




Meteor Lakeのパターン形成はEUVではなく
ArF+液浸のSAQPを使っている公算が高い
今回基調講演そのものではあまりプロセスに関しては新しい話はない。ただすでにIntel 3のサンプリングが開始されていることが公開されたのと、Intel 18Aに関してHigh-NAのステッパーが導入されるのが改めて明言された。

Intel 4は“High-volume ramp”という微妙な表現になっている
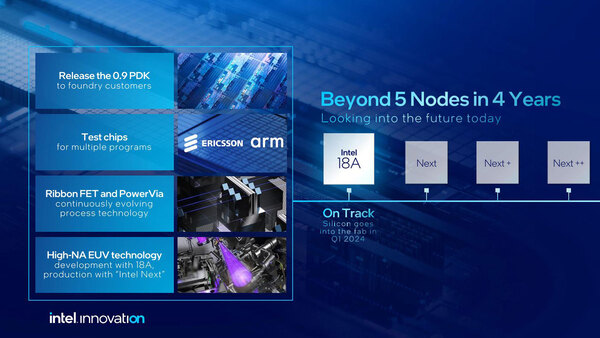
2024年の第1四半期中にIntel 18Aの試作をスタートすることも明らかにされた
High NAのステッパーは連載626回で触れたが、現在のEUVステッパーはNA(開口値)が0.33であり、これでは解像度が13nmほどになるというのは連載718回で説明した。
High-NAはこの開口値を0.55まで高めた機種で、これなら解像度が8nmあたりまで短縮できるのだが、スケジュール的にIntel 18Aには間に合わないと見られていた。
今回の発表は、Intel 18Aを使ってこのHigh-NAのステッパーを導入し(これは量産ラインではなく、開発ラインでIntel 18AをHigh-NAで行なうことで習熟や調整などをする)、量産に使うのはIntel 18Aの次のプロセスになることが明らかにされた。
基調講演で判明したのはこの程度であるが、このタイミングでMeteor Lakeの詳細が公開された。その中にはIntel 4プロセスに関する話も含まれている。とは言っても、ほとんどの内容は連載675回で説明した、2022年のVLSI Symposiumの内容と同じである。
ただ今回新たに公開された最大のインパクトのあるスライドが下の画像である。
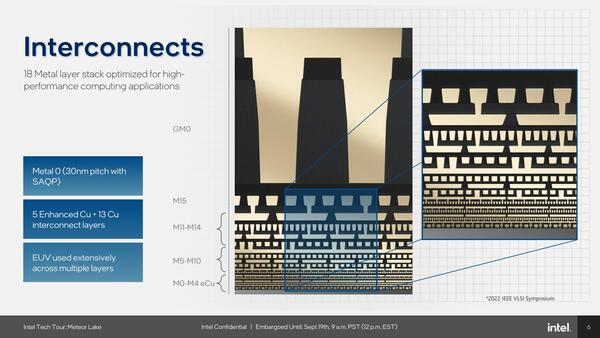
M0は30nmピッチである
一般論として、EUV(極端紫外線)はArF(アルゴン・フッ素)+液浸のマルチパターニングで製造する中で、一番重要な部分に適用される。Intel 7とIntel 4のデザインルールは連載675回で説明した下表のとおりで、M5以上はそもそもEUVを使わなくてもArF+液浸のダブルパターニングで対応できる。
| Intel 7とIntel 4のデザインルール | ||||||
|---|---|---|---|---|---|---|
| ピッチ | 用途 | |||||
| 30nm | フィン、M0 | |||||
| 45nm | M2/M4 | |||||
| 50nm | M1/M3 | |||||
| 60nm | M5/M6 | |||||
| 83nm | M7/M8 | |||||
問題なのはM4以下、特にFin/M0の30nmピッチの部分で、ここは当然ArF+液浸のSAQPをEUVに置き換えるものと考えられていた。ところがM0のパターン形成はSAQPのままであることが明らかにされた。M0のパターン形成がArF+液浸のSAQPということは、フィンに関しても形成そのものは引き続きArF+液浸のSAQPを使っている公算が高い。
では一体インテルはEUVをどこに使っているのか? であるが、“EUV used extensively across multiple layers”(EUVは複数の層で広範に使われている)という但し書きがあるので、使っていないわけではない。
実際、連載734回に出てきたWilliam Grimm氏も、複数の層でEUVを利用していると説明していた。
ここから考えられる一番合理的な方法は「インテルは(おそらくフィンやM0を含む)複数の層の特定用途向けにEUVを限定的に使っている」である。例えばパターンのカット。SAQPでのパターン生成の方法は連載483回で説明しているが、SAQPだとかならず配線が4本単位で並ぶことになる。ただこれでは無駄に配線が伸びる場所があるので、必要に応じて(SAQPで形成されたパターンを)切る必要がある。
これをSAQPでやるのはものすごく面倒くさいのだが、EUVなら比較的容易にできる。SAQPと違って一ヵ所だけを切るパターン形成が楽だからだ。同様にVIA(貫通配線)のための穴あけも容易である。
インテルは下の画像を出してあたかも「パターン形成そのものにEUVを使っている」ように誤解させているが、実際はパターン形成そのものは引き続きArF+液浸のSAQPを使っていたわけだ。

たしかにパターン形成に使えば大幅にマスク(とステップ)数を減らせるが、これは一般的な話でしかなかった
理由はいくつか考えられる。パターン形成にまでEUVをフルに使おうとすると、ステッパーの台数をかなり確保しないといけないが、そもそも現在量産しているオレゴンのD1はIntel 4の量産以外にIntel 3/20/18Aの開発にもEUVステッパーを使うので、そんなに多数の台数を割り当てられない。
またEUVステッパーは消費電力がArF+液浸よりも圧倒的に大きいので、SAQPにすることで露光回数が増えることを加味しても、まだEUVを使う方がプロセスコスト(≒消費電力)が圧倒的に大きい。つまり製造コストが高コストになる。
EUVプロセスの歩留まりがどの程度かは不明であるが、普通立ち上がりのプロセスではいろいろと難しいためどうしても低めになる。ということは、EUVでの処理を増やせば増やすほど、最終的な歩留まりが下がることになる。歩留まりを高めに維持したければ、本末転倒な気はするがEUVで処理する工程を減らすのは合理的である。
おそらくインテルとしては最初のEUVプロセスだけに、かなり保守的に使う方法を選んだのだろう。あるいはIntel 3ではもう少し使う範囲が増えるかもしれないが、Intel 4に関してはEUVを利用しているのは10工程未満な気がする。
フィンとM0/M2/M4の比較的重要な部分のパターンカットとVIA形成程度で、あとはArF+液浸のSAQPのままがんばっている結果として、製品の高い歩留まりが確保できたというあたりであろう。というわけで、次回はMeteor Lakeの情報をお届けしたい。
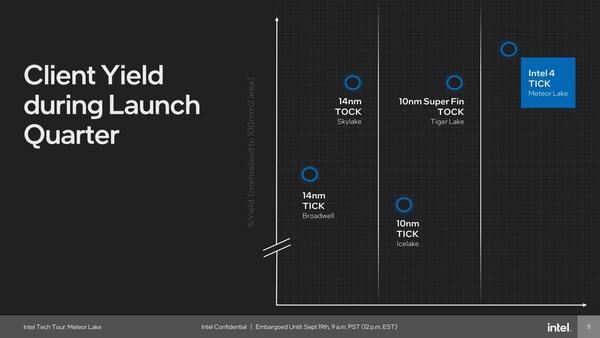
これも“Intel 4 Process”の歩留まりなのか、それともMeteor Lakeという最終的な製品の歩留まりなのかが不明である。後者だとすると、それはCPU/GPU/IO/SoC/Baseという5つのタイルの良品を、Foverosを使って3D実装した際の歩留まりになる気がするのだが……
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























