




今回でMeteor Lakeの話はいったん終了である。残るのはGPUとSoCまわりとなる。まずはGPUから説明しよう。
Xe-LPGはXe LPの強化版?
Xe LPと比較して2倍の性能と言うけれど……
Meteor Lakeに搭載されるGPUはXe-LPGとなる。Raptor LakeまでのGPUはXe LPベースであり、その意味では新アーキテクチャーの搭載になる。
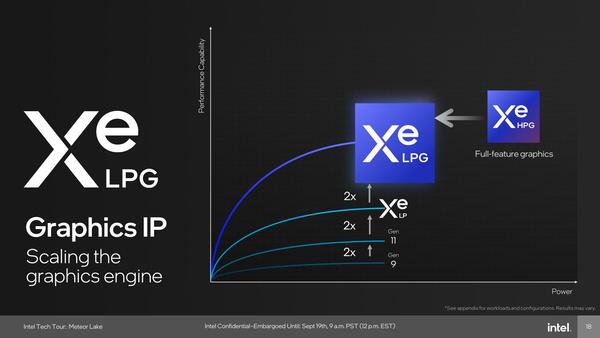
Meteor Lakeに搭載されるGPUのXe-LPG。Xe LPと比較して2倍の性能というのは嘘ではないが、正確でもない。このあたりは後述する
Xe LPGは連載579回のロードマップには存在しない。構造的にはXe LPの強化版というよりはXe HPGの低消費電力向けという扱いになるかと思われるのだが、インテル的にはXe LPの強化版という説明の仕方をしている。
2020年9月のインテル GPUロードマップ。Xe LPGは存在しない
Xe LPとXe LPGの違いは、以下の3つが挙げられている。
- より高い動作周波数での駆動
- より規模の大きな構成が可能
- アーキテクチャー的な効率向上
まず動作周波数が下の画像で、同じ動作周波数ならより低い電圧で動作するし、同じ電圧ならはるかに高い動作周波数まで稼働するとしている。

横軸はおそらくXe LPを1.5GHz駆動で動かす際のGPU Voltageを1.0とした時の相対値で、電圧の絶対値ではないと思われる
リファレンスになるのはRaptor Lakeあたりだろうから、例えば「Core i9-13900HK」を例に取ると、GPUは最大1.5GHz駆動である。ここから考えると、Xe LPGでは最大2GHz位まで動作周波数を引き上げ可能(実際に2GHzまで行くかどうかは不明)だし、ベースとなる1GHzであれば電圧を0.78倍に落とせるので、それだけ省電力になる可能性が高い。ちなみにこれはアーキテクチャー云々というよりも、Intel 7を使うXe LPとTSMC N5を使うXe LPGの違いだと思われる。
次が構成そのものの大型化である。従来のXe LPは最大でも96EU構成であったが、Xe LPGでは128EU構成(Xe LPGの用語なら128XVE)まで拡大できるとしている。EUの中身はこの後説明するとして、EU数で1.33倍、ジオメトリー・パイプラインが2倍、サンプリング/ピクセル バックエンドがそれぞれ1.33倍、そして従来は未サポートだったレイトレーシング・ユニットを搭載している。

数字はXe LP比。従来は2つのコアで1つのレンダースライスを構成、これが3つという形だった
レンダースライスの数で言えば3分の2になる計算だが、個々のレンダースライスの性能が大きく上がっている。大規模なGPUであれば、複数のタスクを並行して動かす場合の粒度が下がるので不効率という可能性もあるが、このクラスのGPUであればこれによるデメリットはないと考えていいだろう。
最後がアーキテクチャーそのものである。Xeコアの構造は下の画像のとおり。1つのXeコアに16個のXVE(Vector Engine)とロード/ストアー・ユニット、それとキャッシュが搭載される。

Xeコアの構造。1つ前の画像を見ると、Xeコアの下にThread Sorting UnitとRay Tracing Unitが並び、さらにその下のバックエンドのブロックにSamplerなどが配されているのがわかる
Xe LPの場合と比較すると、サンプラー/メディアサンプラーがXe Coreの外に追いやられている。ではそのXe LPGのXVEは? というのが下の画像だ。

Xe LPGのXVE。スレッド制御は2つのXVEに跨る形で配されているのはXe LPやXeと同じ
Xe LPのEUの構成は連載579回で示したとおり以下の構成だった。
- INT/FP共用となる8-wideのVector SIMDが搭載
- INT8でDP4Aにも対応
それに対し、XVEでは以下のようになっている。
- INT/FPそれぞれ別に8-wideのVector SIMDが搭載
- FP64のEngineも搭載
- EM(Extended Math)の数は変わらず
このINTとFPのVector SIMDは同時に実行が可能であり、絶対的な演算性能で言えばXe LPGのXVEはXe LPのEU比で2倍の処理性能を誇ることになる。記事冒頭の画像に出てきた2倍というのはこのことで、確かに嘘ではない。
嘘ではないのだが、INTとFPを同時に動かすという状況がどの程度あるのかという疑問は当然出てくる。常時こうした処理があれば、確かに実効性能は2倍になるだろうが、INTのみやFPのみであれば実効性能は変わらないからだ。
また新たにFP64の演算器が搭載されたのも目新しいが、これはHPC用途向けならともかく、Xe LPGにわざわざ搭載した理由が思いつかない。科学技術計算をやらせる(Meteor Lakeをモバイル・ワークステーション的な用途で使う)ケースはあるだろうから無意味ではないが。
XVE数は128なのでFP64では128Flops(MAC演算が可能なら256Flops)。1GHzなら256GFlops、2GHzで512GFlopsになるので、CPU側でAVX256(FP64で最大16Flops/サイクル、Pコアが最大5GHzで動いたとしても80GFlops)を使うよりはるかに高速ではあるのだが、ローパワー向けのGPUにしてはやや無駄な気もしなくはない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































