




キャッシュ容量の大型化とメモリーの高速化などで性能が向上
2つ目がキャッシュ容量の大型化とメモリーの高速化である。Raptor Lakeでは 以下の2次キャッシュを搭載しており、2次キャッシュだけで32MBもの大容量キャッシュになった。
- P-Coreあたり2MB
- E-Core Cluster(E-Core×4)あたり4MB(共有)
ちなみにAlder Lakeでは、以下のとおり合計14MBでしかない。
- P-Coreあたり1.25MB
- E-Core Clusterあたり2MB(共有)
3次キャッシュは引き続き、以下のとおりであるが、Raptor LakeではP-Core×8+E-Core Cluster×4になった関係で、3次キャッシュの合計は36MBに増量された(Alder Lakeは30MB)。
- P-Coreあたり3MB
- E-Core Clusterあたり3MB
ただ2次キャッシュと3次キャッシュの総容量がほとんど変わらなくなった関係で、3次キャッシュの扱い方を少し考えたらしい。
今回新たにDynamic INI(Inclusive/Non Inclusive)方式が採用されることになった。動的に2次/3次キャッシュのInclusive/Non-Inclusiveを切り替えられる、というものだ。Alder LakeはNon-Inclusive一択だったが、このあたりに若干の手が入った模様だ。
もう1つの違いは、メモリーである。1DPC(DIMM per Channel)なら最大5600MHz、2DPCでも4400MHzでの駆動が定格で可能になった。

ただInclusiveを利用するメリットが今ひとつ見えてこないのだが。3次キャッシュの利用頻度が低い時などは、Non-Inclusiveよりもレイテンシーを減らせるのはメリットかもしれない
Alder Lakeでは定格ではそれぞれ4800MHz、4000MHzだったから、これも性能に寄与することになる(効果は1~2%のオーダーであるが)。そしてメモリーの高速化に対応するため、内部のファブリックも最大5GHzまで動作周波数を引き上げられるように変更された。
最後のファクターがスレッドである。これはコアそのものではなく、Thread Directorの変更によるものだ。

この改良型Thread DirectorをきちんとOSでハンドリングできるのは、Windows 11では22H2になる
大きな違いは、Thread Classの管理に、新たに機械学習を利用した仕組み(Perceptronベースという話であったが、詳細は公開されていない)を利用することで、よりE-Coreを積極的に利用できるようになった、というものだ。
もともとのThread Directorの仕組みは、システムの負荷が低い時にはP-Coreを休止させてE-Coreを活用することで消費電力を減らし、一方でシステムの負荷が上がった時にはP-Coreに切り替えて処理性能の向上(というか処理時間の短縮)を図るというものだった。
この原則はRaptor Lakeも変わらないが、これに加えて「さらに負荷が高いときは、P-CoreだけでなくE-Coreもフルにブン回す」というのがRaptor Lakeである。
下の画像はまだ負荷がそれほど高くないケースで、E-Coreは煩雑に負荷が0になる(P-Coreはかなり上に張り付いている)が、さらに高くなるとE-Coreも常時100%に張り付く格好になる。
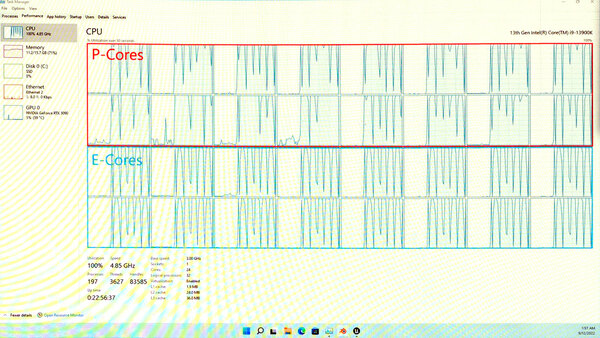
ここでもP-CoreとE-Coreが一緒に100%になったり0%に落ちたりと、かなり連動しているのがわかる
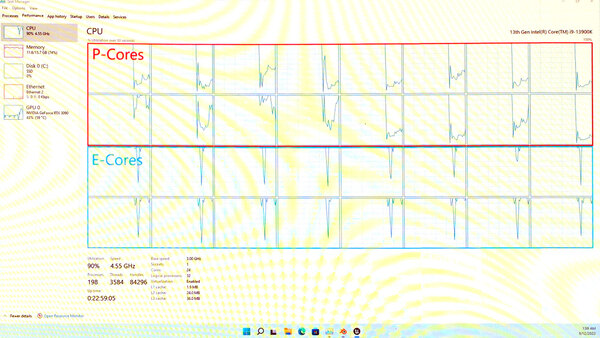
P-Coreの方が先に処理が終わるが、E-Coreは処理が終わり切ってないためか、逆にE-Coreが100%に張り付いたままになっている
要するにE-Coreも積極的に利用するようにしたのがRaptor Lakeの変更点で、これによりContents Creationなどの処理では30%以上の性能向上が見られる、というのがインテルの説明である。
説明会では他にもいくつか性能に関するスライドが出てきたが、間もなく実機でのベンチマーク結果も公開されるだろうことと、比較対象がZen 3ベースのRyzen 9 5950Xであり(まだRyzen 9 7950Xの発売前だったから当然だ)、すでにRyzen 9 7950Xが発売されている現時点では今ひとつおもしろくないことを考えて、今回は割愛する。
このあたりはKTU氏のレポートをお待ちいただきたい。全体として言えば、Zen 4とはまた別の方法で「内部構造は大きく変えずに実効性能を引き上げた」のがRaptor Lakeということになる。さて、Zen 4 vs Raptor Lake、どんな結果になるのだろうか?
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ














の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



















