




HW 2.5から性能が21倍向上
肝となるのがNNA(Neural Network Accelerator)であるが、2つのNNAが独立して配される。NNAの中枢は96×96のMACユニットで、これが単体で36.8TOPSの演算性能を持つ。このMACユニットは周囲に配された32MBのSRAMとだけデータ交換することで、効率よく計算できるようになっている。
もっともこれに関しては2019年7月にハンガリーのAIMotiveがFSDの分析をしており、それほど効率が良くないとしている。下の画像を見ると、SRAMセルからMACユニットに配線が集中しており、実際にはここがボトルネックになってしまいやすく、MACユニットの効率はかなり低いのではないか? と推察している。

2つのNNAユニットの中央上部にMACユニットが配され、左右と中央下部はSRAM領域になっている
AIMotiveによれば、MACユニットとSRAMセルを混在させるような構成にすれば、90%以上の効率を実現することも可能とするが、ただし設計が複雑化する関係で、設計完了が半年~1年程度伸びることになる。
Teslaはこの設計期間が延びることを嫌って、不効率を覚悟のうえであえて単純な構成でFSDチップを設計したのではないか? というものだ。
Teslaクラスの資金力があれば、例えばHW3.0はこの単純なFSDチップで実現しておいて、これとは別により最適化を進めたチップを並行して開発することも不可能ではないだろうし、とりあえずNVIDIAから自前にチップ設計を切り替える第一歩としては、確実に動くものを作る方が重要だったという判断もあり得るわけで、その意味でもAIMotiveの分析は間違っていないように思える。
NNAの内部構造は以下の画像のとおり。MACアレイでひたすら乗算を行ない、その結果をSIMDエンジンで受けるという格好になっている。
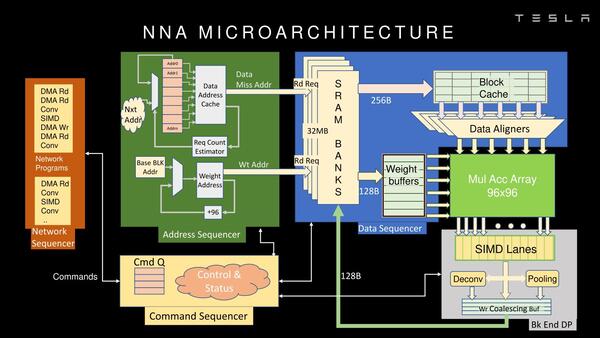
MAC出力はかならずSIMD Laneで受けてその結果をSRAM Bankに戻す形になる。SRAMと外部のデータ交換はDMA Read/Writeなどの命令で行なう
SIMDエンジンの内部構造が下の画像だ。SIMDといっても乗算そのものはMACユニットで済ませた後になるので、加算とアクティベーションが主な作業であり、それもあって対応する命令は多いものの、実装そのものは比較的簡単なようだ。
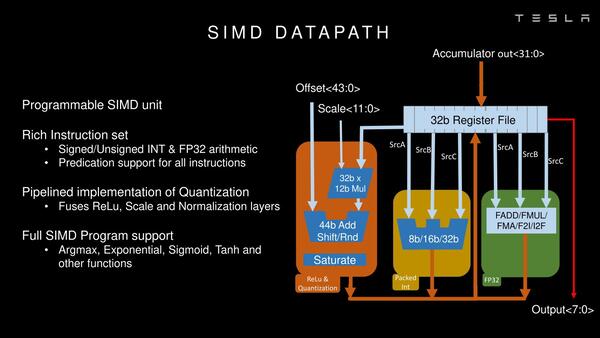
INT 8/16/32とFP32だけ、というのは2019年と言う時期を考えればわからなくもない。今だとFP16/BF16/FP8やInt 1/2/4もサポートに入りそうだ
さてこのFSD、HotChipsでの発表によれば従来のHW 2.5と比較して21倍の性能向上を実現しているとする、消費電力の絶対値は25%増えているものの、性能/消費電力比は大幅に向上しているわけだ。
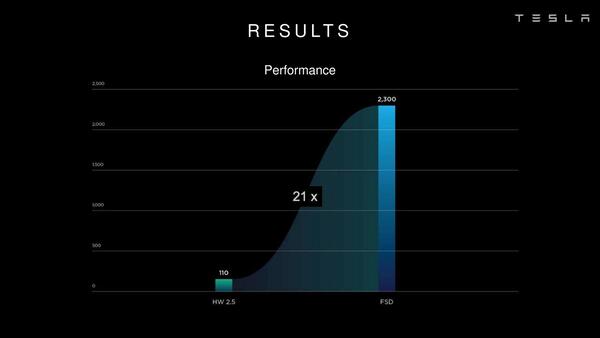
縦軸の数字の意味は処理フレームレートだそうで、HW 2.5では110fpsでの処理が可能なタスクが、FSDを使うと2300fpsで実行できるという。具体的にどんなタスクか? というのは不明だ
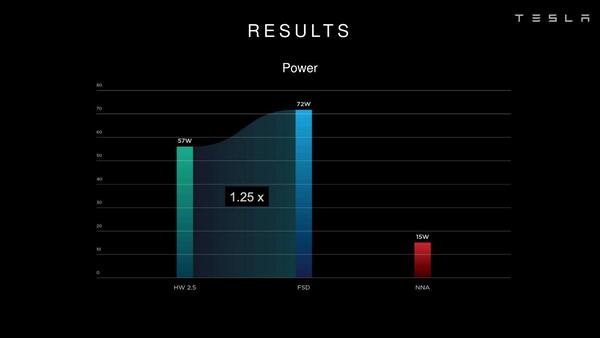
消費電力の絶対値は25%増えている。FSDをフルに使うと72Wと1.25倍に増えるが、このうちNNAは15Wしか使っていないとする
またコストは2割削減できたとしている。ちなみにNVIDIAのDrive Xavierと比較した場合、6.9倍の性能になるとのこと。
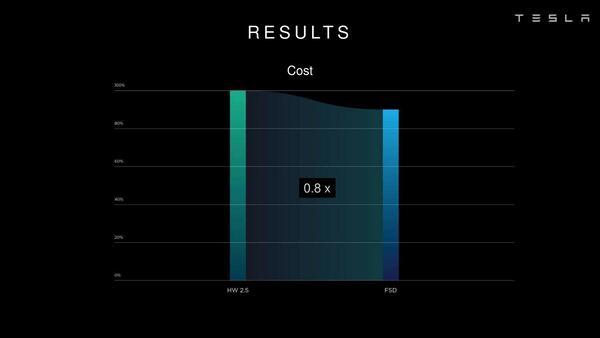
コストを2割削減。どのあたりがこのコストダウンに貢献したのか? はよくわからない

NVIDIAのDrive Xavierとの比較。ただこの144TOPSという数字はLockstep動作を無視した場合の話で、実際はこの半分という気もするし、先のAIMotiveの分析が正しければ実効性能差はさらに縮まりそうではある
TeslaはいつまでこのHW 3.0、つまり現バージョンのFSDを使い続けるつもりなのかはよくわらない。あるいはそろそろ内部的にはHW 3.5が登場しつつあるのかもしれない。なんにせよ、レベル2の自動運転を実行し、レベル3にトライするためにはこの程度の演算処理性能が必要、という1つの目安になることは間違いない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ


















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")




































