



エンタープライズが活用しやすい生成AIの実現に向けて、資金面/技術面でOracleが支援
Oracleの生成AI戦略の切り札? Cohere共同創業者が技術の優位性を説明
2023年10月31日 08時00分更新


生成AI技術の活用に向けてITベンダー各社が戦略を打ち出す中、OracleはエンタープライズAIプラットフォーム開発を手がけるCohere(コヒアー)への投資と提携を発表した。この提携がOracleにどのようなメリットをもたらすのかを理解するためには、Cohereを理解する必要がある。
Oracleが9月に米ラスベガスで開催した「Oracle CloudWorld 2023」では、Oracleのミッションクリティカルデータベーステクノロジー担当EVPのホアン・ロアイザ氏が、Cohereの創業者兼CEOのエイダン・ゴメス氏と対談した。本記事ではその内容をまとめる。

Cohereの共同創業者兼CEOのエイダン・ゴメス(Aidan Gomez)氏(左)。Oracle ミッションクリティカルデータベーステクノロジー担当EVPのホアン・ロアイザ(Juan Loaiza)氏は、ゴメス氏を「生成AIの魔法を発明した一人」と紹介した
Oracleが資金面と技術面で支援、生成AIサービスをOCI上で展開へ
データベース(以下、DB)領域の基調講演においてロアイザ氏は、生成AIの能力を拡張する「RAG(Retrieval Augmented Generation)」の重要性を強調した(RAGについてはこちらの記事を参照いただきたい)。
その流れでロアイザ氏が紹介したのが、Transformerモデルを発表した論文「Attention Is All You Need」である。2017年に発表されたこの論文は、現在の生成AIブームの土台となるニューラルネットアーキテクチャが生まれるきっかけとなったと、ロアイザ氏はそのインパクトを説明する。
同論文を執筆したのは、Google Brain(GoogleのAIリサーチラボ)の当時のメンバー。そのうちゴメス氏ともう1名(ニック・フロスト氏)が2019年にカナダで立ち上げたのが、Cohereだ。同社は、ディープラーニングの研究者でチューリング賞受賞者であるジェフリー・ヒントン氏、一時期Googleに出向していたフェイフェイ・リ氏などの支援を受けたことなどから、すぐに業界の話題となった。
Oracleは、Cohereが2023年6月に行ったシリーズC投資ラウンドにおいて、NVIDIAやSalesforceなどとともに参加した。この投資ラウンドでCohereが調達した額は2億7000万ドル。さらにOracleは技術面でもCohereを支援しており、Cohereは「Oracle Cloud Infrastructure(OCI)」独自のGPUクラスタ「OCI Supercluster」を用いて生成AIモデルのトレーニング、構築、デプロイを行っている。今後、Cohereの生成AIサービスはOCIをプラットフォームとして提供される見込みだ。
“エンタープライズ向けの”AIに求められる技術とは
ロアイザ氏に招かれてステージに登場したゴメス氏は、Cohereを起業した理由について「開発者と企業が活用できる、未来の言語AIを創りたいと考えた」と説明する。
Cohereでは一般的な生成AIモデル(LLM)と、Embedモデル(Embeddingモデル)という2種類のモデルを開発している。Embeddingは、テキストデータ(単語や文、文章)を数値ベクトルに変換する手法であり、その結果は「Oracle Database 23c」のようなベクトルDBに格納される。これによりテキストどうしの類似性や関連性が判断できるようになり、たとえばセマンティック検索や類似ドキュメントのレコメンドといった機能が実現できるようになる。CohereのEmbedモデルは現在、100以上の言語に対応している。
CohereではEmbeddingモデルも開発している(画像はCohere Webサイトより)
ゴメス氏は、EmbedモデルとベクトルDBを併用することで、LLMの「知識の拡張」が容易になると説明する。大量の研究論文や製品ドキュメント、コンタクトセンターのナレッジベースなど、テキストデータをベクトル化してDBに格納し、LLMから参照可能にすることでRAGが実現する。「AIモデルが人に代わってリサーチし、情報をまとめ、抽出、要約し、検証可能な回答を返すことができる」(ゴメス氏)。
生成AIの活用にあたっては「ハルシネーション」の課題が指摘されているが、その課題解決において「最も有望な解決策がRAGだ」とゴメス氏は説明する。なぜならば、この方法であればLLMが回答の際に、根拠(情報源)としたドキュメントを明示できるからだ。「LLMの回答をそのまま鵜呑みにしなくてもよくなるので、企業でも信頼して使うことができる」(ゴメス氏)。

Cohere ゴメス氏
さらにRAGであれば、自社固有の機微情報や知的財産、顧客情報といったプロプライエタリなデータも安全に活用できる。「企業が持つ情報すべてを活用できるようになるので、総じてユーザーが利用しやすいものになるだろう」とゴメス氏は結論づける。
ロアイザ氏が、自社のドキュメントでLLMをトレーニングする方法とRAGによる拡張との違いを尋ねると、ゴメス氏は「トレーニングはモデルの“性格付け”にはたけているが、新たな知識を加えることは苦手だ」と説明した。一方で、LLMの外部にあるDBを参照するRAGの場合は、いつでも最新の情報にアクセスできる。ロアイザ氏は「この違いは重要だ。したがって、RAGは今後のDB分野でも重要な技術になる」と述べた。
最新のEmbedモデルを紹介、ノイズの多いデータでも高品質な処理
ゴメス氏はCohereの取り組みとして、最新のEmbedモデルを紹介した。この最新モデルでは、多様なデータソースから収集した“ノイズの多い”データセットに対しても、より高品質な結果が得られるという。「Cohereの最新Embedモデルでは、ノイズの多いデータセットにおいて、他社モデルの2倍の品質評価を得られた」と胸を張る。
ゴメス氏によると“クリーンなデータセット”が手に入ることはまれだ。PDFドキュメントやEメールをスクレイピングしてデータを取り出そうとしても、フォーマットのエラーなどにより、ノイズが混じるケースが多い。そこでCohereでは、トレーニングの一環として情報をまとめることを行った。これにより「データベースの構造やフォーマットが異なり、ノイズが多く入っても、かなり正確な結果を得ることができる」という。
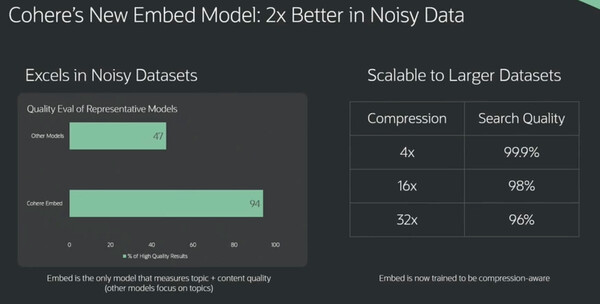
Cohereの最新Embedモデルは“ノイジーな”データセットでも高品質な結果が得られる。さらに、モデルサイズの圧縮率を32倍にしても96%の精度を維持しており、これは高速な回答やリソースコストの削減につながるという
こうしたOracleの動きについて、Constellation ResearchのVPで主席アナリスト、ホルガー・ミューラー(Holger Mueller)氏は、「現在のOracleはその歴史において最大規模の投資を行っており、その大半はクラウドに充てられている」と述べる。
「そして、AI領域における大きな投資がCohereだ。Cohereは効果の高いモデルを持ち、生成AIプラットフォーム分野では好位置にある。OracleのCohereへの投資は、顧客のメリットという点で賢明な判断と言える」(ミューラー氏)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
クラウド
「Oracle Database@Azure」発表、オラクルとMSのマルチクラウド協業が深化 -
クラウド
オラクルが企業向け生成AI発表、OCI“スーパークラスタ”の強みをアピール -
クラウド
「統合」と「分散」、オラクルが掲げるクラウド戦略とOCI新発表まとめ -
クラウド
生成AI時代の「Oracle DB 23c」はどう変わったか、OCWで新機能発表 - この連載の一覧へ



