
RNDA 3アーキテクチャーと、これを最初に実装したNavi 31、そのNavi 31を搭載したRadeon RX 7900 XTXおよびRadeon RX 7900 XTに関して第一報と 第二報はKTU氏によってすでにASCII.jpに記事が掲載されている。RDNA 3を理解するための基本となるポイントはこの記事で説明済みなので、もう少し細かいところを補足の形で説明しよう。

12月13日発売予定のRadeon RX 7900 XTXとRadeon RX 7900 XT
1つのGCDと複数のMCDに分割された
RDNA 3のチップレット構造
連載653回で、RDNA 3のチップレット構造を、「複数のGCDと1つのMCD」ではないか? と考察したが、見事にハズレで「1つのGCDと複数のMCD」という、真逆の分割方法だった。
一応言い訳を書いておけば、GCDの肥大化にともないダイサイズが大型化することへの対処として、GCDを分割してタイル的に接続するのが効果的だろう、というのが連載653回で予想した理由であった。
ただ結果から言えば、GCDは300mm2と、Radeon RX 6950 XTに使われていたNavi 21(520mm2)よりも大幅にダイサイズを縮小できており、キャッシュを外に追い出すだけで十分効果があったことになる。
ちなみにSam Naffziger氏(SVP&Corporate Fellow, AMD Product Technology Group)によれば、Navi 31の設計にあたってGCDを複数ダイに分割することも検討したそうなのだが、「配線が多すぎて収まりきらない」ということで、少なくともこの世代では採用しないことにしたそうだ。
チップレット構成を取った理由というのが下の画像だ。左は昨今のプロセスの微細化と、エリアサイズの関係を示したものだ。
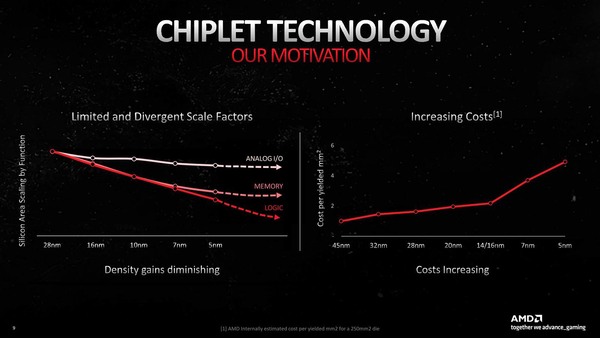
「微細化してもSRAM容量が増えない」問題、一番クリティカルなのは汎用CPUよりもむしろAI向けプロセッサーである
28nmあたりを起点にして、まずアナログ回路は微細化してもエリアサイズがあまり縮小しない。これは当然で、例えばキャパシターなどは原則として容量が面積に比例するから、必要な容量に応じて面積がほぼ一意に決まってしまう。
これに比べるとロジック回路とメモリー(SRAM)は微細化に合わせて面積も減っていくが、5nm世代あたりからメモリーはほとんど微細化の効果がなくなってきた。この結果として、微細化してもメリットが得られなくなっている。
その一方でウェハーの製造コストはうなぎのぼりである。14nmの場合、おおむねウェハー1枚6000ドルが、7nm世代で1万ドル、5nm世代では1万7000ドルほどになるとされる(TSMCの場合)。
となると、SRAMを5nmで製造すると面積あたりの容量が変わらずコストだけが1.7倍に跳ね上がる計算だ。こうなると、ロジックは5nmに微細化したプロセスで、SRAM(=キャッシュ)は7nmあたりで製造するのが一番効率が良いことになる。
もっと言えば、キャッシュだけでなくVector Register Fileの類も7nmで作れればそのほうが安く上がることになるが、これを別チップにすると強烈に配線が複雑になりすぎるし、レイテンシーが大きすぎる。比較的分離しやすい3次キャッシュ相当のインフィニティ・キャッシュだけを別チップにする、というのが一番合理的である。
ついでに言えば、メモリーコントローラーを別チップに追い出すのも意外に効果的だ。メモリーコントローラーは、実際にメモリーバスへの信号を制御するコントローラー部に加え、GDDR6用の信号を送受信するPHYが必要になる。
このPHYはモロにアナログ回路なので、左のグラフで示すように微細化の恩恵をまるで受けない。であれば、相対的に大きめのプロセスで製造した方が効率が良い。
下の画像は、連載587回で利用したNavi 21のダイ写真の流用だが、(やや見えづらいが)上下の枠で囲った部分がGDDR6のI/F部である。

これでも7nmのVega(Vega 21)に比べればだいぶ無駄が減った
このI/F部の長さがかなりあるため、結果としてNavi 21は上の画像で言えば右方向に未使用領域(青で囲った部分)が発生してしまっている。これはかなりの幅のGDDR6 PHYを内蔵したがゆえの弊害であって、PHYを外に出してしまえばこの無駄が省けることになる。
実際下の画像にあるNavi 31の構造を見ると、MCDにはGDDR6のPHYが2列構造で並んでいるのがわかる。
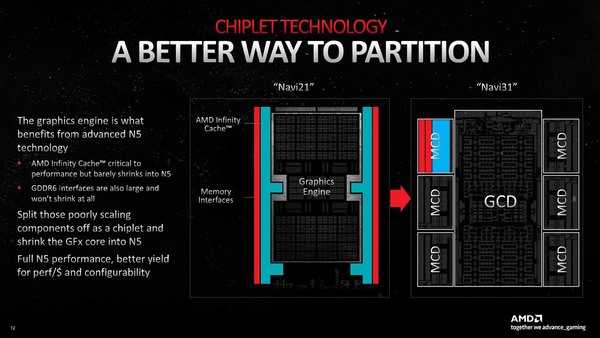
Navi 21とNavi 31の違い。Navi 21でPHYを2列配置にすると横幅が増えるので、トータルとしてどちらが無駄な面積が多くなるか微妙なところ。インフィニティ・キャッシュの分も加味すると、現状の構成が一番無駄が少なかったのだろうと想像される
おのおの32bit分と思われるが、これによりトータルで384bit分とNavi 21の1.5倍のバス幅を実現しつつ、高さはNavi 21よりもむしろ少なく抑え込めたわけで、これはNavi 31のGCDのサイズを抑え込むのに大きな効果があったと考えられる。
AMDによれば、Navi 31では無駄な面積を2割削減できたとしている。これがGCDを分割せずに、MCDを分割した大きな理由ということになる。
なお、MCDをTSMC N7でなくN6で製造した理由について、Naffziger氏から「もう新規設計でN7を使うことはない。N6で製造したのはリーズナブルだった」と返答があった。
TSMCとしても、ArF液浸+マルチパターニングのN7より、EUV(極端紫外線)を使ったN6に移行したい(早くEUVの減価償却をしたい)のは理解ができるし、AMDとしても製造コストはともかく初期コストを抑えられる(マスクコストが大幅に削減できる)EUVを使えるN6に移行するのは必然だったと思われる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ













