



ロードマップでわかる!当世プロセッサー事情 第665回
Windowsの顔認証などで利用されているインテルの推論向けコプロセッサー「GNA」 AIプロセッサーの昨今
2022年05月02日 12時00分更新

久々にAIプロセッサーの話だ。今回はIntel GNA(Gaussian mixture model and Neural network Accelerator)の詳細を説明する。今年4月に開催されたLinley Spring Processor Forum 2022で突如インテルはGNAの詳細を説明したからだ。
GNAそのものはIce Lakeの世代で搭載されたという話を連載525回で触れている。このGNA、最初に発表されたのはICASSP 2017なのだが、実はこの際の発表はポスター(論文をベースに発表するのではなく、要点をまとめた物を1枚のポスターにまとめて張り出す)であって、内容もあまり深い話は掲載されていない。

インテルが発表したポスター
この時点で発表された内容をもう少し細かく説明すると、2017年時点で利用されているニューラルネットワークの中では、さまざまな特殊処理が利用されるケースが多いとされていた。具体的にはレイヤーモデル(それぞれの層を構成)では以下のものが使用される。
- affine(アフィン変換)
- diagonal affine(斜交アフィン変換)
- Gaussian mixture model(混合ガウスモデル)
- recurrent(循環)
- convolutional1D(一次元畳み込み)
- transpose(転置行列)
- Interleave/Deinterleave(インターリーブ化/インターリーブ解除)
アクティブファンクションとして以下のものが使われるケースが多い。
- PLW(PieceWise Linear:区分線形関数)
ところが通常のALUやFPUではこれを短いサイクルで実行できる機能はないので、これらのアルゴリズムをプログラムで処理する必要があり、これが非常に時間がかかる。
そこで、こうした処理を専用に受け持つがGNAとなる。構造は下の画像のとおりで、各層の特徴をレイヤー・ディスクリプターに記述しておき、GNAはこれらと必要なデータ、パラメーターを読み込んで、結果を再びメモリーに返すという、典型的なアクセラレーター的な動作を行なう仕組みだ。
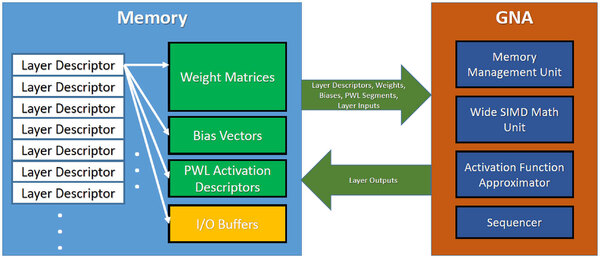
GNAの構造。レイヤー・ディスクリプションやウエイト、バイアスなどを格納するために専用のSRAMが必要となる
使い方もおもしろい。GNAはIntel Deep Learning SDK Deployment ToolやDeep Learning SDK Inference Engineといったツール経由で利用する以外に、GNA native libraryで利用できるとしているのだが、そのGNA native libraryというのが下の画像だ。

こともあろうにIntel Quarkである。おそらくSIMDエンジンとは別に、制御用にQuarkが搭載されていたのだと思うが、なにもQuarkでなくても……。当時手頃なCPUが他になかったのかもしれないが、それにしてもQuarkとは……
久しぶりに黒歴史記事を書きたくなるIntel Quarkが使われており、この上で動くRTOS(リアルタイムOS)向けのAPIと、それとは別にSIMDエンジンを直接叩けるミドルウェアAPIが用意されていたそうで、普通のアプリケーションはこのGNAxxxx()を呼び出して使う形になっていたと思われる。
ポスターでは、このGNAを利用した際の効果として、ビデオ映像にリアルタイムで字幕を付ける処理について、GNAを併用するとCPU負荷が半分になるとしていた。
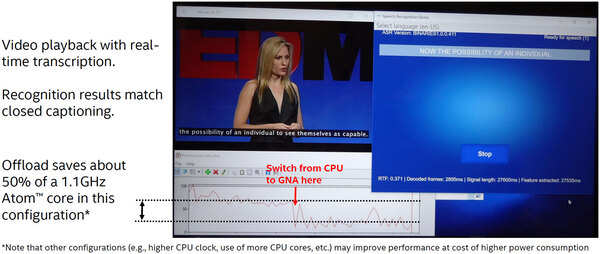
1.1GHzのAtomで100%だった負荷が50%になったという話なので、そもそもそれほど負荷が高くないという考え方もできる
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ















&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")












ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












