
第5世代TPU、独自Arm CPU、NVIDIA Blackwell搭載から「Vertex AI Agent Builder」まで
「生成AIはPoCから実践へ」Google Cloud Next '24で幅広い発表

Google Cloudが2024年4月10日、11日に米ラスベガスで年次イベント「Google Cloud Next '24」を開催した。昨年は“生成AIブーム”を受けて、その構想や戦略が語られた同イベントだが、今年は多くの顧客事例も紹介しながら、生成AIの「実装」と「活用」が進んでいることを印象付ける内容となった。
今年のGoogle Cloud Nextでは、AI処理への最適化をさらに進めた新インスタンスから、モデルの構築と運用サービスまで、幅広い発表が行われた。Google Cloud テクノロジー部門 統括技術本部長の寳野雄太氏が、現地で会期中の発表内容をまとめるセッションを行ったので、そのポイントを中心にまとめる。

キーノートに登壇したGoogle Cloud CEOのトーマス・クリアン(Thomas Kurian)氏

Google Cloud テクノロジー部門 統括技術本部長の寳野雄太氏
第5世代のTPU、Google初のArmベースカスタムCPUなど基盤を固める
Google Cloudは、世界40のリージョンを結ぶネットワーク(海底ケーブルを含む)、AIプラットフォームとAIモデルを基盤として、5つの領域(Data Cloud、Modern Infrastructure Cloud、Collaboration Cloud、Security Cloud、Developer Cloud)のサービスで構成される。今回の会期中には、日米間を結ぶ新たな太平洋海底ケーブルの構築に10億ドルを投じることを発表している。

Google Cloudが提供するサービス領域とその基盤技術。「AIプラットフォーム&モデル」も重要な基盤としてアピールしている
Google Cloudの生成AIポートフォリオの基盤となるのが、AI用途に適した形でハードウェアとソフトウェアを組み合わせたアーキテクチャ「AI Hypercomputing Architecture」だ。これにより、動的なリソース確保とコスト最適化、柔軟なユースケースの選択肢、高いパフォーマンスの実現を狙う。
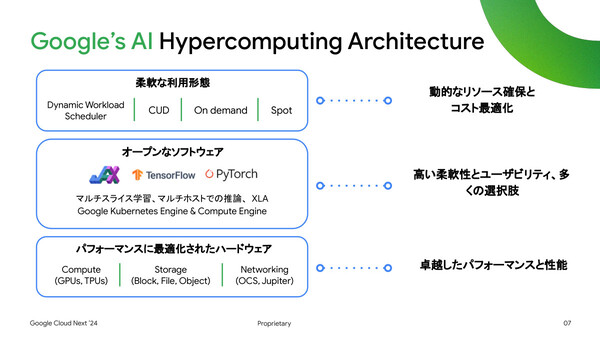
Google Cloudの「AI Hypercomputing Architecture」
上記アーキテクチャのハードウェアレイヤーでは、「NVIDIA H100 GPU」を利用できるA3インスタンスのマルチノードGPU間帯域幅を増強した「A3 Mega」インスタンスが投入される。そのスループットは1.6Tbpsと従来比(A3比)でおよそ2倍で、「複数のGPUノードで並列処理するLLM(大規模言語モデル)においてスループットは重要」だと寶野氏は説明した。6月から東京リージョンでも利用可能になることで、国産LLMを開発する企業には朗報になると見ている。
そのほか、Google Cloudの第5世代TPUとなる「TPU v5p」の一般提供開始(GA)や、H100をさらに大きく上回る性能を持つ次世代GPU「NVIDIA Blackwell」(B200、GB200)の2025年上旬からの提供開始予定なども発表された。

NVIDIA H100 GPUを搭載したA3仮想マシンの帯域幅を2倍に増強した「A3 Mega」の一般提供を開始

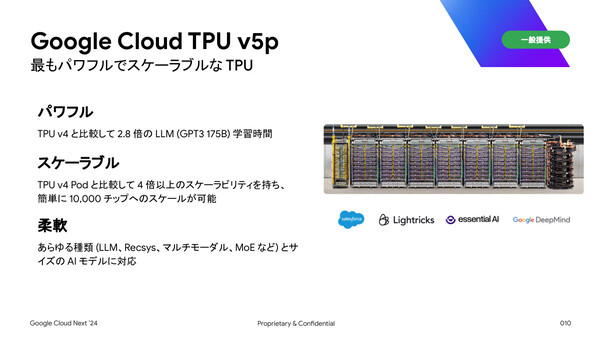
Google自身が開発する機械学習専用プロセッサの最新版「TPU v5p」を一般提供開始、NVIDIAの次世代GPU「Blackwell」の登場予定も発表
さらに今回、Google Cloud CEOのトーマス・クリアン氏が大々的に発表したのが、Google初のArmベースカスタムCPUである「Google Axion」だ。クリアン氏は、Axionでは「Googleのシリコンに関する専門知識と、Armによる最新のコンピュートコアデザインを組み合わせた」と述べ、パブリッククラウド市場で現在提供されている最速のArmベースインスタンス比で30%の性能向上、現行世代のx86インスタンス比で50%の性能向上、さらに最大60%の電力効率向上が実現すると紹介した。また、既存のArmベースインスタンス比でも30%の性能向上が実現しているという。このAxionは、すでに「BigQuery」や「Spanner」といった同社のサービスインフラで使われているという。

Googleで初めてとなるArmアーキテクチャのカスタムCPU「Google Axion」を発表
そのほか寳野氏は、需要の高騰によりGPUリソースの確保が困難になっている課題を解消する「Dynamic Workload Scheduler」(一般提供開始)、インテルのDAOS(分散型非同期オブジェクト・ストレージ)をベースとする低遅延の並列ファイルシステム「Parallelstore」(パブリックプレビュー)、高パフォーマンスの「Hyperdisk」を最大2500インスタンスでマウント可能(Read Only)にして機械学習ワークロードに最適化したブロックストレージ「Hyperdisk ML」といった、新たなサービスも紹介した。

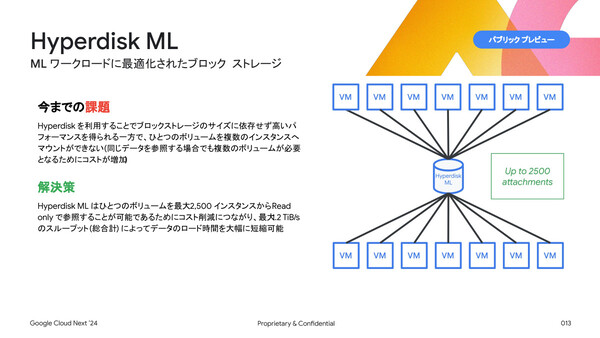
GPUリソース確保の課題、機械学習ワークロードにおけるブロックストレージの効率性の課題を解消するサービスも
またアプリケーション開発の領域では、生成AIがコーディングを支援する「Gemini Code Assist」の新機能として「Repository-wide Context」(プライベートプレビュー)を紹介した。最大100万トークンをサポートするGoogleのマルチモーダルモデル「Gemini 1.5 Pro」を活用し、コードリポジトリ全体のコンテキストを考慮したうえでコーディングをアシストするという。寶野氏は「開発者の生産性が上がる、かなり革命的な機能」だと述べた。