
最高速を2倍に引き上げながら
消費電力は据え置き
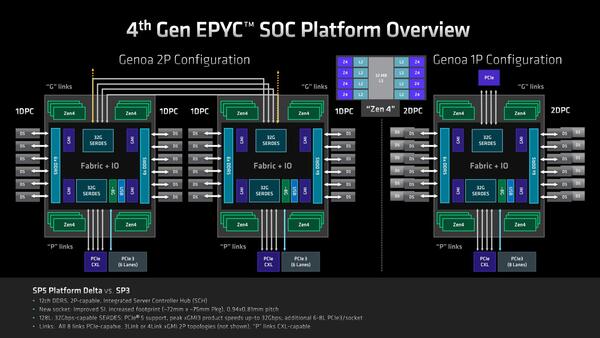
ではEPYCをEPYCたらしめている部分は? というと、IODを含めたSoC全体、ということになる。IODは上の画像で示すように12chのCCD接続用インフィニティー・ファブリックのI/FとメモリーコントローラーとPCIe/CXLなどのI/O I/Fを統合したチップである。
まずメモリーコントローラーであるが、DDR5を12ch搭載、最大で6TBものメモリーを利用可能となっている。

サポートされるのはRDIMMおよび3DS RDIMMのみというのは当然のこと。またDDR5の場合は内部が32bit×2ということもあり、2つの32bitをまとめてECC 8bitが付く方式と、それぞれの32bitごとに8bitのECCが付く方式の両方が存在しており、EPYC 9004はどちらにも対応する
もっとも、6TBの構成にする場合、12chのDIMMスロットにそれぞれ2枚づつのDIMM(それも2×8Rank 3DS-RDIMMで、16Gbit×4構成)を装着する必要がある。そもそもDDR5では、1chのメモリーバスに2枚のDIMMを挿す場合には速度やRankの制約が非常に多い。それもあって、EPYC 9004シリーズの場合は、1ソケットサーバーは24本のDIMMスロットを持つが、2ソケットサーバーはそれぞれ12本のDIMMスロットを持つ構成がデフォルトとされている。
この2つのソケット間のI/Fの話は後述する
実際AMDのEPYC 9004シリーズ向けのリファレンスボードであるTitaniteの場合、DIMMスロットはソケットあたり12本になっている。
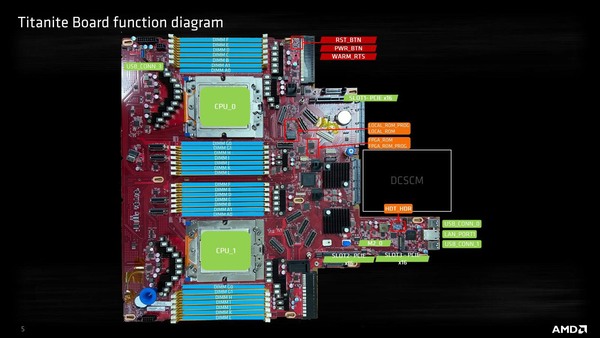
しっかり数えると28本のスロットがあるのだが、A0/G0に関してはパターンは来ているもののDIMMソケットは実装されていないのがわかる。おそらく2 DIMM/chの検証用に、一番ソケットに近いところだけ2本分のパターンが用意され、ただし実際には使わないという格好かと思われる
ちなみに速度はDDR5-4800どまりである。コンシューマー向けはともかくサーバー向けのRDIMMや3DS RDIMMは今のところDDR5-4800どまりであり、少なくともGenoa世代ではこれで問題ないと思われる。ちなみにこのメモリーコントローラー、NUMAの分割に合わせて4つまで分割してそれぞれ独立にアクセスすることも可能である。

NUMAノード2つなら6chのNPS2が、NUMAノード4つなら3chのNPS4がそれぞれ利用できる。このNPS2/4の状態だと、自身の属するNUMAノード以外からのメモリーアクセスは不可能になる
少しおもしろいのがこのメモリーコントローラーの性能に関する部分だ。DDR4のMilanとDDR5のGenoaなので当然帯域は倍以上異なるわけだが、それよりも特徴的なのはSingle Rank Efficiencyの部分である。
当然ながらサーバーである以上、Multi-Rank Interleaveは前提になっており、2 Rankのメモリーと1 Rankのメモリーでは性能が大きく異なる。実際Milanでは25~30%もの性能低下があるのだが、これをGenoaでは10%未満(実際には5~6%)で抑えたというのは、特にメモリーのコストを抑えたシステム(同容量では2 Rankのメモリーの方が高い)での性能低下を最小限に抑えられるという点で効果的である。

DDR5自体がSingle RankとDual Rankであまり性能差がないような工夫をされていることもここに貢献している
また、DDR4→DDR5では帯域こそ増えるもののレイテンシーも増えることそのものは避けられないのだが、Genoaではこのあたりをずいぶん工夫しており、速度が上がりつつもDRAMアクセスのレイテンシーそのものは13nsしか増えない(このうち10nsはDDR4→DDR5に起因する)あたりは、Zen 4コアが内部の2次キャッシュの大容量化などでよりメモリーアクセス頻度が減ったことと相まって、実質的にさほどGenoaと変わらないレイテンシーで帯域だけ2倍以上になったことになる。
次が2ソケット用のインフィニティ・ファブリック・レーンの話である。Genoaに搭載されたIODでは、このソケット間の接続にx3ないしx4のインフィニティ・ファブリックを利用できる。このファブリックのPHYはPCI Expressと共用というのはGenoaまでと同じである。
x3とx4のどちらを使うのかはアプリケーション次第であって、例えばアクセラレーターを大量に利用するような構成ではソケット間接続はx3にして、余った32レーンでアクセラレーターを2枚余分に接続できるし、Computationなどの用途であればx4接続することでプロセッサー同士の接続がより広帯域になるわけだ。
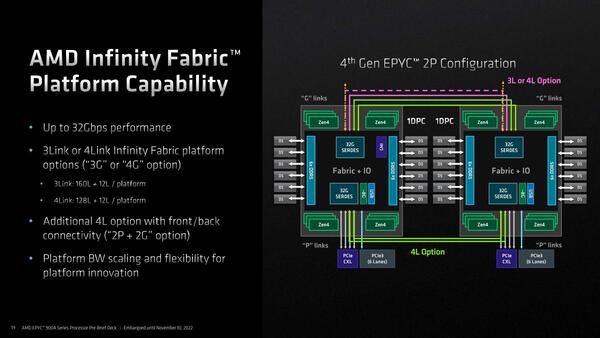
x4の場合、上側と下側の32G SerDesから2対づつを使って相互接続する形になる。一方x3の場合、上側の32G SerDesでx3の接続を行ない、下側は全部PCIeやCXLで利用する格好となる
なおこのインフィニティ・ファブリックの最高速は36Gbpsである。SerDesをPCI Express/CXLと共用する関係で、PCI Express/CXLとしての動作時には32Gbpsになるが、インフィニティ・ファブリックとしての利用時は36Gbpsになり、それでいながら転送時の消費電力は2pJ/bitを下回るとしている。
この2pJ/bitというのは、Genoaまでのインフィニティ・ファブリックと同じ数字であり、つまり最高速を2倍に引き上げながら消費電力そのものは据え置きにできたとされている。ちなみにSerDesはPCI Express/CXL以外にSATA、さらにイーサネットとしても利用できるという構成は以前のままである。

といっても動的に変更できるわけでもないので、実際にはマザーボードの構成で決まるわけだが、マザーボードの設計の柔軟性(というかI/O種別の選択の柔軟性)が大きいのは間違いない
性能に関してはいくつかスライドが出ているが、これはAMDのウェブサイトで示されているものと大差ないし、なんなら動画でデモが公開されているので今回は割愛する。
前回の記事の最後でも書いたが、Genoaの本当の敵は第3世代Xeon Scalableではなく、間もなく登場するはず(出ると良いなぁ)のSapphire Rapidsベースとなる第4世代Xeon Scalableである。
現時点ではまだその第4世代Xeon Scalableの評価ができない以上、これがそろってからが評価の本番だと思うからだ。というわけで、Genoaについてはこのあたりで終わるが、最後にBergamoについて語ろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ













