



オブジェクトストレージにある数百TBデータも分散並列処理で高速分析可能に、他社性能比較も公開
RDBに匹敵するクエリ性能、「MySQL HeatWave Lakehouse」一般提供開始
2023年07月27日 07時00分更新

日本オラクルは2023年7月26日、オブジェクトストレージ上の大規模なデータに対してSQL文で高速な分析処理を実行できるデータレイクハウスサービス「MySQL HeatWave Lakehouse」の一般提供開始を発表した。
最大512ノードのHeatWaveクラスタを使った分散並列処理によって、高速なクエリ処理を実現。オラクルによるベンチマークテストでは、リレーショナルデータベース(RDB)と同等のクエリ性能を記録している。同日行われた記者向けの説明会では、その特徴や「Amazon Redshift」「Snowflake」「Google BigQuery」といった競合サービスとのベンチマーク性能比較も紹介した。
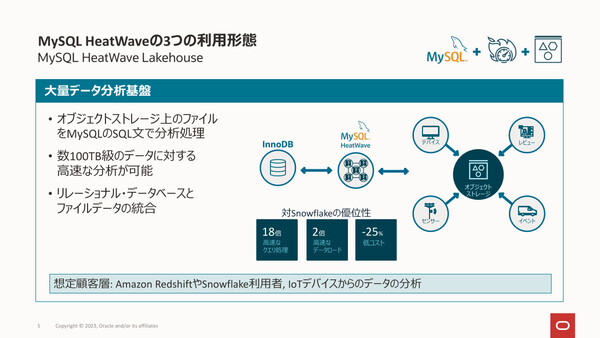
「MySQL HeatWave Lakehouse」の概要。オブジェクトストレージにある数百TBクラスの大規模データも高速な分析を可能にする

日本オラクル MySQLグローバルビジネスユニット APAC&日本 MySQLソリューションエンジニアリングディレクターの梶山隆輔氏
半構造化/非構造化データもまとめて分析したい企業ニーズに対応
MySQL HeatWaveは、インメモリ/カラム型アーキテクチャをベースとした分析クエリ処理(OLAP)高速化のためのアクセラレーターだ。これまではクラウドデータベースサービス「MySQL HeatWave Database Service」において、RDBにあるデータの分析処理を高速化する目的で提供されてきた。また、MySQL上でRDBのデータとHeatWaveクラスタを使って機械学習(ML)処理を実行する「HeatWave ML」も提供している。
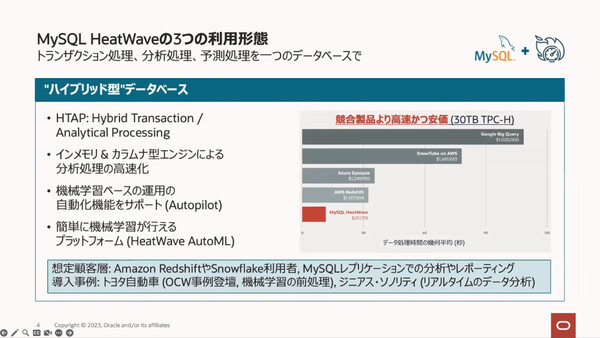
これまでのHeatWaveの適用先。RDBにあるデータの分析/予測処理を高速実行する
今回一般提供を開始したHeatWave Lakehouseは、その適用先をオブジェクトストレージにある大規模データにまで拡大するものだ。
日本オラクルの梶山隆輔氏は、新たにデータレイクハウスサービスを提供する背景として、企業でデータ活用ニーズが高まる一方で、そこで扱われるデータの種類や構造の複雑さが増している点を指摘する。RDBに格納されている構造化データだけでなく、たとえばセンサーから取得したCSVデータなども統合して分析したい、というニーズが高まっているという。
「自社が持つ『すべてのデータ』を活用してイノベーションを起こしていこうという流れがあるものの、構造化/半構造化/非構造化と構造が異なるすべてのデータをまとめて分析するのは、なかなか一筋縄ではいかない。そこで、従来型のデータウェアハウスと、オブジェクトストレージに多様なファイルを置いておくデータレイクの2つを融合した、データレイクハウスが市場に登場している。今回の発表は、ここにMySQLとしても対応していくというものだ」(梶山氏)
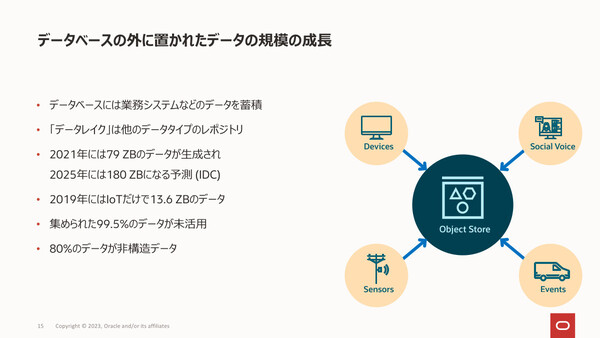
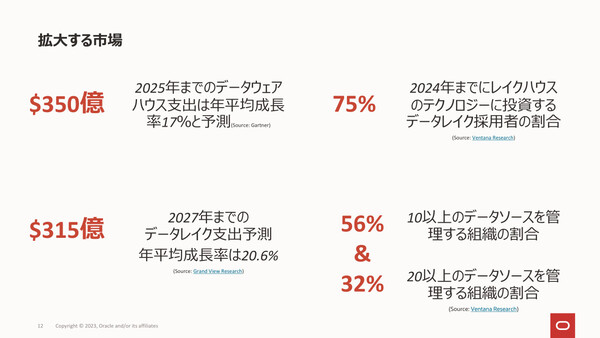
企業が望む「あらゆるタイプのデータの分析」を実現するために、データレイクハウスが登場した。今後大きな市場成長が予想されている
高いスケール性能、RDBとの統合、自動化などの特徴
MySQL HeatWave Lakehouseの特徴として梶山氏は、「高い柔軟性と拡張性を持つスケールアウトアーキテクチャ」「MySQL(InnoDB)とオブジェクトストレージのデータをひとまとめに分析可能」「Autopilot機能によるプロビジョニングなどの自動化」を紹介した。
HeatWave Lakehouseでは、オブジェクトストレージにあるデータ(CSV、Parquetなど)をHeatWaveクラスタにロードし、分散並列処理を行うことで処理を高速化する。クラスタは最大512ノードまでスケールし、1ノードあたり最大1TBのデータをロードすることが可能。クラスタのサイズはリアルタイムにスケールアウト/スケールインが可能であり、その処理に応じてデータの自動再配置も行われる。データロード性能や処理性能は、クラスタのサイズに応じてほぼリニアにスケールするという。

HeatWave Lakehouseはスケール性能の高さが特徴
データの容量に応じて最適なクラスタサイズ(ノード台数やメモリ容量)を推奨してくれる自動プロビジョニングの機能も提供される。これにより、実行時のメモリ不足を回避し、コストも抑えながらプロビジョニングにかかる時間(データをロードし起動するまでの時間)を改善できるという。なお、これはあくまでも推奨値なので「コストを度外視して性能を出したい場合は、推奨値よりノード数を増やすことも可能だ」(梶山氏)。
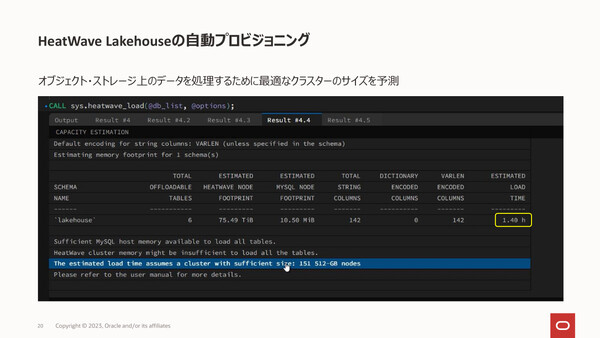
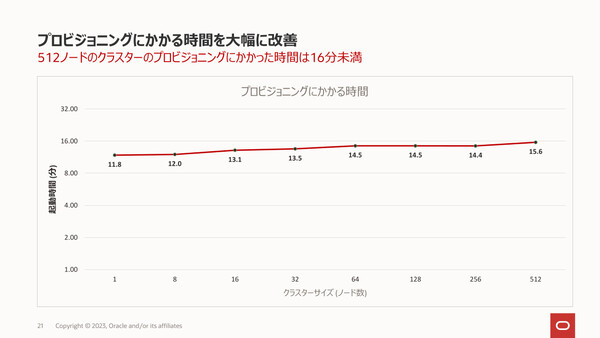
最適なクラスタサイズを推奨してくれる自動プロビジョニング機能を備える。データロードも分散並列処理を行うため、ノード数が増えてもプロビジョニング時間はほぼ延びない
また、HeatWave LakehouseのインタフェースはMySQLであり、InnoDBにあるデータとオブジェクトストレージのデータ(CSV、Parquetなど)をSQL文でひとまとめに分析できる。「たとえば従来型のInnoDBのテーブルと、オブジェクトストレージのデータから生成したテーブルをJOINして結果を得るような、そういった使い方もできる」(梶山氏)。
なおこのとき、AutopilotがDDL(データ定義)を自動生成したり、スキーマ情報を含まないデータ(CSVなど)のスキーマを自動予測したりするため容易に利用でき、さらにクエリの実行計画を自動改善して処理を高速化する技術も組み込まれているという。

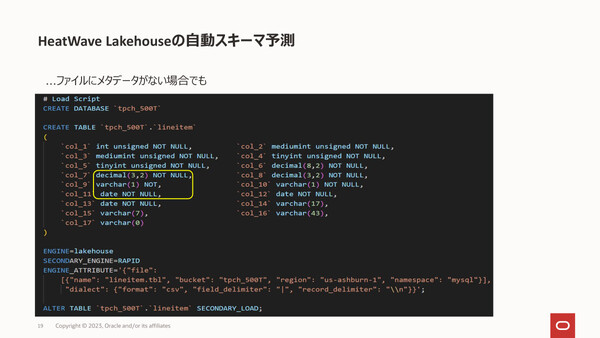
機械学習ベースのAutopilotが各種操作を自動化するため、不慣れでも使いやすい
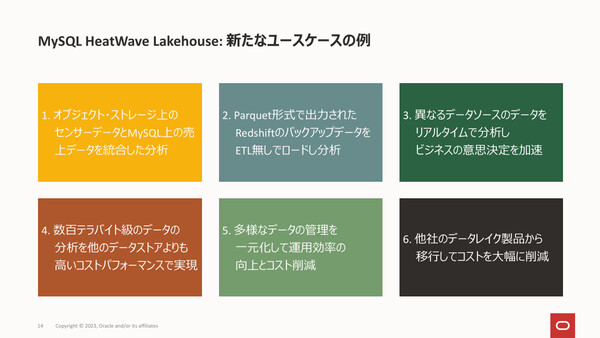
MySQL HeatWave Lakehouseのユースケース例
競合比較のベンチマークテスト結果を公開、競争力のある価格設定も
梶山氏は、ベンチマークテストに基づく他社競合サービスとの性能比較結果についても紹介した。500TBのデータを用いてデータウェアハウス性能を測るベンチマーク(TPC-H 500TB)を実行した結果、データロード性能ではAmazon Redshiftの9.2倍、Snowflakeの2倍、BigQueryの8.6倍高速だった。さらに、同じベンチマークでのクエリ実行性能はAmazon Redshiftの15倍、Snowflakeの18倍、BigQueryの35倍高速だったとしている(ベンチマークテストの実行条件詳細やコードなどはWebサイトで公開している)。
TPC-Hベンチマークについてはもうひとつ、オブジェクトストレージからロードしたデータのクエリ処理が、MySQLからロードしたデータのクエリと同性能で処理できたことも強調した。
そのほか梶山氏は年間コストについても競合サービスと比較し、性能差をふまえて「コスト的にも競争力のある価格設定をしている」と述べた。
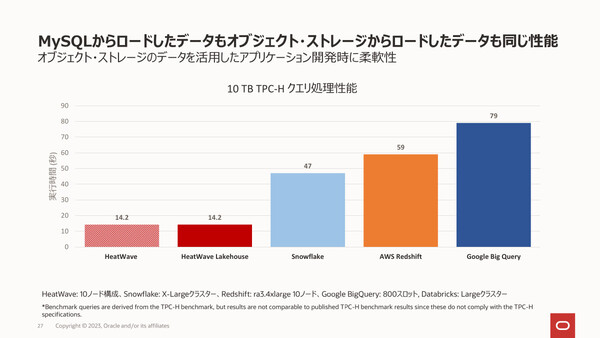
10TBのデータを用いたTPC-Hベンチマークの結果(クエリ処理性能)。Heatwave Lakehouseの処理時間はHeatwaveのそれと同等だった
本記事はアフィリエイトプログラムによる収益を得ている場合があります



