



ビジネス/開発/運用のサイロ化を防ぐ、イノベーションと信頼性を両立させる
SREとは? Google Cloudがその基本を説明、JCBも導入/実践経験を紹介
2022年08月30日 07時00分更新

「100%の信頼性目標は誤り」イノベーションと信頼性を両立させるエラーバジェット
続いて山口氏は、SREのさまざまなプラクティスから「最も重要な概念」だという「エラーバジェット」について説明した。エラーバジェットとは、個々のサービスの信頼性がどの程度損なわれても許容できるのかを示す指標である(「非信頼性予算」とも訳される)。
なぜエラーバジェットという概念が重要なのか。それは「信頼性100%」という目標が、現実には達成不可能な誤った目標だからだ。より高い信頼性を求めれば求めるほど、実現に必要なコストや人的リソースが膨れ上がり、一方で迅速な新機能のリリースやスケールは困難になってしまうため、サービスのイノベーションが阻害される。ここで必要なのは“完全な信頼性(100%)”ではなく、信頼性とイノベーションの“バランス”だ。そもそもグーグルのベンジャミン・トレイナー・スロス氏がでSREを提唱し、SREチームを立ち上げたのも、そうした気づきがきっかけになったという。

グーグルのベンジャミン・トレイナー・スロス(Benjamin Treynor Sloss)氏は「100%の信頼性という目標は誤り」という気づきからSREを提唱した
それでは「100%」の代わりとなる信頼性目標をどう設定するのか。山口氏は「ユーザーが許容できる障害の長さ、エラーの量を目標値として選択する」と説明する。もちろんユーザーの許容範囲=目標値はサービスごとに異なる。
「(障害発生時に)プロジェクトマネジメントチームが気にするのは『ユーザーが障害に気づいているかどうか』ということ。ただし、実際にはユーザーが障害に気づいていても問題はなくて、それが『ユーザーが許容できないほどの障害にはなっていない』ことが重要だ」(山口氏)
エラーバジェットの「バジェット(予算)」という言葉には、「その範囲内(予算内)であれば自由に使い道を決めてよい」という含意がある。ビジネス/開発/運用の各チームが合意したエラーバジェット=許容範囲の中であれば、たとえば新しい機能のリリース、これまでとは違うサービスのデプロイ方法の実験といった、エラー発生のリスクもある新しい変更にもチャレンジできる。山口氏は「これは非常に強力な概念」だと強調する。
「『ユーザーから見た信頼性』を測ることで、ビジネス目標をふまえた信頼性の合意を得る方法が手に入れられた。つまりユーザーが許容できる障害の量を見極めて、そこに至るまではエラーが発生しうるチャレンジを行ってもよい、許容量に近づいてしまったらシステムの安定性を優先する。開発チーム、運用チームに関係なく、エラーバジェットという指標に基づいてそうした判断が行えるようになった」(山口氏)

エラーバジェットは、開発チームと運用チームが共有する“貴重なリソース”。イノベーションと信頼性のバランスを実現できる
このエラーバジェットを具体的に規定するのが、“信頼性”を何で/どう測るかを定義する「SLI(サービスレベル指標)」と、ユーザーが快適に利用できる下限値である「SLO(サービスレベル目標)」だ。ごく簡単な例を挙げると、SLIは「サービスにアクセス可能な状態であること」、SLOは「1カ月あたり○分間」といった具合になる。ちなみに、クラウドサービスベンダーなどが提示する「SLA(サービスレベル合意)」は、顧客に対する対外的な目標値であり、通常はSLOよりもゆるく(より大きな許容幅で)設定される。
「適切なSLOの定義というのは非常に複雑なトピックだが、重要なポイントは『極力シンプルなSLOを設定することから始める』こと。そしてそのSLOに基づいて運用しながら、設定したSLOが厳しすぎるのかゆるすぎるのか、またそのSLIに基づく目標値でよいのか、そうしたことを定期的に振り返り、調整していく」(山口氏)
山口氏は「SLOはユーザーニーズに基づく目標値であるからこそ、ビジネスにも直結する」と述べたうえで、SLOがビジネス/開発/運用などすべての組織における合意を得るための“架け橋”として機能すること、それゆえにSLOを実現するためのSREも全組織間での合意を得るための取り組みとなると語った。

SLO(サービスレベル目標)は、SLI(サービスレベル指標)を満たすサービス提供が期間中にどれだけ実現されたかで計測される。ユーザーニーズに基づいて設定を行い、運用を続けながら定期的に調整していく
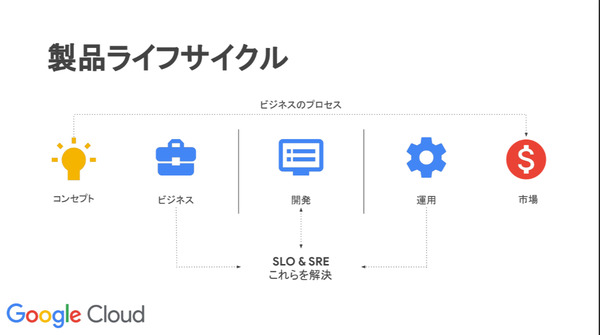
SLOとそれを実現するためのSREは、ビジネス/開発/運用など全組織の間での「合意事項」として機能する
本記事はアフィリエイトプログラムによる収益を得ている場合があります



