




Dojo Nodeを縦横に354個集積したD1ダイ
ダイサイズは645mm2とかなりの大きさ
ここからはコンピュートタイルの中身をもう少し説明したい。コンピュートタイルの根幹をなすのは、4-wayのスーパースカラーなコアである。独自命令セットであり、RISC-Vをカスタマイズとかそういうわけでもない。
DojoはTeslaのみが使うシステムなので、別にRISC-Vでなくても良いということだろう。このコアの特徴であるが、以下のような独特な構成である。
- フェッチは32Bytes/サイクルで、最大8命令のフェッチが可能。
- デコードは8-wideで、2スレッド/サイクルの処理が可能(つまり4-way SMTではあるが、1サイクルあたり2スレッド分しか命令は供給されない)
- ALU×2/AGU×2の4-way SMT構成。ただしフェッチバッファやALUのレジスターファイルなどはスレッドの数だけ用意される。
- FPUは搭載しない(というか、そもそもデータ型がBF16/CFP8という時点で、ALUがなくFPUのみというべきなのだろうか?)が、ベクトルというかSIMDエンジンは搭載される。こちらは2-wideで、64Bytes幅である。ここで最大8×8×4の行列乗算が可能。
- 仮想記憶はなし。メモリー保護機能も最小限。スレッド間でのリソース共有(共有メモリーなど)はソフトウェアで制御する。
- 通常アプリケーションスレッドが1~2個と、コミュニケーションスレッドが1~2個走る。
このパイプラインに、1.25MBのSRAMが割り当てられる。こちらは図からもわかるように命令とデータの両方を格納する形であるが、キャッシュというよりはスクラッチパッドという方が正確だろう。
このSRAMはロード400Gbps、ストア270Gbpsの帯域を持っており、またベクトルレジスターにデータを格納するにあたって、並び替えを行なうGather Engineを実装している。
これは例えば行列乗算では行と列を入れ替えるような操作が必要になるこが多く、これをソフトウェアでなくハードウェアで行なうことで効率化を図るためと考えられる。
逆にキャッシュにあたるものは存在しない。むしろキャッシュを使わなくても、4-wayスレッドで命令やデータのロード時間を遮蔽できるから、無理にキャッシュを入れて制御を複雑にする必要はない、という判断かと思われる。
このCPUパイプライン+1.25MB SRAMをDojo Nodeと呼ぶが、実際には複数のノードが2次元構造でつながっている。この接続を担うのがNOCルーターで、東西南北にそれぞれ128Bytes/サイクル(実際は送受信各64Bytes/サイクルと思われる)で接続可能であり、またNOCルーターとSRAMの間もそれぞれ64Bytes/サイクルで接続される。
このNOCルーターは東西南北にある別のNOCルーターとの間で8パケット/サイクルの転送が可能であり、また各々のルーターはSRAMに対して直接DMAで転送を行なえるので、CPUパイプラインの側に負荷をかけずに転送可能となっている。
ちなみにCPUパイプラインの命令セットはこんな感じ。確かにあまり一般的な感じはしないし、RISC-Vにするメリットも少なそうだ。
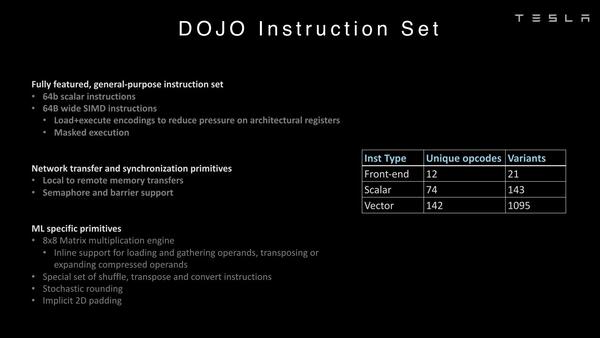
Front-endというのはおそらくルーターに対する命令で、転送と同期がメインであろう。Variantsの数がベクトルで妙に多いのは、ギャザリングへの対応もあるのだと思われる
さてこのDojo Nodeを縦横に354個集積したのがD1ダイとなる。TSMCのN7ながら動作周波数は2GHzとやや低めで、Low Power Cell Libraryで構築されている可能性もある。

20行×18列で360個分の領域だが、6ヵ所は他の用途に使われているようで、トータル354個となる
性能はBF16/CFP8では362TFlopsと、ノードの数のわりに少し高めだが、これはベクトルユニットを利用した場合の数字と思われる。ベクトルを使えないFP32では22TFlopsとやや低めに推移している。
このD1ダイ1つで440MB(正確には442.5MB)のSRAMを実装しているが、それもあってダイサイズは645mm2とかなりの大きさ。これを25個集積し、さらにその外側にI/O用のダイを40個(つまり一辺あたり10個:1つのD1ダイあたり2個接続される計算である)配したのがDojoタイルである。つまり1つのタイルには8850個のノードが含まれ、11GBのSRAMが内蔵される形だ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ


















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





































