portal」にてFugaku-LLMを提供開始した。
説明会にオンライン参加した理研の計算科学研究センター センター長である松岡聡氏は、「今回の技術はFugaku-LLMに閉じたものではなく、AIを用いて科学研究でイノベーションを進める『AI for Science』のプロジェクトにつながる、学習に関する大きな技術的な成果」だとコメント。
横田氏は、「開発したてで、どれだけの実力があるかは我々でも未知数。国内の技術でどこまでいけるのかを試したいため、是非皆さんに使用いただき、フィードバックをいただいた上で、どんどん良くしていきたい。国内でそういったサイクルを回していきたい」と述べた。

(左から)東京工業大学 学術国際情報センター 教授 横田理央氏、東北大学 大学院情報科学研究科 准教授 坂口慶祐氏、富士通 人工知能研究所 シニアプロジェクトディレクター 白幡晃一氏、理化学研究所 計算科学研究センター 高性能ビッグデータ研究チーム チームリーダー 佐藤賢斗氏、サイバーエージェント AI事業本部AI Lab リサーチサイエンティスト 佐々木翔大氏、Kotoba Technolgies CEO 小島熙之氏、名古屋大学 大学院工学研究科 准教授 西口浩司氏、(オンライン参加)理化学研究所 計算科学研究センター センター長 松岡聡氏
本記事はアフィリエイトプログラムによる収益を得ている場合があります







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")















