



ロードマップでわかる!当世プロセッサー事情 第721回
性能ではなく効率を上げる方向に舵を切ったTensilica AI Platform AIプロセッサーの昨今
2023年05月29日 12時00分更新

AI向けに最適化したDNA Scalable Processor
ということで話をAIプロセッサーに移す。AI市場の盛り上がりに合わせて、当然TensilicaもAI向けの対応を始める。といっても当初畳み込みニューラルネットワークが映像処理(セグメンテーションやクラシフィケーションなど)で立ち上がったこともあり、まずは同社のVision Q6という映像処理向けのDSP上でニューラルネットワークを稼働させるためのフレームワークを提供するに留まっている。

これは2018年のLinley Spring Processor Conferenceにおけるスライド。この時の発表のメインは13段のパイプライン構造を持つVision Q6 DSPであり、そのうえで新たに用意されたXtensa Neural Network Compilerを利用することで既存のニューラルネットワークを稼働させられる、というもの
2019年にはTensilica DNA 100 Processor(数百個のDSPコアをSoC内に搭載できるというコンセプトのもの)を発表しているが、DSPコアそのものは従来のままで、まだAIに最適化されたというものではなかった。このあたりのソリューションが用意できたのは2020年である。
DNA Scalable Processorと呼ばれる新IPは、DSPをベースとしつつもAI向けに最適化した構造を取るものである。

このころのTensilica AIは最大2048MACユニットまで拡張することを想定していた
中核になるのはXNNE(Xtensa Neural Network Engine)で、MACユニットそのものはVision DSPなどと似ている(完全に同じではなく、AI向けのデータ型のサポートなどが追加されている)が、これにSparsityへの対応を行ったScalable Sparse Compute Engineや、量子化専用ユニットの追加(DSPでも同じことはできるが、それだけ演算性能を食うことになるので、専用ユニットにすることで効率を上げている)などを実装したものだ。
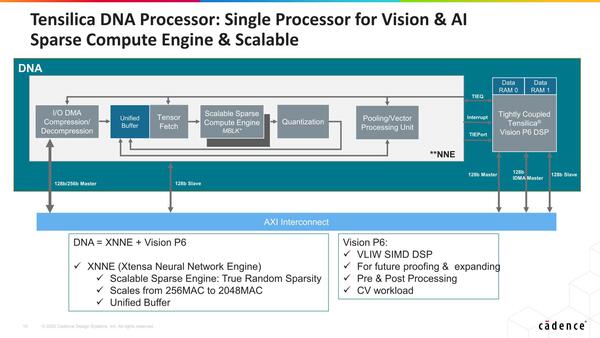
Vision P6 DSPと密結合してるとは言うものの、「将来の拡張用」「プレ/ポストプロセス」などで、AI処理はXNNEの方でほぼ完結することになる
基本はDSPをブン回して性能を上げるという方向での実装であり、データフローの実装やIn-Memory Computing的な実装は同社の得意とするところではない。
ただScalable Sparse Compute Engineでデータが疎の部分の演算は自動的にパスできるからデータフローに近い効率を実現できるし、Unified BufferをMACユニットに近いところに置くことで、外部のメモリーアクセスの頻度を減らすことで本当のIn-Memory Computingに比べればまだ帯域的には低いであろうものの、かなり効率的に演算を実施できるように配慮したことがうかがえる。
性能としては、この時点でもNVIDIAのXavierと比較して2.4倍の効率を達成したとしており、手始めとしては悪くない数字である。

比較はMobilenet V1での結果とのこと。それはいいが、比較がTOPSあたりのフレームレート、というなかなか普段見ない数字なので判断が難しい
もっとも、「既に販売しているプロセッサー」に比べて、IPで提供されるプロセッサーの効率が数倍では商売にならない。そのIPを購入して新しいチップを自分で作るとなると数年の期間が必要であり、その間により性能を上げたプロセッサーが市販されるであろうことは明白だからだ。
ただTensilicaはここで性能を上げる方向ではなく、効率を上げる方向に舵を切った。2021年に発表されたのが、現在も提供されるNNA110である。

このスライドには“NNE110”とあるが、現在はNNA110という名称で提供されている
構成そのものはNNEそのものであるが、MAC数は32~128と、3つ前の画像で示した256~2048から大幅減となっており、またPooling/Vector Processing Unitが省かれているのがわかる。PoolingはおそらくTensilica DSPの側で処理であり、またVector Processing Unitはその必要がないと判断されたためだろう。
どうしてか? というと、TensilicaはAIの用途を“Always On Processing”向けに割り切ったためだ。

つまり、AIの用途をインテルのGNAやPerceiveのERGOなどと同じ利用法に向けたものである
同社はすでにVision DSPやAudio DSPを幅広く展開して供給しており、それこそ画面付きのスマートスピーカーなどに広範に採用されている。こうしたすでにあるアプリケーションに、今回のNNA110を追加するだけで、性能を向上させつつ大幅に消費電力を減らせる)というわけだ。

これはノイズ削減の機能を、HiFi 5 DSP単体で実現した場合とNNA100を併用した場合の比較。ちなみにレイテンシーも3.7倍の削減になった、としている
ユーザーとしても、すでにTensilicaのIPを使ってアプリケーションを構築しているのであれば、そこにNNA110を追加するのはそう難しくない。いわば抱き合わせ商法を狙って展開されているのがNNA110というわけだ。Tensilicaのユーザーは多いので、そうしたユーザーを狙っての商売だけに、確実に市場が狙えそうではある。なかなか賢いビジネスだと思う。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























